Related Research Articles
A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another. Distributed computing is a field of computer science that studies distributed systems.

A supercomputer is a computer with a high level of performance as compared to a general-purpose computer. The performance of a supercomputer is commonly measured in floating-point operations per second (FLOPS) instead of million instructions per second (MIPS). Since 2017, supercomputers have existed which can perform over 1017 FLOPS (a hundred quadrillion FLOPS, 100 petaFLOPS or 100 PFLOPS). For comparison, a desktop computer has performance in the range of hundreds of gigaFLOPS (1011) to tens of teraFLOPS (1013). Since November 2017, all of the world's fastest 500 supercomputers run on Linux-based operating systems. Additional research is being conducted in the United States, the European Union, Taiwan, Japan, and China to build faster, more powerful and technologically superior exascale supercomputers.
In telecommunication, provisioning involves the process of preparing and equipping a network to allow it to provide new services to its users. In National Security/Emergency Preparedness telecommunications services, "provisioning" equates to "initiation" and includes altering the state of an existing priority service or capability.
Grid computing is the use of widely distributed computer resources to reach a common goal. A computing grid can be thought of as a distributed system with non-interactive workloads that involve many files. Grid computing is distinguished from conventional high-performance computing systems such as cluster computing in that grid computers have each node set to perform a different task/application. Grid computers also tend to be more heterogeneous and geographically dispersed than cluster computers. Although a single grid can be dedicated to a particular application, commonly a grid is used for a variety of purposes. Grids are often constructed with general-purpose grid middleware software libraries. Grid sizes can be quite large.
Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
Scalability is the property of a system to handle a growing amount of work. One definition for software systems specifies that this may be done by adding resources to the system.

In computer science, concurrency is the ability of different parts or units of a program, algorithm, or problem to be executed out-of-order or in partial order, without affecting the outcome. This allows for parallel execution of the concurrent units, which can significantly improve overall speed of the execution in multi-processor and multi-core systems. In more technical terms, concurrency refers to the decomposability of a program, algorithm, or problem into order-independent or partially-ordered components or units of computation.
General-purpose computing on graphics processing units is the use of a graphics processing unit (GPU), which typically handles computation only for computer graphics, to perform computation in applications traditionally handled by the central processing unit (CPU). The use of multiple video cards in one computer, or large numbers of graphics chips, further parallelizes the already parallel nature of graphics processing.

David A. Bader is a Distinguished Professor and Director of the Institute for Data Science at the New Jersey Institute of Technology. Previously, he served as the Chair of the Georgia Institute of Technology School of Computational Science & Engineering, where he was also a founding professor, and the executive director of High-Performance Computing at the Georgia Tech College of Computing. In 2007, he was named the first director of the Sony Toshiba IBM Center of Competence for the Cell Processor at Georgia Tech.
TeraGrid was an e-Science grid computing infrastructure combining resources at eleven partner sites. The project started in 2001 and operated from 2004 through 2011.

Özalp Babaoğlu, is a Turkish computer scientist. He is currently professor of computer science at the University of Bologna, Italy. He received a Ph.D. in 1981 from the University of California at Berkeley. He is the recipient of 1982 Sakrison Memorial Award, 1989 UNIX InternationalRecognition Award and 1993 USENIX AssociationLifetime Achievement Award for his contributions to the UNIX system community and to Open Industry Standards. Before moving to Bologna in 1988, Babaoğlu was an associate professor in the Department of Computer Science at Cornell University. He has participated in several European research projects in distributed computing and complex systems. Babaoğlu is an ACM Fellow and has served as a resident fellow of the Institute of Advanced Studies at the University of Bologna and on the editorial boards for ACM Transactions on Computer Systems, ACM Transactions on Autonomous and Adaptive Systems and Springer-Verlag Distributed Computing.

A computer cluster is a set of computers that work together so that they can be viewed as a single system. Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by software. The newest manifestation of cluster computing is cloud computing.
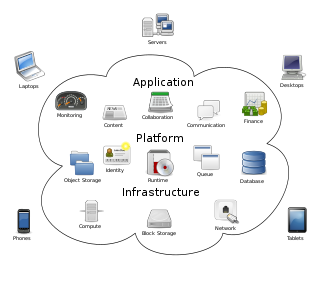
Cloud computing is the on-demand availability of computer system resources, especially data storage and computing power, without direct active management by the user. Large clouds often have functions distributed over multiple locations, each of which is a data center. Cloud computing relies on sharing of resources to achieve coherence and typically uses a pay-as-you-go model, which can help in reducing capital expenses but may also lead to unexpected operating expenses for users.

