Information retrieval (IR) in computing and information science is the task of identifying and retrieving information system resources that are relevant to an information need. The information need can be specified in the form of a search query. In the case of document retrieval, queries can be based on full-text or other content-based indexing. Information retrieval is the science of searching for information in a document, searching for documents themselves, and also searching for the metadata that describes data, and for databases of texts, images or sounds.

A semantic network, or frame network is a knowledge base that represents semantic relations between concepts in a network. This is often used as a form of knowledge representation. It is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts, mapping or connecting semantic fields. A semantic network may be instantiated as, for example, a graph database or a concept map. Typical standardized semantic networks are expressed as semantic triples.

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
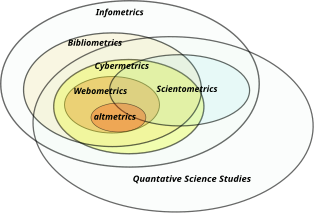
Information science or informatology is an academic field which is primarily concerned with analysis, collection, classification, manipulation, storage, retrieval, movement, dissemination, and protection of information. Practitioners within and outside the field study the application and the usage of knowledge in organizations in addition to the interaction between people, organizations, and any existing information systems with the aim of creating, replacing, improving, or understanding the information systems.
Music information retrieval (MIR) is the interdisciplinary science of retrieving information from music. Those involved in MIR may have a background in academic musicology, psychoacoustics, psychology, signal processing, informatics, machine learning, optical music recognition, computational intelligence or some combination of these.
An annotation is extra information associated with a particular point in a document or other piece of information. It can be a note that includes a comment or explanation. Annotations are sometimes presented in the margin of book pages. For annotations of different digital media, see web annotation and text annotation.
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text. A matrix containing word counts per document is constructed from a large piece of text and a mathematical technique called singular value decomposition (SVD) is used to reduce the number of rows while preserving the similarity structure among columns. Documents are then compared by cosine similarity between any two columns. Values close to 1 represent very similar documents while values close to 0 represent very dissimilar documents.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity. These are mathematical tools used to estimate the strength of the semantic relationship between units of language, concepts or instances, through a numerical description obtained according to the comparison of information supporting their meaning or describing their nature. The term semantic similarity is often confused with semantic relatedness. Semantic relatedness includes any relation between two terms, while semantic similarity only includes "is a" relations. For example, "car" is similar to "bus", but is also related to "road" and "driving".

Automatic image annotation is the process by which a computer system automatically assigns metadata in the form of captioning or keywords to a digital image. This application of computer vision techniques is used in image retrieval systems to organize and locate images of interest from a database.
Ekaterini Panagiotou Sycara is a Greek computer scientist. She is an Edward Fredkin Research Professor of Robotics in the Robotics Institute, School of Computer Science at Carnegie Mellon University internationally known for her research in artificial intelligence, particularly in the fields of negotiation, autonomous agents and multi-agent systems. She directs the Advanced Agent-Robotics Technology Lab at Robotics Institute, Carnegie Mellon University. She also serves as academic advisor for PhD students at both Robotics Institute and Tepper School of Business.
Convera was formed in December 2000 by the merger of Intel's Interactive Services division and Excalibur Technologies Corporation. Until 2007, Convera's primary focus was the enterprise search market through its flagship product, RetrievalWare, which is widely used within the secure government sector in the United States, UK, Canada and a number of other countries. Convera sold its enterprise search business to FAST Search & Transfer in August 2007 for $23 million, at which point RetrievalWare was officially retired. Microsoft Corporation continues to maintain RetrievalWare for its existing customer base.

Sir Nigel Richard Shadbolt is Principal of Jesus College, Oxford, and Professorial Research Fellow in the Department of Computer Science, University of Oxford. He is chairman of the Open Data Institute which he co-founded with Tim Berners-Lee. He is also a visiting professor in the School of Electronics and Computer Science at the University of Southampton. Shadbolt is an interdisciplinary researcher, policy expert and commentator. His research focuses on understanding how intelligent behaviour is embodied and emerges in humans, machines and, most recently, on the Web, and has made contributions to the fields of psychology, cognitive science, computational neuroscience, artificial intelligence, computer science and the emerging field of web science.
Amit Sheth is a computer scientist at University of South Carolina in Columbia, South Carolina. He is the founding Director of the Artificial Intelligence Institute, and a Professor of Computer Science and Engineering. From 2007 to June 2019, he was the Lexis Nexis Ohio Eminent Scholar, director of the Ohio Center of Excellence in Knowledge-enabled Computing, and a Professor of Computer Science at Wright State University. Sheth's work has been cited by over 48,800 publications. He has an h-index of 117, which puts him among the top 100 computer scientists with the highest h-index. Prior to founding the Kno.e.sis Center, he served as the director of the Large Scale Distributed Information Systems Lab at the University of Georgia in Athens, Georgia.
Web intelligence is the area of scientific research and development that explores the roles and makes use of artificial intelligence and information technology for new products, services and frameworks that are empowered by the World Wide Web.
Automatic indexing is the computerized process of scanning large volumes of documents against a controlled vocabulary, taxonomy, thesaurus or ontology and using those controlled terms to quickly and effectively index large electronic document depositories. These keywords or language are applied by training a system on the rules that determine what words to match. There are additional parts to this such as syntax, usage, proximity, and other algorithms based on the system and what is required for indexing. This is taken into account using Boolean statements to gather and capture the indexing information out of the text. As the number of documents exponentially increases with the proliferation of the Internet, automatic indexing will become essential to maintaining the ability to find relevant information in a sea of irrelevant information. Natural language systems are used to train a system based on seven different methods to help with this sea of irrelevant information. These methods are Morphological, Lexical, Syntactic, Numerical, Phraseological, Semantic, and Pragmatic. Each of these look and different parts of speed and terms to build a domain for the specific information that is being covered for indexing. This is used in the automated process of indexing.
William Aaron Woods, generally known as Bill Woods, is a researcher in natural language processing, continuous speech understanding, knowledge representation, and knowledge-based search technology. He is currently a Software Engineer at Google.
Text, Speech and Dialogue (TSD) is an annual conference involving topics on natural language processing and computational linguistics. The meeting is held every September alternating in Brno and Plzeň, Czech Republic.
Semantic Scholar is a research tool for scientific literature powered by artificial intelligence. It is developed at the Allen Institute for AI and was publicly released in November 2015. Semantic Scholar uses modern techniques in natural language processing to support the research process, for example by providing automatically generated summaries of scholarly papers. The Semantic Scholar team is actively researching the use of artificial intelligence in natural language processing, machine learning, human–computer interaction, and information retrieval.
Gregory Grefenstette is a French–American researcher and professor in computer science, in particular artificial intelligence and natural language processing. As of 2020, he is the chief scientific officer at Biggerpan, a company developing a predictive contextual engine for the mobile web. Grefenstette is also a senior associate researcher at the Florida Institute for Human and Machine Cognition (IHMC).
