As analysis
The similarly named reaching definitions is a data-flow analysis which statically determines which definitions may reach a given point in the code. Because of its simplicity, it is often used as the canonical example of a data-flow analysis in textbooks. The data-flow confluence operator used is set union, and the analysis is forward flow. Reaching definitions are used to compute use-def chains.
The data-flow equations used for a given basic block  in reaching definitions are:
in reaching definitions are:


In other words, the set of reaching definitions going into are all of the reaching definitions from 's predecessors,  . consists of all of the basic blocks that come before in the control-flow graph. The reaching definitions coming out of are all reaching definitions of its predecessors minus those reaching definitions whose variable is killed by plus any new definitions generated within .
. consists of all of the basic blocks that come before in the control-flow graph. The reaching definitions coming out of are all reaching definitions of its predecessors minus those reaching definitions whose variable is killed by plus any new definitions generated within .
For a generic instruction, we define the  and
and  sets as follows:
sets as follows:
 , a set of locally available definitions in a basic block
, a set of locally available definitions in a basic block , a set of definitions (not locally available, but in the rest of the program) killed by definitions in the basic block.
, a set of definitions (not locally available, but in the rest of the program) killed by definitions in the basic block.
where  is the set of all definitions that assign to the variable
is the set of all definitions that assign to the variable  . Here
. Here  is a unique label attached to the assigning instruction; thus, the domain of values in reaching definitions are these instruction labels.
is a unique label attached to the assigning instruction; thus, the domain of values in reaching definitions are these instruction labels.

In mathematics, an ordered pair, denoted (a, b), is a pair of objects in which their order is significant. The ordered pair (a, b) is different from the ordered pair (b, a), unless a = b. In contrast, the unordered pair, denoted {a, b}, equals the unordered pair {b, a}.
In computability theory, a primitive recursive function is, roughly speaking, a function that can be computed by a computer program whose loops are all "for" loops. Primitive recursive functions form a strict subset of those general recursive functions that are also total functions.
A low-pass filter is a filter that passes signals with a frequency lower than a selected cutoff frequency and attenuates signals with frequencies higher than the cutoff frequency. The exact frequency response of the filter depends on the filter design. The filter is sometimes called a high-cut filter, or treble-cut filter in audio applications. A low-pass filter is the complement of a high-pass filter.
A Bayesian network is a probabilistic graphical model that represents a set of variables and their conditional dependencies via a directed acyclic graph (DAG). While it is one of several forms of causal notation, causal networks are special cases of Bayesian networks. Bayesian networks are ideal for taking an event that occurred and predicting the likelihood that any one of several possible known causes was the contributing factor. For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases.
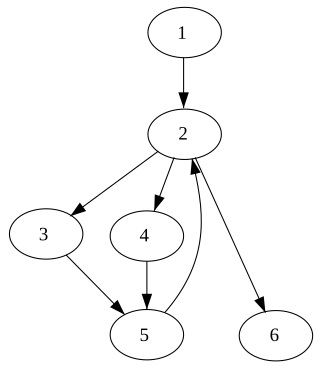
In computer science, a node d of a control-flow graph dominates a node n if every path from the entry node to n must go through d. Notationally, this is written as d dom n. By definition, every node dominates itself.

In optimization theory, maximum flow problems involve finding a feasible flow through a flow network that obtains the maximum possible flow rate.
The Arzelà–Ascoli theorem is a fundamental result of mathematical analysis giving necessary and sufficient conditions to decide whether every sequence of a given family of real-valued continuous functions defined on a closed and bounded interval has a uniformly convergent subsequence. The main condition is the equicontinuity of the family of functions. The theorem is the basis of many proofs in mathematics, including that of the Peano existence theorem in the theory of ordinary differential equations, Montel's theorem in complex analysis, and the Peter–Weyl theorem in harmonic analysis and various results concerning compactness of integral operators.
Data-flow analysis is a technique for gathering information about the possible set of values calculated at various points in a computer program. A program's control-flow graph (CFG) is used to determine those parts of a program to which a particular value assigned to a variable might propagate. The information gathered is often used by compilers when optimizing a program. A canonical example of a data-flow analysis is reaching definitions.

