In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains data, and a reference to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that data access time is linear in respect to the number of nodes in the list. Because nodes are serially linked, accessing any node requires that the prior node be accessed beforehand. Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.
Bayesian inference is a method of statistical inference in which Bayes' theorem is used to calculate a probability of a hypothesis, given prior evidence, and update it as more information becomes available. Fundamentally, Bayesian inference uses a prior distribution to estimate posterior probabilities. Bayesian inference is an important technique in statistics, and especially in mathematical statistics. Bayesian updating is particularly important in the dynamic analysis of a sequence of data. Bayesian inference has found application in a wide range of activities, including science, engineering, philosophy, medicine, sport, and law. In the philosophy of decision theory, Bayesian inference is closely related to subjective probability, often called "Bayesian probability".

In computer science, the treap and the randomized binary search tree are two closely related forms of binary search tree data structures that maintain a dynamic set of ordered keys and allow binary searches among the keys. After any sequence of insertions and deletions of keys, the shape of the tree is a random variable with the same probability distribution as a random binary tree; in particular, with high probability its height is proportional to the logarithm of the number of keys, so that each search, insertion, or deletion operation takes logarithmic time to perform.
Bayesian statistics is a theory in the field of statistics based on the Bayesian interpretation of probability, where probability expresses a degree of belief in an event. The degree of belief may be based on prior knowledge about the event, such as the results of previous experiments, or on personal beliefs about the event. This differs from a number of other interpretations of probability, such as the frequentist interpretation, which views probability as the limit of the relative frequency of an event after many trials. More concretely, analysis in Bayesian methods codifies prior knowledge in the form of a prior distribution.
In statistics, exploratory data analysis (EDA) is an approach of analyzing data sets to summarize their main characteristics, often using statistical graphics and other data visualization methods. A statistical model can be used or not, but primarily EDA is for seeing what the data can tell beyond the formal modeling and thereby contrasts with traditional hypothesis testing, in which a model is supposed to be selected before the data is seen. Exploratory data analysis has been promoted by John Tukey since 1970 to encourage statisticians to explore the data, and possibly formulate hypotheses that could lead to new data collection and experiments. EDA is different from initial data analysis (IDA), which focuses more narrowly on checking assumptions required for model fitting and hypothesis testing, and handling missing values and making transformations of variables as needed. EDA encompasses IDA.

A digital object identifier (DOI) is a persistent identifier or handle used to uniquely identify various objects, standardized by the International Organization for Standardization (ISO). DOIs are an implementation of the Handle System; they also fit within the URI system. They are widely used to identify academic, professional, and government information, such as journal articles, research reports, data sets, and official publications.
The point location problem is a fundamental topic of computational geometry. It finds applications in areas that deal with processing geometrical data: computer graphics, geographic information systems (GIS), motion planning, and computer aided design (CAD).
In computing, a persistent data structure or not ephemeral data structure is a data structure that always preserves the previous version of itself when it is modified. Such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead always yield a new updated structure. The term was introduced in Driscoll, Sarnak, Sleator, and Tarjan's 1986 article.
A persistent world or persistent state world (PSW) is a virtual world which, by the definition given by Richard Bartle, "continues to exist and develop internally even when there are no people interacting with it". The first virtual worlds were text-based and often called MUDs, but the term is frequently used in relation to massively multiplayer online role-playing games (MMORPGs) and pervasive games. Examples of persistent worlds that exist in video games include Battle Dawn, EVE Online, and Realms of Trinity.
In data management, dynamic data or transactional data is information that is periodically updated, meaning it changes asynchronously over time as new information becomes available. The concept is important in data management, since the time scale of the data determines how it is processed and stored.
In clinical trials and other scientific studies, an interim analysis is an analysis of data that is conducted before data collection has been completed. Clinical trials are unusual in that enrollment of subjects is a continual process staggered in time. If a treatment can be proven to be clearly beneficial or harmful compared to the concurrent control, or to be obviously futile, based on a pre-defined analysis of an incomplete data set while the study is on-going, the investigators may stop the study early.
In computer science, a purely functional data structure is a data structure that can be directly implemented in a purely functional language. The main difference between an arbitrary data structure and a purely functional one is that the latter is (strongly) immutable. This restriction ensures the data structure possesses the advantages of immutable objects: (full) persistency, quick copy of objects, and thread safety. Efficient purely functional data structures may require the use of lazy evaluation and memoization.
In statistics, a generalized estimating equation (GEE) is used to estimate the parameters of a generalized linear model with a possible unmeasured correlation between observations from different timepoints.
In applied mathematics, topological data analysis (TDA) is an approach to the analysis of datasets using techniques from topology. Extraction of information from datasets that are high-dimensional, incomplete and noisy is generally challenging. TDA provides a general framework to analyze such data in a manner that is insensitive to the particular metric chosen and provides dimensionality reduction and robustness to noise. Beyond this, it inherits functoriality, a fundamental concept of modern mathematics, from its topological nature, which allows it to adapt to new mathematical tools.

Syntaxins are a family of membrane integrated Q-SNARE proteins participating in exocytosis.
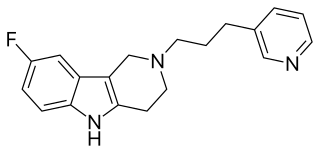
Gevotroline (WY-47,384) is an atypical antipsychotic with a tricyclic structure which was under development for the treatment of schizophrenia by Wyeth-Ayerst. It acts as a balanced, modest affinity D2 and 5-HT2 receptor antagonist and also possesses high affinity for the sigma receptor. It was well tolerated and showed efficacy in phase II clinical trials but was never marketed.

Levofenfluramine (INN), or (−)-3-trifluoromethyl-N-ethylamphetamine, also known as (−)-fenfluramine or (R)-fenfluramine, is a drug of the amphetamine family that, itself (i.e., in enantiopure form), was never marketed alone. It is the levorotatory enantiomer of fenfluramine, the racemic form of the compound, whereas the dextrorotatory enantiomer is dexfenfluramine. Both fenfluramine and dexfenfluramine are anorectic agents that have been used clinically in the treatment of obesity (and hence, levofenfluramine has been as well since it is a component of fenfluramine). However, they have since been discontinued due to reports of causing cardiovascular conditions such as valvular heart disease and pulmonary hypertension, adverse effects that are likely to be caused by excessive stimulation of 5-HT2B receptors expressed on heart valves.

In computer science, finger search trees are a type of binary search tree that keeps pointers to interior nodes, called fingers. The fingers speed up searches, insertions, and deletions for elements close to the fingers, giving amortized O(log n) lookups, and amortized O(1) insertions and deletions. It should not be confused with a finger tree nor a splay tree, although both can be used to implement finger search trees.

The growth curve model in statistics is a specific multivariate linear model, also known as GMANOVA. It generalizes MANOVA by allowing post-matrices, as seen in the definition.
Yihui Xie (谢益辉) is a Chinese software developer who previously worked for Posit PBC. He is the principal author of the open-source software package Knitr for data analysis in the R programming language, and has also written the book Dynamic Documents with R and knitr.