In mathematics, a linear map is a mapping V → W between two modules that preserves the operations of addition and scalar multiplication. If a linear map is a bijection then it is called a linear isomorphism.

In physics, the Lorentz transformations are a one-parameter family of linear transformations from a coordinate frame in spacetime to another frame that moves at a constant velocity relative to the former. The respective inverse transformation is then parametrized by the negative of this velocity. The transformations are named after the Dutch physicist Hendrik Lorentz.
A statistical model is a mathematical model that embodies a set of statistical assumptions concerning the generation of sample data. A statistical model represents, often in considerably idealized form, the data-generating process.
In statistics, the likelihood function measures the goodness of fit of a statistical model to a sample of data for given values of the unknown parameters. It is formed from the joint probability distribution of the sample, but viewed and used as a function of the parameters only, thus treating the random variables as fixed at the observed values.

In physics and mathematics, the Lorentz group is the group of all Lorentz transformations of Minkowski spacetime, the classical and quantum setting for all (non-gravitational) physical phenomena. The Lorentz group is named for the Dutch physicist Hendrik Lorentz.
In mathematics and theoretical physics, the term quantum group denotes one of a few different kinds of noncommutative algebras with additional structure. These include Drinfeld–Jimbo type quantum groups, compact matrix quantum groups, and bicrossproduct quantum groups.
In Bayesian probability theory, if the posterior distributions p(θ | x) are in the same probability distribution family as the prior probability distribution p(θ), the prior and posterior are then called conjugate distributions, and the prior is called a conjugate prior for the likelihood function p(x | θ). For example, the Gaussian family is conjugate to itself with respect to a Gaussian likelihood function: if the likelihood function is Gaussian, choosing a Gaussian prior over the mean will ensure that the posterior distribution is also Gaussian. This means that the Gaussian distribution is a conjugate prior for the likelihood that is also Gaussian. The concept, as well as the term "conjugate prior", were introduced by Howard Raiffa and Robert Schlaifer in their work on Bayesian decision theory. A similar concept had been discovered independently by George Alfred Barnard.
In statistics, a mixture model is a probabilistic model for representing the presence of subpopulations within an overall population, without requiring that an observed data set should identify the sub-population to which an individual observation belongs. Formally a mixture model corresponds to the mixture distribution that represents the probability distribution of observations in the overall population. However, while problems associated with "mixture distributions" relate to deriving the properties of the overall population from those of the sub-populations, "mixture models" are used to make statistical inferences about the properties of the sub-populations given only observations on the pooled population, without sub-population identity information.

In probability theory and statistics, the generalized inverse Gaussian distribution (GIG) is a three-parameter family of continuous probability distributions with probability density function
In statistics, a parametric model or parametric family or finite-dimensional model is a particular class of statistical models. Specifically, a parametric model is a family of probability distributions that has a finite number of parameters.
In relativity, rapidity is commonly used as a measure for relativistic velocity. Mathematically, rapidity can be defined as the hyperbolic angle that differentiates two frames of reference in relative motion, each frame being associated with distance and time coordinates.

In statistics, semiparametric regression includes regression models that combine parametric and nonparametric models. They are often used in situations where the fully nonparametric model may not perform well or when the researcher wants to use a parametric model but the functional form with respect to a subset of the regressors or the density of the errors is not known. Semiparametric regression models are a particular type of semiparametric modelling and, since semiparametric models contain a parametric component, they rely on parametric assumptions and may be misspecified and inconsistent, just like a fully parametric model.
Proportional hazards models are a class of survival models in statistics. Survival models relate the time that passes, before some event occurs, to one or more covariates that may be associated with that quantity of time. In a proportional hazards model, the unique effect of a unit increase in a covariate is multiplicative with respect to the hazard rate. For example, taking a drug may halve one's hazard rate for a stroke occurring, or, changing the material from which a manufactured component is constructed may double its hazard rate for failure. Other types of survival models such as accelerated failure time models do not exhibit proportional hazards. The accelerated failure time model describes a situation where the biological or mechanical life history of an event is accelerated.
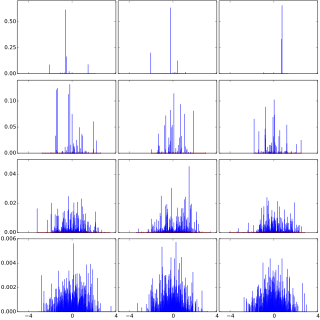
In probability theory, Dirichlet processes are a family of stochastic processes whose realizations are probability distributions. In other words, a Dirichlet process is a probability distribution whose range is itself a set of probability distributions. It is often used in Bayesian inference to describe the prior knowledge about the distribution of random variables—how likely it is that the random variables are distributed according to one or another particular distribution.
The possibility that there might be more than one dimension of time has occasionally been discussed in physics and philosophy.
In statistics, principal component regression (PCR) is a regression analysis technique that is based on principal component analysis (PCA). More specifically, PCR is used for estimating the unknown regression coefficients in a standard linear regression model.
In statistics, errors-in-variables models or measurement error models are regression models that account for measurement errors in the independent variables. In contrast, standard regression models assume that those regressors have been measured exactly, or observed without error; as such, those models account only for errors in the dependent variables, or responses.
In statistics, the Hájek–Le Cam convolution theorem states that any regular estimator in a parametric model is asymptotically equivalent to a sum of two independent random variables, one of which is normal with asymptotic variance equal to the inverse of Fisher information, and the other having arbitrary distribution.
In probability theory, an interacting particle system (IPS) is a stochastic process on some configuration space given by a site space, a countable-infinite graph and a local state space, a compact metric space . More precisely IPS are continuous-time Markov jump processes describing the collective behavior of stochastically interacting components. IPS are the continuous-time analogue of stochastic cellular automata.
In statistics, the variance function is a smooth function which depicts the variance of a random quantity as a function of its mean. The variance function plays a large role in many settings of statistical modelling. It is a main ingredient in the generalized linear model framework and a tool used in non-parametric regression, semiparametric regression and functional data analysis. In parametric modeling, variance functions take on a parametric form and explicitly describe the relationship between the variance and the mean of a random quantity. In a non-parametric setting, the variance function is assumed to be a smooth function.












