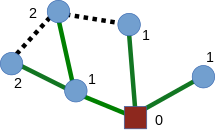
Dijkstra's algorithm is an algorithm for finding the shortest paths between nodes in a weighted graph, which may represent, for example, road networks. It was conceived by computer scientist Edsger W. Dijkstra in 1956 and published three years later.

In graph theory, a tree is an undirected graph in which any two vertices are connected by exactly one path, or equivalently a connected acyclic undirected graph. A forest is an undirected graph in which any two vertices are connected by at most one path, or equivalently an acyclic undirected graph, or equivalently a disjoint union of trees.

Breadth-first search (BFS) is an algorithm for searching a tree data structure for a node that satisfies a given property. It starts at the tree root and explores all nodes at the present depth prior to moving on to the nodes at the next depth level. Extra memory, usually a queue, is needed to keep track of the child nodes that were encountered but not yet explored.

The Bellman–Ford algorithm is an algorithm that computes shortest paths from a single source vertex to all of the other vertices in a weighted digraph. It is slower than Dijkstra's algorithm for the same problem, but more versatile, as it is capable of handling graphs in which some of the edge weights are negative numbers. The algorithm was first proposed by Alfonso Shimbel (1955), but is instead named after Richard Bellman and Lester Ford Jr., who published it in 1958 and 1956, respectively. Edward F. Moore also published a variation of the algorithm in 1959, and for this reason it is also sometimes called the Bellman–Ford–Moore algorithm.
In computer science, the Floyd–Warshall algorithm is an algorithm for finding shortest paths in a directed weighted graph with positive or negative edge weights. A single execution of the algorithm will find the lengths of shortest paths between all pairs of vertices. Although it does not return details of the paths themselves, it is possible to reconstruct the paths with simple modifications to the algorithm. Versions of the algorithm can also be used for finding the transitive closure of a relation , or widest paths between all pairs of vertices in a weighted graph.
This is a glossary of graph theory. Graph theory is the study of graphs, systems of nodes or vertices connected in pairs by lines or edges.
In computer science, a topological sort or topological ordering of a directed graph is a linear ordering of its vertices such that for every directed edge uv from vertex u to vertex v, u comes before v in the ordering. For instance, the vertices of the graph may represent tasks to be performed, and the edges may represent constraints that one task must be performed before another; in this application, a topological ordering is just a valid sequence for the tasks. Precisely, a topological sort is a graph traversal in which each node v is visited only after all its dependencies are visited. A topological ordering is possible if and only if the graph has no directed cycles, that is, if it is a directed acyclic graph (DAG). Any DAG has at least one topological ordering, and algorithms are known for constructing a topological ordering of any DAG in linear time. Topological sorting has many applications especially in ranking problems such as feedback arc set. Topological sorting is possible even when the DAG has disconnected components.
In the mathematical field of graph theory, the distance between two vertices in a graph is the number of edges in a shortest path connecting them. This is also known as the geodesic distance or shortest-path distance. Notice that there may be more than one shortest path between two vertices. If there is no path connecting the two vertices, i.e., if they belong to different connected components, then conventionally the distance is defined as infinite.
Johnson's algorithm is a way to find the shortest paths between all pairs of vertices in an edge-weighted directed graph. It allows some of the edge weights to be negative numbers, but no negative-weight cycles may exist. It works by using the Bellman–Ford algorithm to compute a transformation of the input graph that removes all negative weights, allowing Dijkstra's algorithm to be used on the transformed graph. It is named after Donald B. Johnson, who first published the technique in 1977.
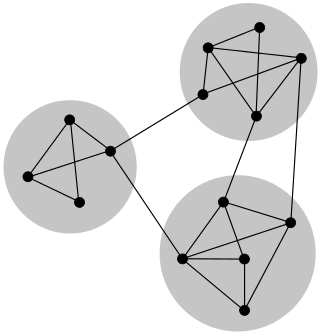
In mathematics and computer science, connectivity is one of the basic concepts of graph theory: it asks for the minimum number of elements that need to be removed to separate the remaining nodes into two or more isolated subgraphs. It is closely related to the theory of network flow problems. The connectivity of a graph is an important measure of its resilience as a network.
In computer science, the Hopcroft–Karp algorithm is an algorithm that takes a bipartite graph as input and produces a maximum-cardinality matching as output — a set of as many edges as possible with the property that no two edges share an endpoint. It runs in time in the worst case, where is set of edges in the graph, is set of vertices of the graph, and it is assumed that . In the case of dense graphs the time bound becomes , and for sparse random graphs it runs in time with high probability.
In computer science, graph traversal refers to the process of visiting each vertex in a graph. Such traversals are classified by the order in which the vertices are visited. Tree traversal is a special case of graph traversal.

