The P versus NP problem is a major unsolved problem in theoretical computer science. In informal terms, it asks whether every problem whose solution can be quickly verified can also be quickly solved.
In computational complexity theory, co-NP is a complexity class. A decision problem X is a member of co-NP if and only if its complement X is in the complexity class NP. The class can be defined as follows: a decision problem is in co-NP precisely if only no-instances have a polynomial-length "certificate" and there is a polynomial-time algorithm that can be used to verify any purported certificate.
In theoretical computer science and mathematics, computational complexity theory focuses on classifying computational problems according to their resource usage, and relating these classes to each other. A computational problem is a task solved by a computer. A computation problem is solvable by mechanical application of mathematical steps, such as an algorithm.

In computational complexity theory, NP is a complexity class used to classify decision problems. NP is the set of decision problems for which the problem instances, where the answer is "yes", have proofs verifiable in polynomial time by a deterministic Turing machine, or alternatively the set of problems that can be solved in polynomial time by a nondeterministic Turing machine.
The #P-complete problems form a complexity class in computational complexity theory. The problems in this complexity class are defined by having the following two properties:

In computational complexity theory, PSPACE is the set of all decision problems that can be solved by a Turing machine using a polynomial amount of space.
In computational complexity theory, NP-hardness is the defining property of a class of problems that are informally "at least as hard as the hardest problems in NP". A simple example of an NP-hard problem is the subset sum problem.
In computational complexity theory, a decision problem is P-complete if it is in P and every problem in P can be reduced to it by an appropriate reduction.
In computational complexity theory, a decision problem is PSPACE-complete if it can be solved using an amount of memory that is polynomial in the input length and if every other problem that can be solved in polynomial space can be transformed to it in polynomial time. The problems that are PSPACE-complete can be thought of as the hardest problems in PSPACE, the class of decision problems solvable in polynomial space, because a solution to any one such problem could easily be used to solve any other problem in PSPACE.
In computational complexity theory, the complexity class EXPTIME (sometimes called EXP or DEXPTIME) is the set of all decision problems that are solvable by a deterministic Turing machine in exponential time, i.e., in O(2p(n)) time, where p(n) is a polynomial function of n.
In computability theory and computational complexity theory, a many-one reduction is a reduction which converts instances of one decision problem to another decision problem using an effective function. The reduced instance is in the language if and only if the initial instance is in its language . Thus if we can decide whether instances are in the language , we can decide whether instances are in its language by applying the reduction and solving . Thus, reductions can be used to measure the relative computational difficulty of two problems. It is said that reduces to if, in layman's terms is harder to solve than . That is to say, any algorithm that solves can also be used as part of a program that solves .

In computer science, the time complexity is the computational complexity that describes the amount of computer time it takes to run an algorithm. Time complexity is commonly estimated by counting the number of elementary operations performed by the algorithm, supposing that each elementary operation takes a fixed amount of time to perform. Thus, the amount of time taken and the number of elementary operations performed by the algorithm are taken to be related by a constant factor.

In computational complexity theory, a complexity class is a set of computational problems of related resource-based complexity. The two most commonly analyzed resources are time and memory.
In computer science, parameterized complexity is a branch of computational complexity theory that focuses on classifying computational problems according to their inherent difficulty with respect to multiple parameters of the input or output. The complexity of a problem is then measured as a function of those parameters. This allows the classification of NP-hard problems on a finer scale than in the classical setting, where the complexity of a problem is only measured as a function of the number of bits in the input. This appears to have been first demonstrated in Gurevich, Stockmeyer & Vishkin (1984). The first systematic work on parameterized complexity was done by Downey & Fellows (1999).
In computational complexity theory, P, also known as PTIME or DTIME(nO(1)), is a fundamental complexity class. It contains all decision problems that can be solved by a deterministic Turing machine using a polynomial amount of computation time, or polynomial time.
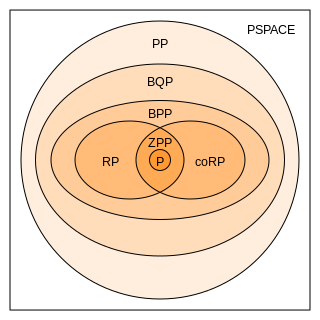
In complexity theory, PP is the class of decision problems solvable by a probabilistic Turing machine in polynomial time, with an error probability of less than 1/2 for all instances. The abbreviation PP refers to probabilistic polynomial time. The complexity class was defined by Gill in 1977.
In computational complexity theory, the Cook–Levin theorem, also known as Cook's theorem, states that the Boolean satisfiability problem is NP-complete. That is, it is in NP, and any problem in NP can be reduced in polynomial time by a deterministic Turing machine to the Boolean satisfiability problem.
In computational complexity theory, the complexity class NEXPTIME is the set of decision problems that can be solved by a non-deterministic Turing machine using time .
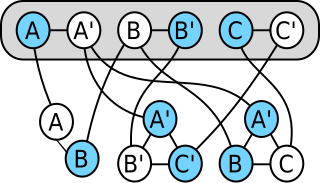
In computability theory and computational complexity theory, a reduction is an algorithm for transforming one problem into another problem. A sufficiently efficient reduction from one problem to another may be used to show that the second problem is at least as difficult as the first.

In computational complexity theory, a problem is NP-complete when:
- It is a decision problem, meaning that for any input to the problem, the output is either "yes" or "no".
- When the answer is "yes", this can be demonstrated through the existence of a short solution.
- The correctness of each solution can be verified quickly and a brute-force search algorithm can find a solution by trying all possible solutions.
- The problem can be used to simulate every other problem for which we can verify quickly that a solution is correct. In this sense, NP-complete problems are the hardest of the problems to which solutions can be verified quickly. If we could find solutions of some NP-complete problem quickly, we could quickly find the solutions of every other problem to which a given solution can be easily verified.