In mathematics, an Apollonian gasket or Apollonian net is a fractal generated by starting with a triple of circles, each tangent to the other two, and successively filling in more circles, each tangent to another three. It is named after Greek mathematician Apollonius of Perga.
Within computer science, a use-definition chain is a data structure that consists of a use U, of a variable, and all the definitions D of that variable that can reach that use without any other intervening definitions. A UD Chain generally means the assignment of some value to a variable.
In mathematics, a binary relation R ⊆ X×Y between two sets X and Y is total if the source set X equals the domain {x : there is a y with xRy }. Conversely, R is called right total if Y equals the range {y : there is an x with xRy }.
In mathematics, Church encoding is a means of representing data and operators in the lambda calculus. The Church numerals are a representation of the natural numbers using lambda notation. The method is named for Alonzo Church, who first encoded data in the lambda calculus this way.
This article examines the implementation of mathematical concepts in set theory. The implementation of a number of basic mathematical concepts is carried out in parallel in ZFC and in NFU, the version of Quine's New Foundations shown to be consistent by R. B. Jensen in 1969.

In computer science, recursion is a method of solving a computational problem where the solution depends on solutions to smaller instances of the same problem. Recursion solves such recursive problems by using functions that call themselves from within their own code. The approach can be applied to many types of problems, and recursion is one of the central ideas of computer science.
The power of recursion evidently lies in the possibility of defining an infinite set of objects by a finite statement. In the same manner, an infinite number of computations can be described by a finite recursive program, even if this program contains no explicit repetitions.
In compilers, live variable analysis is a classic data-flow analysis to calculate the variables that are live at each point in the program. A variable is live at some point if it holds a value that may be needed in the future, or equivalently if its value may be read before the next time the variable is written to.
In mathematics, two functions are said to be topologically conjugate if there exists a homeomorphism that will conjugate the one into the other. Topological conjugacy, and related-but-distinct § Topological equivalence of flows, are important in the study of iterated functions and more generally dynamical systems, since, if the dynamics of one iterative function can be determined, then that for a topologically conjugate function follows trivially.
In mathematical logic, more specifically in the proof theory of first-order theories, extensions by definitions formalize the introduction of new symbols by means of a definition. For example, it is common in naive set theory to introduce a symbol for the set that has no member. In the formal setting of first-order theories, this can be done by adding to the theory a new constant and the new axiom , meaning "for all x, x is not a member of ". It can then be proved that doing so adds essentially nothing to the old theory, as should be expected from a definition. More precisely, the new theory is a conservative extension of the old one.
In mathematics, Kuratowski convergence or Painlevé-Kuratowski convergence is a notion of convergence for subsets of a topological space. First introduced by Paul Painlevé in lectures on mathematical analysis in 1902, the concept was popularized in texts by Felix Hausdorff and Kazimierz Kuratowski. Intuitively, the Kuratowski limit of a sequence of sets is where the sets "accumulate".

In probability theory, conditional probability is a measure of the probability of an event occurring, given that another event (by assumption, presumption, assertion or evidence) is already known to have occurred. This particular method relies on event A occurring with some sort of relationship with another event B. In this situation, the event A can be analyzed by a conditional probability with respect to B. If the event of interest is A and the event B is known or assumed to have occurred, "the conditional probability of A given B", or "the probability of A under the condition B", is usually written as P(A|B) or occasionally PB(A). This can also be understood as the fraction of probability B that intersects with A, or the ratio of the probabilities of both events happening to the "given" one happening (how many times A occurs rather than not assuming B has occurred): .
In mathematics, in particular in category theory, the lifting property is a property of a pair of morphisms in a category. It is used in homotopy theory within algebraic topology to define properties of morphisms starting from an explicitly given class of morphisms. It appears in a prominent way in the theory of model categories, an axiomatic framework for homotopy theory introduced by Daniel Quillen. It is also used in the definition of a factorization system, and of a weak factorization system, notions related to but less restrictive than the notion of a model category. Several elementary notions may also be expressed using the lifting property starting from a list of (counter)examples.