(See also: List of proteins in the human body)

The National Center for Biotechnology Information (NCBI) is part of the United States National Library of Medicine (NLM), a branch of the National Institutes of Health (NIH). It is approved and funded by the government of the United States. The NCBI is located in Bethesda, Maryland, and was founded in 1988 through legislation sponsored by US Congressman Claude Pepper.

A decision support system (DSS) is an information system that supports business or organizational decision-making activities. DSSs serve the management, operations and planning levels of an organization and help people make decisions about problems that may be rapidly changing and not easily specified in advance—i.e. unstructured and semi-structured decision problems. Decision support systems can be either fully computerized or human-powered, or a combination of both.

(See also: List of proteins in the human body)
The European Bioinformatics Institute (EMBL-EBI) is an intergovernmental organization (IGO) which, as part of the European Molecular Biology Laboratory (EMBL) family, focuses on research and services in bioinformatics. It is located on the Wellcome Genome Campus in Hinxton near Cambridge, and employs over 600 full-time equivalent (FTE) staff. Institute leaders such as Rolf Apweiler, Alex Bateman, Ewan Birney, and Guy Cochrane, an adviser on the National Genomics Data Center Scientific Advisory Board, serve as part of the international research network of the BIG Data Center at the Beijing Institute of Genomics.

Amos Bairoch is a Swiss bioinformatician and Professor of Bioinformatics at the Department of Human Protein Sciences of the University of Geneva where he leads the CALIPHO group at the Swiss Institute of Bioinformatics (SIB) combining bioinformatics, curation, and experimental efforts to functionally characterize human proteins.
(See also: List of proteins in the human body)
Expasy is an online bioinformatics resource operated by the SIB Swiss Institute of Bioinformatics. It is an extensible and integrative portal which provides access to over 160 databases and software tools and supports a range of life science and clinical research areas, from genomics, proteomics and structural biology, to evolution and phylogeny, systems biology and medical chemistry. The individual resources are hosted in a decentralized way by different groups of the SIB Swiss Institute of Bioinformatics and partner institutions.
The Worldwide Protein Data Bank, wwPDB, is an organization that maintains the archive of macromolecular structure. Its mission is to maintain a single Protein Data Bank Archive of macromolecular structural data that is freely and publicly available to the global community.
The EM Data Bank or Electron Microscopy Data Bank (EMDB) collects 3D EM maps and associated experimental data determined using electron microscopy of biological specimens. It was established in 2002 at the MSD/PDBe group of the European Bioinformatics Institute (EBI), where the European site of the EMDataBank.org consortium is located. As of 2015, the resource contained over 2,600 entries with a mean resolution of 15Å.
Mouse Genome Informatics (MGI) is a free, online database and bioinformatics resource hosted by The Jackson Laboratory, with funding by the National Human Genome Research Institute (NHGRI), the National Cancer Institute (NCI), and the Eunice Kennedy Shriver National Institute of Child Health and Human Development (NICHD). MGI provides access to data on the genetics, genomics and biology of the laboratory mouse to facilitate the study of human health and disease. The database integrates multiple projects, with the two largest contributions coming from the Mouse Genome Database and Mouse Gene Expression Database (GXD). As of 2018, MGI contains data curated from over 230,000 publications.

Tyrosine aminotransferase is an enzyme present in the liver and catalyzes the conversion of tyrosine to 4-hydroxyphenylpyruvate.
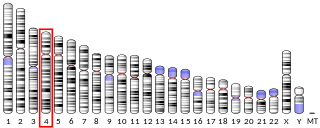
Latrophilin 3 is a protein that in humans is encoded by the ADGRL3 gene.
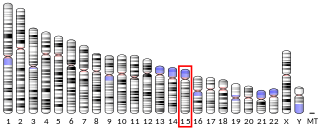
Myosin-Ie (Myo1e) is a protein that in humans is encoded by the MYO1E gene.

Eukaryotic translation initiation factor 4E family member 3 is a protein that in humans is encoded by the EIF4E3 gene.

SEC24 family, member A is a protein that in humans is encoded by the SEC24A gene. The protein belongs to a protein family that are homologous to yeast Sec24. It is a component of coat protein II (COPII)-coated vesicles that mediate protein transport from the endoplasmic reticulum.

Participatory monitoring is the regular collection of measurements or other kinds of data (monitoring), usually of natural resources and biodiversity, undertaken by local residents of the monitored area, who rely on local natural resources and thus have more local knowledge of those resources. Those involved usually live in communities with considerable social cohesion, where they regularly cooperate on shared projects.
In natural language processing, linguistics, and neighboring fields, Linguistic Linked Open Data (LLOD) describes a method and an interdisciplinary community concerned with creating, sharing, and (re-)using language resources in accordance with Linked Data principles. The Linguistic Linked Open Data Cloud was conceived and is being maintained by the Open Linguistics Working Group (OWLG) of the Open Knowledge Foundation, but has been a point of focal activity for several W3C community groups, research projects, and infrastructure efforts since then.

CorCenCC or the National Corpus of Contemporary Welsh is a language resource for Welsh speakers, Welsh learners, Welsh language researchers, and anyone who is interested in the Welsh language. CorCenCC is a freely accessible collection of multiple language samples, gathered from real-life communication, and presented in the searchable online CorCenCC text corpus. The corpus is accompanied by an online teaching and learning toolkit – Y Tiwtiadur – which draws directly on the data from the corpus to provide resources for Welsh language learning at all ages and levels.