In mathematics, graph theory is the study of graphs, which are mathematical structures used to model pairwise relations between objects. A graph in this context is made up of vertices which are connected by edges. A distinction is made between undirected graphs, where edges link two vertices symmetrically, and directed graphs, where edges link two vertices asymmetrically. Graphs are one of the principal objects of study in discrete mathematics.

A scale-free network is a network whose degree distribution follows a power law, at least asymptotically. That is, the fraction P(k) of nodes in the network having k connections to other nodes goes for large values of k as

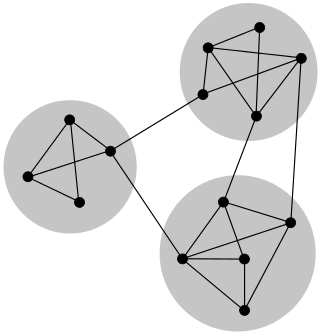
In graph theory, a component of an undirected graph is a connected subgraph that is not part of any larger connected subgraph. The components of any graph partition its vertices into disjoint sets, and are the induced subgraphs of those sets. A graph that is itself connected has exactly one component, consisting of the whole graph. Components are sometimes called connected components.
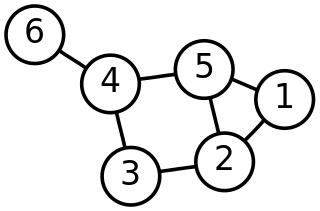
In discrete mathematics, and more specifically in graph theory, a graph is a structure amounting to a set of objects in which some pairs of the objects are in some sense "related". The objects are represented by abstractions called vertices and each of the related pairs of vertices is called an edge. Typically, a graph is depicted in diagrammatic form as a set of dots or circles for the vertices, joined by lines or curves for the edges.

In mathematics, random graph is the general term to refer to probability distributions over graphs. Random graphs may be described simply by a probability distribution, or by a random process which generates them. The theory of random graphs lies at the intersection between graph theory and probability theory. From a mathematical perspective, random graphs are used to answer questions about the properties of typical graphs. Its practical applications are found in all areas in which complex networks need to be modeled – many random graph models are thus known, mirroring the diverse types of complex networks encountered in different areas. In a mathematical context, random graph refers almost exclusively to the Erdős–Rényi random graph model. In other contexts, any graph model may be referred to as a random graph.
A graphical model or probabilistic graphical model (PGM) or structured probabilistic model is a probabilistic model for which a graph expresses the conditional dependence structure between random variables. They are commonly used in probability theory, statistics—particularly Bayesian statistics—and machine learning.
In graph theory, a clustering coefficient is a measure of the degree to which nodes in a graph tend to cluster together. Evidence suggests that in most real-world networks, and in particular social networks, nodes tend to create tightly knit groups characterised by a relatively high density of ties; this likelihood tends to be greater than the average probability of a tie randomly established between two nodes.
In graph theory and network analysis, indicators of centrality assign numbers or rankings to nodes within a graph corresponding to their network position. Applications include identifying the most influential person(s) in a social network, key infrastructure nodes in the Internet or urban networks, super-spreaders of disease, and brain networks. Centrality concepts were first developed in social network analysis, and many of the terms used to measure centrality reflect their sociological origin.
In mathematics and computer science, connectivity is one of the basic concepts of graph theory: it asks for the minimum number of elements that need to be removed to separate the remaining nodes into two or more isolated subgraphs. It is closely related to the theory of network flow problems. The connectivity of a graph is an important measure of its resilience as a network.

In graph theory, a maximal independent set (MIS) or maximal stable set is an independent set that is not a subset of any other independent set. In other words, there is no vertex outside the independent set that may join it because it is maximal with respect to the independent set property.

In network theory, a giant component is a connected component of a given random graph that contains a significant fraction of the entire graph's vertices.
In the study of scale-free networks, a copying mechanism is a process by which such a network can form and grow, by means of repeated steps in which nodes are duplicated with mutations from existing nodes. Several variations have been studied. In the general copying model, a growing network starts as a small initial graph and, at each time step, a new vertex is added with a given number k of new outgoing edges. As a result of a stochastic selection, the neighbors of the new vertex are either chosen randomly among the existing vertices, or one existing vertex is randomly selected and k of its neighbors are "copied" as heads of the new edges.
In the mathematical field of graph theory, the Erdős–Rényi model refers to one of two closely related models for generating random graphs or the evolution of a random network. These models are named after Hungarian mathematicians Paul Erdős and Alfréd Rényi, who introduced one of the models in 1959. Edgar Gilbert introduced the other model contemporaneously with and independently of Erdős and Rényi. In the model of Erdős and Rényi, all graphs on a fixed vertex set with a fixed number of edges are equally likely. In the model introduced by Gilbert, also called the Erdős–Rényi–Gilbert model, each edge has a fixed probability of being present or absent, independently of the other edges. These models can be used in the probabilistic method to prove the existence of graphs satisfying various properties, or to provide a rigorous definition of what it means for a property to hold for almost all graphs.

In computer science and graph theory, Karger's algorithm is a randomized algorithm to compute a minimum cut of a connected graph. It was invented by David Karger and first published in 1993.
In graph theory, a random geometric graph (RGG) is the mathematically simplest spatial network, namely an undirected graph constructed by randomly placing N nodes in some metric space and connecting two nodes by a link if and only if their distance is in a given range, e.g. smaller than a certain neighborhood radius, r.
Network science is an academic field which studies complex networks such as telecommunication networks, computer networks, biological networks, cognitive and semantic networks, and social networks, considering distinct elements or actors represented by nodes and the connections between the elements or actors as links. The field draws on theories and methods including graph theory from mathematics, statistical mechanics from physics, data mining and information visualization from computer science, inferential modeling from statistics, and social structure from sociology. The United States National Research Council defines network science as "the study of network representations of physical, biological, and social phenomena leading to predictive models of these phenomena."
Modularity is a measure of the structure of networks or graphs which measures the strength of division of a network into modules. Networks with high modularity have dense connections between the nodes within modules but sparse connections between nodes in different modules. Modularity is often used in optimization methods for detecting community structure in networks. Biological networks, including animal brains, exhibit a high degree of modularity. However, modularity maximization is not statistically consistent, and finds communities in its own null model, i.e. fully random graphs, and therefore it cannot be used to find statistically significant community structures in empirical networks. Furthermore, it has been shown that modularity suffers a resolution limit and, therefore, it is unable to detect small communities.

PageRank (PR) is an algorithm used by Google Search to rank web pages in their search engine results. It is named after both the term "web page" and co-founder Larry Page. PageRank is a way of measuring the importance of website pages. According to Google:
PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites.

In network science, the configuration model is a method for generating random networks from a given degree sequence. It is widely used as a reference model for real-life social networks, because it allows the modeler to incorporate arbitrary degree distributions.
Copying network models are network generation models that use a copying mechanism to form a network, by repeatedly duplicating and mutating existing nodes of the network. Such a network model has first been proposed in 1999 to explain the network of links between web pages, but since has been used to model biological and citation networks as well.














