
An object database is a database management system in which information is represented in the form of objects as used in object-oriented programming. Object databases are different from relational databases which are table-oriented. Object-relational databases are a hybrid of both approaches.
The Semantic Web is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable. To enable the encoding of semantics with the data, technologies such as Resource Description Framework (RDF) and Web Ontology Language (OWL) are used. These technologies are used to formally represent metadata. For example, ontology can describe concepts, relationships between entities, and categories of things. These embedded semantics offer significant advantages such as reasoning over data and operating with heterogeneous data sources.
Extensible Markup Language (XML) is a markup language that defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium's XML 1.0 Specification of 1998 and several other related specifications—all of them free open standards—define XML.
XSLT is a language for transforming XML documents into other XML documents, or other formats such as HTML for web pages, plain text or XSL Formatting Objects, which may subsequently be converted to other formats, such as PDF, PostScript and PNG. XSLT 1.0 is widely supported in modern web browsers.
XSD, a recommendation of the World Wide Web Consortium (W3C), specifies how to formally describe the elements in an Extensible Markup Language (XML) document. It can be used by programmers to verify each piece of item content in a document. They can check if it adheres to the description of the element it is placed in.
The Geography Markup Language (GML) is the XML grammar defined by the Open Geospatial Consortium (OGC) to express geographical features. GML serves as a modeling language for geographic systems as well as an open interchange format for geographic transactions on the Internet. Key to GML's utility is its ability to integrate all forms of geographic information, including not only conventional "vector" or discrete objects, but coverages and sensor data.
An XML schema is a description of a type of XML document, typically expressed in terms of constraints on the structure and content of documents of that type, above and beyond the basic syntactical constraints imposed by XML itself. These constraints are generally expressed using some combination of grammatical rules governing the order of elements, Boolean predicates that the content must satisfy, data types governing the content of elements and attributes, and more specialized rules such as uniqueness and referential integrity constraints.
XPath 2.0 is a version of the XPath language defined by the World Wide Web Consortium, W3C. It became a recommendation on 23 January 2007. As a W3C Recommendation it was superseded by XPath 3.0 on 10 April 2014.
An XML database is a data persistence software system that allows data to be specified, and sometimes stored, in XML format. This data can be queried, transformed, exported and returned to a calling system. XML databases are a flavor of document-oriented databases which are in turn a category of NoSQL database.
SPARQL is an RDF query language—that is, a semantic query language for databases—able to retrieve and manipulate data stored in Resource Description Framework (RDF) format. It was made a standard by the RDF Data Access Working Group (DAWG) of the World Wide Web Consortium, and is recognized as one of the key technologies of the semantic web. On 15 January 2008, SPARQL 1.0 was acknowledged by W3C as an official recommendation, and SPARQL 1.1 in March, 2013.
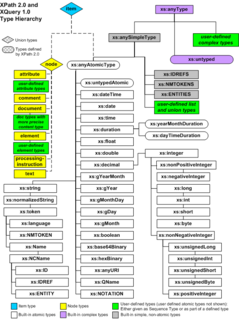
The XQuery and XPath Data Model (XDM) is the data model shared by the XPath 2.0, XSLT 2.0, XQuery, and XForms programming languages. It is defined in a W3C recommendation. Originally, it was based on the XPath 1.0 data model which in turn is based on the XML Information Set.
An RDF query language is a computer language, specifically a query language for databases, able to retrieve and manipulate data stored in Resource Description Framework (RDF) format.
Transaction Processing over XML (TPoX) is a computing benchmark for XML database systems. As a benchmark, TPoX is used for the performance testing of database management systems that are capable of storing, searching, modifying and retrieving XML data. The goal of TPoX is to allow database designers, developers and users to evaluate the performance of XML database features, such as the XML query languages XQuery and SQL/XML, XML storage, XML indexing, XML Schema support, XML updates, transaction processing and logging, and concurrency control. TPoX includes XML update tests based on the XQuery Update Facility.
XPath is a query language for selecting nodes from an XML document. In addition, XPath may be used to compute values from the content of an XML document. XPath was defined by the World Wide Web Consortium (W3C).
pureXML is the native XML storage feature in the IBM DB2 data server. pureXML provides query languages, storage technologies, indexing technologies, and other features to support XML data. The word pure in pureXML was chosen to indicate that DB2 natively stores and natively processes XML data in its inherent hierarchical structure, as opposed to treating XML data as plain text or converting it into a relational format.
XML retrieval, or XML information retrieval, is the content-based retrieval of documents structured with XML. As such it is used for computing relevance of XML documents.
XQuery is a query and functional programming language that queries and transforms collections of structured and unstructured data, usually in the form of XML, text and with vendor-specific extensions for other data formats. The language is developed by the XML Query working group of the W3C. The work is closely coordinated with the development of XSLT by the XSL Working Group; the two groups share responsibility for XPath, which is a subset of XQuery.

XQuery API for Java (XQJ) refers to the common Java API for the W3C XQuery 1.0 specification.

An XML transformation language is a programming language designed specifically to transform an input XML document into an output document which satisfies some specific goal.
JSONiq is a query and functional programming language that is designed to declaratively query and transform collections of hierarchical and heterogeneous data in format of JSON, XML, as well as unstructured, textual data.
