
In physics, the Lorentz transformations are a six-parameter family of linear transformations from a coordinate frame in spacetime to another frame that moves at a constant velocity relative to the former. The respective inverse transformation is then parameterized by the negative of this velocity. The transformations are named after the Dutch physicist Hendrik Lorentz.

In mathematical physics and mathematics, the Pauli matrices are a set of three 2 × 2 complex matrices which are Hermitian, involutory and unitary. Usually indicated by the Greek letter sigma, they are occasionally denoted by tau when used in connection with isospin symmetries.

In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables each of which clusters around a mean value.
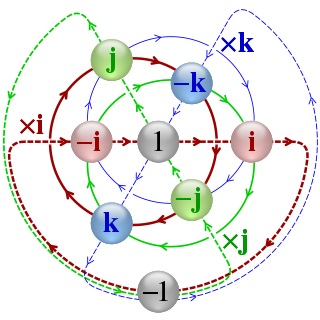
In mathematics, the quaternion number system extends the complex numbers. Quaternions were first described by the Irish mathematician William Rowan Hamilton in 1843 and applied to mechanics in three-dimensional space. Hamilton defined a quaternion as the quotient of two directed lines in a three-dimensional space, or, equivalently, as the quotient of two vectors. Multiplication of quaternions is noncommutative.

In linear algebra, the singular value decomposition (SVD) is a factorization of a real or complex matrix. It generalizes the eigendecomposition of a square normal matrix with an orthonormal eigenbasis to any matrix. It is related to the polar decomposition.
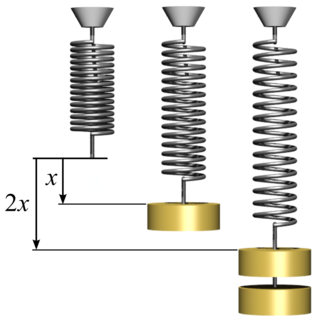
In physics, Hooke's law is an empirical law which states that the force needed to extend or compress a spring by some distance scales linearly with respect to that distance—that is, Fs = kx, where k is a constant factor characteristic of the spring, and x is small compared to the total possible deformation of the spring. The law is named after 17th-century British physicist Robert Hooke. He first stated the law in 1676 as a Latin anagram. He published the solution of his anagram in 1678 as: ut tensio, sic vis. Hooke states in the 1678 work that he was aware of the law since 1660.
In statistics, the Wishart distribution is a generalization to multiple dimensions of the gamma distribution. It is named in honor of John Wishart, who first formulated the distribution in 1928. Other names include Wishart ensemble, or Wishart–Laguerre ensemble, or LOE, LUE, LSE.

In physics, the reciprocal lattice represents the Fourier transform of another lattice. The direct lattice or real lattice is a periodic function in physical space, such as a crystal system. The reciprocal lattice exists in the mathematical space of spatial frequencies, known as reciprocal space or k space, where refers to the wavevector.
In mathematics, the matrix exponential is a matrix function on square matrices analogous to the ordinary exponential function. It is used to solve systems of linear differential equations. In the theory of Lie groups, the matrix exponential gives the exponential map between a matrix Lie algebra and the corresponding Lie group.

In mathematics, in particular functional analysis, the singular values, or s-numbers of a compact operator acting between Hilbert spaces and , are the square roots of the eigenvalues of the self-adjoint operator .
In linear algebra, a rotation matrix is a transformation matrix that is used to perform a rotation in Euclidean space. For example, using the convention below, the matrix

The Maxwell stress tensor is a symmetric second-order tensor used in classical electromagnetism to represent the interaction between electromagnetic forces and mechanical momentum. In simple situations, such as a point charge moving freely in a homogeneous magnetic field, it is easy to calculate the forces on the charge from the Lorentz force law. When the situation becomes more complicated, this ordinary procedure can become impractically difficult, with equations spanning multiple lines. It is therefore convenient to collect many of these terms in the Maxwell stress tensor, and to use tensor arithmetic to find the answer to the problem at hand.

In continuum mechanics, the Cauchy stress tensor, true stress tensor, or simply called the stress tensor is a second order tensor named after Augustin-Louis Cauchy. The tensor consists of nine components that completely define the state of stress at a point inside a material in the deformed state, placement, or configuration. The tensor relates a unit-length direction vector e to the traction vector T(e) across an imaginary surface perpendicular to e:
Bayesian linear regression is a type of conditional modeling in which the mean of one variable is described by a linear combination of other variables, with the goal of obtaining the posterior probability of the regression coefficients and ultimately allowing the out-of-sample prediction of the regressandconditional on observed values of the regressors. The simplest and most widely used version of this model is the normal linear model, in which given is distributed Gaussian. In this model, and under a particular choice of prior probabilities for the parameters—so-called conjugate priors—the posterior can be found analytically. With more arbitrarily chosen priors, the posteriors generally have to be approximated.
In statistics, Bayesian multivariate linear regression is a Bayesian approach to multivariate linear regression, i.e. linear regression where the predicted outcome is a vector of correlated random variables rather than a single scalar random variable. A more general treatment of this approach can be found in the article MMSE estimator.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
In the fields of computer vision and image analysis, the Harris affine region detector belongs to the category of feature detection. Feature detection is a preprocessing step of several algorithms that rely on identifying characteristic points or interest points so to make correspondences between images, recognize textures, categorize objects or build panoramas.

In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.
This article derives the main properties of rotations in 3-dimensional space.
For certain applications in linear algebra, it is useful to know properties of the probability distribution of the largest eigenvalue of a finite sum of random matrices. Suppose is a finite sequence of random matrices. Analogous to the well-known Chernoff bound for sums of scalars, a bound on the following is sought for a given parameter t:






















