In graph theory, a branch of mathematics, the triconnected components of a biconnected graph are a system of smaller graphs that describe all of the 2-vertex cuts in the graph. An SPQR tree is a tree data structure used in computer science, and more specifically graph algorithms, to represent the triconnected components of a graph. The SPQR tree of a graph may be constructed in linear time and has several applications in dynamic graph algorithms and graph drawing.
In graph theory, the planar separator theorem is a form of isoperimetric inequality for planar graphs, that states that any planar graph can be split into smaller pieces by removing a small number of vertices. Specifically, the removal of vertices from an n-vertex graph can partition the graph into disjoint subgraphs each of which has at most vertices.

In graph theory, a branch of mathematics, a squaregraph is a type of undirected graph that can be drawn in the plane in such a way that every bounded face is a quadrilateral and every vertex with three or fewer neighbors is incident to an unbounded face.
In graph theory, the blossom algorithm is an algorithm for constructing maximum matchings on graphs. The algorithm was developed by Jack Edmonds in 1961, and published in 1965. Given a general graph G = (V, E), the algorithm finds a matching M such that each vertex in V is incident with at most one edge in M and |M| is maximized. The matching is constructed by iteratively improving an initial empty matching along augmenting paths in the graph. Unlike bipartite matching, the key new idea is that an odd-length cycle in the graph (blossom) is contracted to a single vertex, with the search continuing iteratively in the contracted graph.

In graph theory, a branch of combinatorial mathematics, a block graph or clique tree is a type of undirected graph in which every biconnected component (block) is a clique.
In theoretical computer science and network routing, Suurballe's algorithm is an algorithm for finding two disjoint paths in a nonnegatively-weighted directed graph, so that both paths connect the same pair of vertices and have minimum total length. The algorithm was conceived by John W. Suurballe and published in 1974. The main idea of Suurballe's algorithm is to use Dijkstra's algorithm to find one path, to modify the weights of the graph edges, and then to run Dijkstra's algorithm a second time. The output of the algorithm is formed by combining these two paths, discarding edges that are traversed in opposite directions by the paths, and using the remaining edges to form the two paths to return as the output. The modification to the weights is similar to the weight modification in Johnson's algorithm, and preserves the non-negativity of the weights while allowing the second instance of Dijkstra's algorithm to find the correct second path.
In computer science, the method of contraction hierarchies is a speed-up technique for finding the shortest-path in a graph. The most intuitive applications are car-navigation systems: a user wants to drive from to using the quickest possible route. The metric optimized here is the travel time. Intersections are represented by vertices, the road sections connecting them by edges. The edge weights represent the time it takes to drive along this segment of the road. A path from to is a sequence of edges ; the shortest path is the one with the minimal sum of edge weights among all possible paths. The shortest path in a graph can be computed using Dijkstra's algorithm but, given that road networks consist of tens of millions of vertices, this is impractical. Contraction hierarchies is a speed-up method optimized to exploit properties of graphs representing road networks. The speed-up is achieved by creating shortcuts in a preprocessing phase which are then used during a shortest-path query to skip over "unimportant" vertices. This is based on the observation that road networks are highly hierarchical. Some intersections, for example highway junctions, are "more important" and higher up in the hierarchy than for example a junction leading into a dead end. Shortcuts can be used to save the precomputed distance between two important junctions such that the algorithm doesn't have to consider the full path between these junctions at query time. Contraction hierarchies do not know about which roads humans consider "important", but they are provided with the graph as input and are able to assign importance to vertices using heuristics.
The Shortest Path Faster Algorithm (SPFA) is an improvement of the Bellman–Ford algorithm which computes single-source shortest paths in a weighted directed graph. The algorithm is believed to work well on random sparse graphs and is particularly suitable for graphs that contain negative-weight edges. However, the worst-case complexity of SPFA is the same as that of Bellman–Ford, so for graphs with nonnegative edge weights Dijkstra's algorithm is preferred. The SPFA algorithm was first published by Edward F. Moore in 1959, as a generalization of breadth first search; SPFA is Moore's “Algorithm D.” The name, “Shortest Path Faster Algorithm (SPFA),” was given by FanDing Duan, a Chinese researcher who rediscovered the algorithm in 1994.