In mathematics and computer programming, exponentiating by squaring is a general method for fast computation of large positive integer powers of a number, or more generally of an element of a semigroup, like a polynomial or a square matrix. Some variants are commonly referred to as square-and-multiply algorithms or binary exponentiation. These can be of quite general use, for example in modular arithmetic or powering of matrices. For semigroups for which additive notation is commonly used, like elliptic curves used in cryptography, this method is also referred to as double-and-add.

In probability and statistics, a Bernoulli process is a finite or infinite sequence of binary random variables, so it is a discrete-time stochastic process that takes only two values, canonically 0 and 1. The component Bernoulli variablesXi are identically distributed and independent. Prosaically, a Bernoulli process is a repeated coin flipping, possibly with an unfair coin. Every variable Xi in the sequence is associated with a Bernoulli trial or experiment. They all have the same Bernoulli distribution. Much of what can be said about the Bernoulli process can also be generalized to more than two outcomes ; this generalization is known as the Bernoulli scheme.

In probability theory and statistics, the Bernoulli distribution, named after Swiss mathematician Jacob Bernoulli, is the discrete probability distribution of a random variable which takes the value 1 with probability and the value 0 with probability . Less formally, it can be thought of as a model for the set of possible outcomes of any single experiment that asks a yes–no question. Such questions lead to outcomes that are Boolean-valued: a single bit whose value is success/yes/true/one with probability p and failure/no/false/zero with probability q. It can be used to represent a coin toss where 1 and 0 would represent "heads" and "tails", respectively, and p would be the probability of the coin landing on heads. In particular, unfair coins would have
The bin packing problem is an optimization problem, in which items of different sizes must be packed into a finite number of bins or containers, each of a fixed given capacity, in a way that minimizes the number of bins used. The problem has many applications, such as filling up containers, loading trucks with weight capacity constraints, creating file backups in media, splitting a network prefix into multiple subnets, and technology mapping in FPGA semiconductor chip design.
In numerical analysis and computational statistics, rejection sampling is a basic technique used to generate observations from a distribution. It is also commonly called the acceptance-rejection method or "accept-reject algorithm" and is a type of exact simulation method. The method works for any distribution in with a density.
In electrical engineering, statistical computing and bioinformatics, the Baum–Welch algorithm is a special case of the expectation–maximization algorithm used to find the unknown parameters of a hidden Markov model (HMM). It makes use of the forward-backward algorithm to compute the statistics for the expectation step.
In machine learning, backpropagation is a gradient estimation method commonly used for training neural networks to compute the network parameter updates.
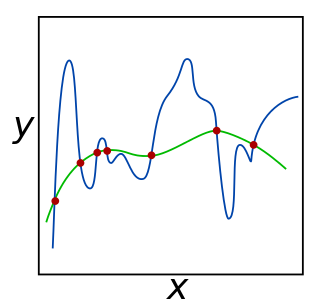
In mathematics, statistics, finance, and computer science, particularly in machine learning and inverse problems, regularization is a process that converts the answer of a problem to a simpler one. It is often used in solving ill-posed problems or to prevent overfitting.
In probability theory, if a large number of events are all independent of one another and each has probability less than 1, then there is a positive probability that none of the events will occur. The Lovász local lemma allows one to relax the independence condition slightly: As long as the events are "mostly" independent from one another and aren't individually too likely, then there will still be a positive probability that none of them occurs. It is most commonly used in the probabilistic method, in particular to give existence proofs.
The cross-entropy (CE) method is a Monte Carlo method for importance sampling and optimization. It is applicable to both combinatorial and continuous problems, with either a static or noisy objective.
TCP-Illinois is a variant of TCP congestion control protocol, developed at the University of Illinois at Urbana–Champaign. It is especially targeted at high-speed, long-distance networks. A sender side modification to the standard TCP congestion control algorithm, it achieves a higher average throughput than the standard TCP, allocates the network resource fairly as the standard TCP, is compatible with the standard TCP, and provides incentives for TCP users to switch.
Stochastic approximation methods are a family of iterative methods typically used for root-finding problems or for optimization problems. The recursive update rules of stochastic approximation methods can be used, among other things, for solving linear systems when the collected data is corrupted by noise, or for approximating extreme values of functions which cannot be computed directly, but only estimated via noisy observations.

In computer science and graph theory, Karger's algorithm is a randomized algorithm to compute a minimum cut of a connected graph. It was invented by David Karger and first published in 1993.
The Price of Anarchy (PoA) is a concept in economics and game theory that measures how the efficiency of a system degrades due to selfish behavior of its agents. It is a general notion that can be extended to diverse systems and notions of efficiency. For example, consider the system of transportation of a city and many agents trying to go from some initial location to a destination. Here, efficiency means the average time for an agent to reach the destination. In the 'centralized' solution, a central authority can tell each agent which path to take in order to minimize the average travel time. In the 'decentralized' version, each agent chooses its own path. The Price of Anarchy measures the ratio between average travel time in the two cases.
Within theoretical computer science, the Sun–Ni law is a memory-bounded speedup model which states that as computing power increases the corresponding increase in problem size is constrained by the system’s memory capacity. In general, as a system grows in computational power, the problems run on the system increase in size. Analogous to Amdahl's law, which says that the problem size remains constant as system sizes grow, and Gustafson's law, which proposes that the problem size should scale but be bound by a fixed amount of time, the Sun–Ni law states the problem size should scale but be bound by the memory capacity of the system. Sun–Ni law was initially proposed by Xian-He Sun and Lionel Ni at the Proceedings of IEEE Supercomputing Conference 1990.
MAXEkSAT is a problem in computational complexity theory that is a maximization version of the Boolean satisfiability problem 3SAT. In MAXEkSAT, each clause has exactly k literals, each with distinct variables, and is in conjunctive normal form. These are called k-CNF formulas. The problem is to determine the maximum number of clauses that can be satisfied by a truth assignment to the variables in the clauses.
The maximum coverage problem is a classical question in computer science, computational complexity theory, and operations research. It is a problem that is widely taught in approximation algorithms.
The List Update or the List Access problem is a simple model used in the study of competitive analysis of online algorithms. Given a set of items in a list where the cost of accessing an item is proportional to its distance from the head of the list, e.g. a linked List, and a request sequence of accesses, the problem is to come up with a strategy of reordering the list so that the total cost of accesses is minimized. The reordering can be done at any time but incurs a cost. The standard model includes two reordering actions:
In PAC learning, error tolerance refers to the ability of an algorithm to learn when the examples received have been corrupted in some way. In fact, this is a very common and important issue since in many applications it is not possible to access noise-free data. Noise can interfere with the learning process at different levels: the algorithm may receive data that have been occasionally mislabeled, or the inputs may have some false information, or the classification of the examples may have been maliciously adulterated.
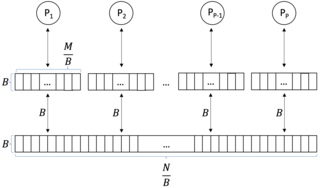
In computer science, a parallel external memory (PEM) model is a cache-aware, external-memory abstract machine. It is the parallel-computing analogy to the single-processor external memory (EM) model. In a similar way, it is the cache-aware analogy to the parallel random-access machine (PRAM). The PEM model consists of a number of processors, together with their respective private caches and a shared main memory.














