Related Research Articles
Accuracy and precision are two measures of observational error. Accuracy is how close or far off a given set of measurements are to their true value, while precision is how close or dispersed the measurements are to each other.

Ectopic pregnancy is a complication of pregnancy in which the embryo attaches outside the uterus. Signs and symptoms classically include abdominal pain and vaginal bleeding, but fewer than 50 percent of affected women have both of these symptoms. The pain may be described as sharp, dull, or crampy. Pain may also spread to the shoulder if bleeding into the abdomen has occurred. Severe bleeding may result in a fast heart rate, fainting, or shock. With very rare exceptions the fetus is unable to survive.
Binary classification is the task of classifying the elements of a set into two groups on the basis of a classification rule. Typical binary classification problems include:

In statistics, the logistic model is a statistical model that models the probability of an event taking place by having the log-odds for the event be a linear combination of one or more independent variables. In regression analysis, logistic regression is estimating the parameters of a logistic model. Formally, in binary logistic regression there is a single binary dependent variable, coded by an indicator variable, where the two values are labeled "0" and "1", while the independent variables can each be a binary variable or a continuous variable. The corresponding probability of the value labeled "1" can vary between 0 and 1, hence the labeling; the function that converts log-odds to probability is the logistic function, hence the name. The unit of measurement for the log-odds scale is called a logit, from logistic unit, hence the alternative names. See § Background and § Definition for formal mathematics, and § Example for a worked example.
In statistics, the power of a binary hypothesis test is the probability that the test correctly rejects the null hypothesis when a specific alternative hypothesis is true. It is commonly denoted by , and represents the chances of a true positive detection conditional on the actual existence of an effect to detect. Statistical power ranges from 0 to 1, and as the power of a test increases, the probability of making a type II error by wrongly failing to reject the null hypothesis decreases.

Human chorionic gonadotropin (hCG) is a hormone for the maternal recognition of pregnancy produced by trophoblast cells that are surrounding a growing embryo, which eventually forms the placenta after implantation. The presence of hCG is detected in some pregnancy tests. Some cancerous tumors produce this hormone; therefore, elevated levels measured when the patient is not pregnant may lead to a cancer diagnosis and, if high enough, paraneoplastic syndromes, however, it is not known whether this production is a contributing cause, or an effect of carcinogenesis. The pituitary analog of hCG, known as luteinizing hormone (LH), is produced in the pituitary gland of males and females of all ages.

A pregnancy test is used to determine whether a female is pregnant. The two primary methods are testing for the female pregnancy hormone in blood or urine using a pregnancy test kit, and scanning with ultrasonography. Testing blood for hCG results in the earliest detection of pregnancy. Almost all pregnant women will have a positive urine pregnancy test one week after the first day of a missed menstrual period.
Prenatal testing consists of prenatal screening and prenatal diagnosis, which are aspects of prenatal care that focus on detecting problems with the pregnancy as early as possible. These may be anatomic and physiologic problems with the health of the zygote, embryo, or fetus, either before gestation even starts or as early in gestation as practicable. Screening can detect problems such as neural tube defects, chromosome abnormalities, and gene mutations that would lead to genetic disorders and birth defects, such as spina bifida, cleft palate, Down syndrome, Tay–Sachs disease, sickle cell anemia, thalassemia, cystic fibrosis, muscular dystrophy, and fragile X syndrome. Some tests are designed to discover problems which primarily affect the health of the mother, such as PAPP-A to detect pre-eclampsia or glucose tolerance tests to diagnose gestational diabetes. Screening can also detect anatomical defects such as hydrocephalus, anencephaly, heart defects, and amniotic band syndrome.
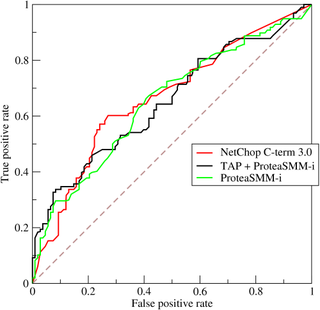
A receiver operating characteristic curve, or ROC curve, is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied. The method was originally developed for operators of military radar receivers starting in 1941, which led to its name.

