
In probability theory and statistics, variance is the expectation of the squared deviation of a random variable from its mean. Informally, it measures how far a set of (random) numbers are spread out from their average value. Variance has a central role in statistics, where some ideas that use it include descriptive statistics, statistical inference, hypothesis testing, goodness of fit, and Monte Carlo sampling. Variance is an important tool in the sciences, where statistical analysis of data is common. The variance is the square of the standard deviation, the second central moment of a distribution, and the covariance of the random variable with itself, and it is often represented by , , or .
In linear algebra, the trace of an square matrix is defined to be the sum of the elements on the main diagonal of .

In probability theory and statistics, the exponential distribution is the probability distribution that describes the time between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.

In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables each of which clusters around a mean value.
In computer science's combinatory logic, a fixed-point combinator is a higher-order function fix that, for any function f that has an attractive fixed point, returns a fixed point x of that function. A fixed point of a function is a value that, when applied as the input of the function, returns the same value as its output.

In mathematics, the unitary group of degree n, denoted U(n), is the group of n × n unitary matrices, with the group operation of matrix multiplication. The unitary group is a subgroup of the general linear group GL(n, C). Hyperorthogonal group is an archaic name for the unitary group, especially over finite fields. For the group of unitary matrices with determinant 1, see Special unitary group.

The Erlang distribution is a two-parameter family of continuous probability distributions with support . The two parameters are:

In probability theory and statistics, the Weibull distribution is a continuous probability distribution. It is named after Swedish mathematician Waloddi Weibull, who described it in detail in 1951, although it was first identified by Fréchet (1927) and first applied by Rosin & Rammler (1933) to describe a particle size distribution.
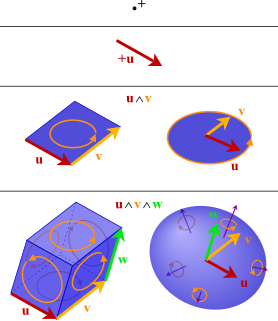
In mathematics, the exterior product or wedge product of vectors is an algebraic construction used in geometry to study areas, volumes, and their higher-dimensional analogues. The exterior product of two vectors u and v, denoted by u ∧ v, is called a bivector and lives in a space called the exterior square, a vector space that is distinct from the original space of vectors. The magnitude of u ∧ v can be interpreted as the area of the parallelogram with sides u and v, which in three dimensions can also be computed using the cross product of the two vectors. Like the cross product, the exterior product is anticommutative, meaning that u ∧ v = −(v ∧ u) for all vectors u and v, but, unlike the cross product, the exterior product is associative. One way to visualize a bivector is as a family of parallelograms all lying in the same plane, having the same area, and with the same orientation—a choice of clockwise or counterclockwise.

In mathematics, Jensen's inequality, named after the Danish mathematician Johan Jensen, relates the value of a convex function of an integral to the integral of the convex function. It was proven by Jensen in 1906. Given its generality, the inequality appears in many forms depending on the context, some of which are presented below. In its simplest form the inequality states that the convex transformation of a mean is less than or equal to the mean applied after convex transformation; it is a simple corollary that the opposite is true of concave transformations.
In statistics, the Rao–Blackwell theorem, sometimes referred to as the Rao–Blackwell–Kolmogorov theorem, is a result which characterizes the transformation of an arbitrarily crude estimator into an estimator that is optimal by the mean-squared-error criterion or any of a variety of similar criteria.
In probability theory, a compound Poisson distribution is the probability distribution of the sum of a number of independent identically-distributed random variables, where the number of terms to be added is itself a Poisson-distributed variable. In the simplest cases, the result can be either a continuous or a discrete distribution.
In Bayesian probability, the Jeffreys prior, named after Sir Harold Jeffreys, is a non-informative (objective) prior distribution for a parameter space; it is proportional to the square root of the determinant of the Fisher information matrix:
Lambda lifting is a meta-process that restructures a computer program so that functions are defined independently of each other in a global scope. An individual "lift" transforms a local function into a global function. It is a two step process, consisting of;
In mathematics, Church encoding is a means of representing data and operators in the lambda calculus. The Church numerals are a representation of the natural numbers using lambda notation. The method is named for Alonzo Church, who first encoded data in the lambda calculus this way.
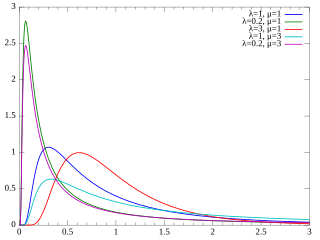
In probability theory, the inverse Gaussian distribution is a two-parameter family of continuous probability distributions with support on (0,∞).
In statistics, the bias of an estimator is the difference between this estimator's expected value and the true value of the parameter being estimated. An estimator or decision rule with zero bias is called unbiased. Otherwise the estimator is said to be biased. In statistics, "bias" is an objective property of an estimator, and while not a desired property, it is not pejorative, unlike the ordinary English use of the term "bias".

In probability theory and statistics, the Conway–Maxwell–Poisson distribution is a discrete probability distribution named after Richard W. Conway, William L. Maxwell, and Siméon Denis Poisson that generalizes the Poisson distribution by adding a parameter to model overdispersion and underdispersion. It is a member of the exponential family, has the Poisson distribution and geometric distribution as special cases and the Bernoulli distribution as a limiting case.

In probability theory and statistics, the Poisson distribution, named after French mathematician Siméon Denis Poisson, is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time or space if these events occur with a known constant rate and independently of the time since the last event. The Poisson distribution can also be used for the number of events in other specified intervals such as distance, area or volume.
In computer science, a "let" expression associates a function definition with a restricted scope.