Quasi-opportunistic supercomputing is a computational paradigm for supercomputing on a large number of geographically disperse computers. Quasi-opportunistic supercomputing aims to provide a higher quality of service than opportunistic resource sharing.

Approaches to supercomputer architecture have taken dramatic turns since the earliest systems were introduced in the 1960s. Early supercomputer architectures pioneered by Seymour Cray relied on compact innovative designs and local parallelism to achieve superior computational peak performance. However, in time the demand for increased computational power ushered in the age of massively parallel systems.
A distributed file system for cloud is a file system that allows many clients to have access to data and supports operations on that data. Each data file may be partitioned into several parts called chunks. Each chunk may be stored on different remote machines, facilitating the parallel execution of applications. Typically, data is stored in files in a hierarchical tree, where the nodes represent directories. There are several ways to share files in a distributed architecture: each solution must be suitable for a certain type of application, depending on how complex the application is. Meanwhile, the security of the system must be ensured. Confidentiality, availability and integrity are the main keys for a secure system.
Computation offloading is the transfer of resource intensive computational tasks to a separate processor, such as a hardware accelerator, or an external platform, such as a cluster, grid, or a cloud. Offloading to a coprocessor can be used to accelerate applications including: image rendering and mathematical calculations. Offloading computing to an external platform over a network can provide computing power and overcome hardware limitations of a device, such as limited computational power, storage, and energy.
A cloudlet is a mobility-enhanced small-scale cloud datacenter that is located at the edge of the Internet. The main purpose of the cloudlet is supporting resource-intensive and interactive mobile applications by providing powerful computing resources to mobile devices with lower latency. It is a new architectural element that extends today's cloud computing infrastructure. It represents the middle tier of a 3-tier hierarchy: mobile device - cloudlet - cloud. A cloudlet can be viewed as a data center in a box whose goal is to bring the cloud closer. The cloudlet term was first coined by M. Satyanarayanan, Victor Bahl, Ramón Cáceres, and Nigel Davies, and a prototype implementation is developed by Carnegie Mellon University as a research project. The concept of cloudlet is also known as follow me cloud, and mobile micro-cloud.

Jayadev Misra is an Indian-born computer scientist who has spent most of his professional career in the United States. He is the Schlumberger Centennial Chair Emeritus in computer science and a University Distinguished Teaching Professor Emeritus at the University of Texas at Austin. Professionally he is known for his contributions to the formal aspects of concurrent programming and for jointly spearheading, with Sir Tony Hoare, the project on Verified Software Initiative (VSI).
Arun K. Somani is Associate Dean for Research of College of Engineering, Distinguished Professor of Electrical and Computer Engineering and Philip and Virginia Sproul Professor at Iowa State University. Somani is Elected Fellow of Institute of Electrical and Electronics Engineers (IEEE) for “contributions to theory and applications of computer networks” from 1999 to 2017 and Life Fellow of IEEE since 2018. He is Distinguished Engineer of Association for Computing Machinery(ACM) and Elected Fellow of The American Association for the Advancement of Science(AAAS).
References
- ↑ Habib M. Ammari, ed. (2019). Mission-Oriented Sensor Networks and Systems: Art and Science. Springer International Publishing. pp. 277–279. ISBN 9783319911465.
- ↑ Sharkh, M.A.; Jammal, M.; Shami, A.; Ouda, A. (2013). "Resource allocation in a network-based cloud computing environment: design challenges". IEEE Communications Magazine. IEEE. 51 (11): 46–52. arXiv: 1309.1208 . doi:10.1109/MCOM.2013.6658651. S2CID 17925294.
- ↑ Larry L. Peterson; Bruce S. Davie (2007). Computer Networks ISE, A Systems Approach. Elsevier Science. p. 458. ISBN 9780080502564.
- ↑ Hameed Hussain; Saif Ur Rehman Malik; Abdul Hameed; Samee Ullah Khan; Gage Bickler; Nasro Min-Allah; Muhammad Bilal Qureshi; Limin Zhang; Wang Yongji; Nasir Ghani; Joanna Kolodziej; Albert Y.Zomaya; Cheng-Zhong Xu; Pavan Balaji; Abhinav Vishnu; Fredric Pinel; Johnatan E.Pecero; Dzmitry Kliazovich; Ammar Rayes (2013). "A survey on resource allocation in high performance distributed computing systems". Parallel Computing. Elsevier. 39 (11): 709–736. doi:10.1016/j.parco.2013.09.009.