The positive and negative predictive values are the proportions of positive and negative results in statistics and diagnostic tests that are true positive and true negative results, respectively. The PPV and NPV describe the performance of a diagnostic test or other statistical measure. A high result can be interpreted as indicating the accuracy of such a statistic. The PPV and NPV are not intrinsic to the test ; they depend also on the prevalence. Both PPV and NPV can be derived using Bayes' theorem.
Given a population whose members each belong to one of a number of different sets or classes, a classification rule or classifier is a procedure by which the elements of the population set are each predicted to belong to one of the classes. A perfect classification is one for which every element in the population is assigned to the class it really belongs to. An imperfect classification is one in which some errors appear, and then statistical analysis must be applied to analyse the classification.
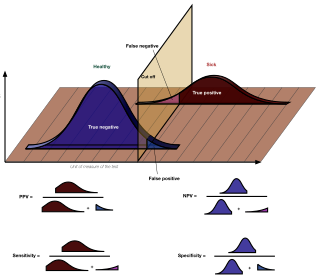
Sensitivity and specificity mathematically describe the accuracy of a test which reports the presence or absence of a condition. Individuals for which the condition is satisfied are considered "positive" and those for which it is not are considered "negative".
In statistical hypothesis testing, a type I error is the mistaken rejection of an actually true null hypothesis, while a type II error is the failure to reject a null hypothesis that is actually false. Much of statistical theory revolves around the minimization of one or both of these errors, though the complete elimination of either is a statistical impossibility if the outcome is not determined by a known, observable causal process. By selecting a low threshold (cut-off) value and modifying the alpha (α) level, the quality of the hypothesis test can be increased. The knowledge of type I errors and type II errors is widely used in medical science, biometrics and computer science.

A medical test is a medical procedure performed to detect, diagnose, or monitor diseases, disease processes, susceptibility, or to determine a course of treatment. Medical tests such as, physical and visual exams, diagnostic imaging, genetic testing, chemical and cellular analysis, relating to clinical chemistry and molecular diagnostics, are typically performed in a medical setting.

In pattern recognition, information retrieval, object detection and classification, precision and recall are performance metrics that apply to data retrieved from a collection, corpus or sample space.
In statistics, the phi coefficient is a measure of association for two binary variables. In machine learning, it is known as the Matthews correlation coefficient (MCC) and used as a measure of the quality of binary (two-class) classifications, introduced by biochemist Brian W. Matthews in 1975. Introduced by Karl Pearson, and also known as the Yule phi coefficient from its introduction by Udny Yule in 1912 this measure is similar to the Pearson correlation coefficient in its interpretation. In fact, a Pearson correlation coefficient estimated for two binary variables will return the phi coefficient. Two binary variables are considered positively associated if most of the data falls along the diagonal cells. In contrast, two binary variables are considered negatively associated if most of the data falls off the diagonal. If we have a 2×2 table for two random variables x and y
Pre-test probability and post-test probability are the probabilities of the presence of a condition before and after a diagnostic test, respectively. Post-test probability, in turn, can be positive or negative, depending on whether the test falls out as a positive test or a negative test, respectively. In some cases, it is used for the probability of developing the condition of interest in the future.
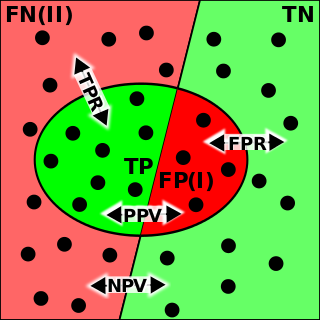
The evaluation of binary classifiers compares two methods of assigning a binary attribute, one of which is usually a standard method and the other is being investigated. There are many metrics that can be used to measure the performance of a classifier or predictor; different fields have different preferences for specific metrics due to different goals. For example, in medicine sensitivity and specificity are often used, while in computer science precision and recall are preferred. An important distinction is between metrics that are independent on the prevalence, and metrics that depend on the prevalence – both types are useful, but they have very different properties.
A false positive is an error in binary classification in which a test result incorrectly indicates the presence of a condition, while a false negative is the opposite error, where the test result incorrectly indicates the absence of a condition when it is actually present. These are the two kinds of errors in a binary test, in contrast to the two kinds of correct result. They are also known in medicine as a false positivediagnosis, and in statistical classification as a false positiveerror.
Fairness in machine learning refers to the various attempts at correcting algorithmic bias in automated decision processes based on machine learning models. Decisions made by computers after a machine-learning process may be considered unfair if they were based on variables considered sensitive. Examples of these kinds of variable include gender, ethnicity, sexual orientation, disability and more. As it is the case with many ethical concepts, definitions of fairness and bias are always controversial. In general, fairness and bias are considered relevant when the decision process impacts people's lives. In machine learning, the problem of algorithmic bias is well known and well studied. Outcomes may be skewed by a range of factors and thus might be considered unfair with respect to certain groups or individuals. An example would be the way social media sites deliver personalized news to consumers.
References
- ↑ "Predictive Value of Tests - MeSH - NCBI". www.ncbi.nlm.nih.gov. Retrieved 12 August 2018.
| | This medical diagnostic article is a stub. You can help Wikipedia by expanding it. |