
In physics, the Maxwell–Boltzmann distribution, or Maxwell(ian) distribution, is a particular probability distribution named after James Clerk Maxwell and Ludwig Boltzmann.

In statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is
In probability theory, the central limit theorem (CLT) establishes that, in many situations, for identically distributed independent samples, the standardized sample mean tends towards the standard normal distribution even if the original variables themselves are not normally distributed.

In probability theory, a log-normal (or lognormal) distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed. Thus, if the random variable X is log-normally distributed, then Y = ln(X) has a normal distribution. Equivalently, if Y has a normal distribution, then the exponential function of Y, X = exp(Y), has a log-normal distribution. A random variable which is log-normally distributed takes only positive real values. It is a convenient and useful model for measurements in exact and engineering sciences, as well as medicine, economics and other topics (e.g., energies, concentrations, lengths, prices of financial instruments, and other metrics).
In statistical mechanics, the Fokker–Planck equation is a partial differential equation that describes the time evolution of the probability density function of the velocity of a particle under the influence of drag forces and random forces, as in Brownian motion. The equation can be generalized to other observables as well.

In probability theory and statistics, a covariance matrix is a square matrix giving the covariance between each pair of elements of a given random vector. Any covariance matrix is symmetric and positive semi-definite and its main diagonal contains variances.
In mathematics, Itô's lemma or Itô's formula is an identity used in Itô calculus to find the differential of a time-dependent function of a stochastic process. It serves as the stochastic calculus counterpart of the chain rule. It can be heuristically derived by forming the Taylor series expansion of the function up to its second derivatives and retaining terms up to first order in the time increment and second order in the Wiener process increment. The lemma is widely employed in mathematical finance, and its best known application is in the derivation of the Black–Scholes equation for option values.
In mathematics, a Gaussian function, often simply referred to as a Gaussian, is a function of the base form

In probability theory and statistics, the Rayleigh distribution is a continuous probability distribution for nonnegative-valued random variables. Up to rescaling, it coincides with the chi distribution with two degrees of freedom. The distribution is named after Lord Rayleigh.
The Ising model, named after the physicists Ernst Ising and Wilhelm Lenz, is a mathematical model of ferromagnetism in statistical mechanics. The model consists of discrete variables that represent magnetic dipole moments of atomic "spins" that can be in one of two states. The spins are arranged in a graph, usually a lattice, allowing each spin to interact with its neighbors. Neighboring spins that agree have a lower energy than those that disagree; the system tends to the lowest energy but heat disturbs this tendency, thus creating the possibility of different structural phases. The model allows the identification of phase transitions as a simplified model of reality. The two-dimensional square-lattice Ising model is one of the simplest statistical models to show a phase transition.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, including the enabling of the user to calculate expectations, covariances using differentiation based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. The terms "distribution" and "family" are often used loosely: specifically, an exponential family is a set of distributions, where the specific distribution varies with the parameter; however, a parametric family of distributions is often referred to as "a distribution", and the set of all exponential families is sometimes loosely referred to as "the" exponential family. They are distinct because they possess a variety of desirable properties, most importantly the existence of a sufficient statistic.
In statistics, propagation of uncertainty is the effect of variables' uncertainties on the uncertainty of a function based on them. When the variables are the values of experimental measurements they have uncertainties due to measurement limitations which propagate due to the combination of variables in the function.

The Voigt profile is a probability distribution given by a convolution of a Cauchy-Lorentz distribution and a Gaussian distribution. It is often used in analyzing data from spectroscopy or diffraction.

In probability theory, the Rice distribution or Rician distribution is the probability distribution of the magnitude of a circularly-symmetric bivariate normal random variable, possibly with non-zero mean (noncentral). It was named after Stephen O. Rice (1907–1986).

In probability theory and statistics, the chi distribution is a continuous probability distribution. It is the distribution of the positive square root of the sum of squares of a set of independent random variables each following a standard normal distribution, or equivalently, the distribution of the Euclidean distance of the random variables from the origin. It is thus related to the chi-squared distribution by describing the distribution of the positive square roots of a variable obeying a chi-squared distribution.

The lattice Boltzmann methods (LBM), originated from the lattice gas automata (LGA) method (Hardy-Pomeau-Pazzis and Frisch-Hasslacher-Pomeau models), is a class of computational fluid dynamics (CFD) methods for fluid simulation. Instead of solving the Navier–Stokes equations directly, a fluid density on a lattice is simulated with streaming and collision (relaxation) processes. The method is versatile as the model fluid can straightforwardly be made to mimic common fluid behaviour like vapour/liquid coexistence, and so fluid systems such as liquid droplets can be simulated. Also, fluids in complex environments such as porous media can be straightforwardly simulated, whereas with complex boundaries other CFD methods can be hard to work with.

The softmax function, also known as softargmax or normalized exponential function, converts a vector of K real numbers into a probability distribution of K possible outcomes. It is a generalization of the logistic function to multiple dimensions, and used in multinomial logistic regression. The softmax function is often used as the last activation function of a neural network to normalize the output of a network to a probability distribution over predicted output classes, based on Luce's choice axiom.
In statistics, the multivariate t-distribution is a multivariate probability distribution. It is a generalization to random vectors of the Student's t-distribution, which is a distribution applicable to univariate random variables. While the case of a random matrix could be treated within this structure, the matrix t-distribution is distinct and makes particular use of the matrix structure.
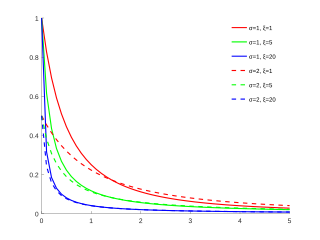
In statistics, the generalized Pareto distribution (GPD) is a family of continuous probability distributions. It is often used to model the tails of another distribution. It is specified by three parameters: location , scale , and shape . Sometimes it is specified by only scale and shape and sometimes only by its shape parameter. Some references give the shape parameter as .
In analytic number theory, a Dirichlet series, or Dirichlet generating function (DGF), of a sequence is a common way of understanding and summing arithmetic functions in a meaningful way. A little known, or at least often forgotten about, way of expressing formulas for arithmetic functions and their summatory functions is to perform an integral transform that inverts the operation of forming the DGF of a sequence. This inversion is analogous to performing an inverse Z-transform to the generating function of a sequence to express formulas for the series coefficients of a given ordinary generating function.






























