
Poisson clumping, or Poisson bursts, [1] is a phenomenon where random events may appear to occur in clusters, clumps, or bursts.
Poisson clumping, or Poisson bursts, [1] is a phenomenon where random events may appear to occur in clusters, clumps, or bursts.
Poisson clumping is named for 19th-century French mathematician Siméon Denis Poisson, [1] known for his work on definite integrals, electromagnetic theory, and probability theory, and after whom the Poisson distribution is also named.
The Poisson process provides a description of random independent events occurring with uniform probability through time and/or space. The expected number λ of events in a time interval or area of a given measure is proportional to that measure. The distribution of the number of events follows a Poisson distribution entirely determined by the parameter λ. If λ is small, events are rare, but may nevertheless occur in clumps—referred to as Poisson clumps or bursts—purely by chance. [2] In many cases there is no other cause behind such indefinite groupings besides the nature of randomness following this distribution. [3] However, obviously not all clumping in nature can be explained by this property — for example earthquakes, because of local seismic activity that causes groups of local aftershocks, in this case Weibull distribution is proposed. [4]
Poisson clumping is used to explain marked increases or decreases in the frequency of an event, such as shark attacks, "coincidences", birthdays, heads or tails from coin tosses, and e-mail correspondence. [5] [6]
The poisson clumping heuristic (PCH), published by David Aldous in 1989, [7] is a model for finding first-order approximations over different areas in a large class of stationary probability models. The probability models have a specific monotonicity property with large exclusions. The probability that this will achieve a large value is asymptotically small and is distributed in a Poisson fashion. [8]

In probability theory and statistics, a probability distribution is the mathematical function that gives the probabilities of occurrence of possible outcomes for an experiment. It is a mathematical description of a random phenomenon in terms of its sample space and the probabilities of events.

In probability theory and statistics, the negative binomial distribution is a discrete probability distribution that models the number of failures in a sequence of independent and identically distributed Bernoulli trials before a specified (non-random) number of successes occurs. For example, we can define rolling a 6 on some dice as a success, and rolling any other number as a failure, and ask how many failure rolls will occur before we see the third success. In such a case, the probability distribution of the number of failures that appear will be a negative binomial distribution.

In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the distance between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate; the distance parameter could be any meaningful mono-dimensional measure of the process, such as time between production errors, or length along a roll of fabric in the weaving manufacturing process. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.
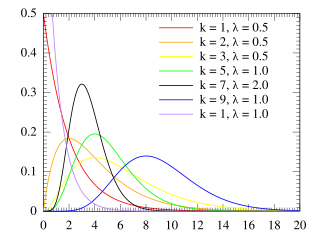
The Erlang distribution is a two-parameter family of continuous probability distributions with support . The two parameters are:

In probability theory and statistics, the Weibull distribution is a continuous probability distribution. It models a broad range of random variables, largely in the nature of a time to failure or time between events. Examples are maximum one-day rainfalls and the time a user spends on a web page.
A return period, also known as a recurrence interval or repeat interval, is an average time or an estimated average time between events such as earthquakes, floods, landslides, or river discharge flows to occur.
In the field of information retrieval, divergence from randomness (DFR), is a generalization of one of the very first models, Harter's 2-Poisson indexing-model. It is one type of probabilistic model. It is used to test the amount of information carried in documents. The 2-Poisson model is based on the hypothesis that the level of documents is related to a set of documents that contains words that occur in relatively greater extent than in the rest of the documents. It is not a 'model', but a framework for weighting terms using probabilistic methods, and it has a special relationship for term weighting based on the notion of elite

David John Aldous FRS is a mathematician known for his research on probability theory and its applications, in particular in topics such as exchangeability, weak convergence, Markov chain mixing times, the continuum random tree and stochastic coalescence. He entered St. John's College, Cambridge, in 1970 and received his Ph.D. at the University of Cambridge in 1977 under his advisor, D. J. H. Garling. Aldous was on the faculty at University of California, Berkeley from 1979 until his retirement in 2018.
In probability theory and statistics, the index of dispersion, dispersion index, coefficient of dispersion, relative variance, or variance-to-mean ratio (VMR), like the coefficient of variation, is a normalized measure of the dispersion of a probability distribution: it is a measure used to quantify whether a set of observed occurrences are clustered or dispersed compared to a standard statistical model.
This page lists articles related to probability theory. In particular, it lists many articles corresponding to specific probability distributions. Such articles are marked here by a code of the form (X:Y), which refers to number of random variables involved and the type of the distribution. For example (2:DC) indicates a distribution with two random variables, discrete or continuous. Other codes are just abbreviations for topics. The list of codes can be found in the table of contents.

In probability theory and statistics, there are several relationships among probability distributions. These relations can be categorized in the following groups:

For statistics in probability theory, the Boolean-Poisson model or simply Boolean model for a random subset of the plane is one of the simplest and most tractable models in stochastic geometry. Take a Poisson point process of rate in the plane and make each point be the center of a random set; the resulting union of overlapping sets is a realization of the Boolean model . More precisely, the parameters are and a probability distribution on compact sets; for each point of the Poisson point process we pick a set from the distribution, and then define as the union of translated sets.

In probability theory and statistics, the Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time if these events occur with a known constant mean rate and independently of the time since the last event. It can also be used for the number of events in other types of intervals than time, and in dimension greater than 1.
In probability theory, the zero-truncated Poisson distribution is a certain discrete probability distribution whose support is the set of positive integers. This distribution is also known as the conditional Poisson distribution or the positive Poisson distribution. It is the conditional probability distribution of a Poisson-distributed random variable, given that the value of the random variable is not zero. Thus it is impossible for a ZTP random variable to be zero. Consider for example the random variable of the number of items in a shopper's basket at a supermarket checkout line. Presumably a shopper does not stand in line with nothing to buy, so this phenomenon may follow a ZTP distribution.
The Borel distribution is a discrete probability distribution, arising in contexts including branching processes and queueing theory. It is named after the French mathematician Émile Borel.
In probability and statistics, a point process operation or point process transformation is a type of mathematical operation performed on a random object known as a point process, which are often used as mathematical models of phenomena that can be represented as points randomly located in space. These operations can be purely random, deterministic or both, and are used to construct new point processes, which can be then also used as mathematical models. The operations may include removing or thinning points from a point process, combining or superimposing multiple point processes into one point process or transforming the underlying space of the point process into another space. Point process operations and the resulting point processes are used in the theory of point processes and related fields such as stochastic geometry and spatial statistics.

In probability theory, statistics and related fields, a Poisson point process is a type of mathematical object that consists of points randomly located on a mathematical space with the essential feature that the points occur independently of one another. The process's name derives from the fact that the number of points in any given finite region follows a Poisson distribution. The process and the distribution are named after French mathematician Siméon Denis Poisson. The process itself was discovered independently and repeatedly in several settings, including experiments on radioactive decay, telephone call arrivals and actuarial science.
In probability theory and statistics, the discrete Weibull distribution is the discrete variant of the Weibull distribution. The Discrete Weibull Distribution, first introduced by Toshio Nakagawa and Shunji Osaki, is a discrete analog of the continuous Weibull distribution, predominantly used in reliability engineering. It is particularly applicable for modeling failure data measured in discrete units like cycles or shocks. This distribution provides a versatile tool for analyzing scenarios where the timing of events is counted in distinct intervals, making it distinctively useful in fields that deal with discrete data patterns and reliability analysis. The discrete Weibull distribution is infinitely divisible only for .