Speech processing is the study of speech signals and the processing methods of signals. The signals are usually processed in a digital representation, so speech processing can be regarded as a special case of digital signal processing, applied to speech signals. Aspects of speech processing includes the acquisition, manipulation, storage, transfer and output of speech signals. Different speech processing tasks include speech recognition, speech synthesis, speaker diarization, speech enhancement, speaker recognition, etc.
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. It is also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text (STT). It incorporates knowledge and research in the computer science, linguistics and computer engineering fields. The reverse process is speech synthesis.
Orange is an open-source data visualization, machine learning and data mining toolkit. It features a visual programming front-end for exploratory qualitative data analysis and interactive data visualization.
ITK is a cross-platform, open-source application development framework widely used for the development of image segmentation and image registration programs. Segmentation is the process of identifying and classifying data found in a digitally sampled representation. Typically the sampled representation is an image acquired from such medical instrumentation as CT or MRI scanners. Registration is the task of aligning or developing correspondences between data. For example, in the medical environment, a CT scan may be aligned with an MRI scan in order to combine the information contained in both.
Speech segmentation is the process of identifying the boundaries between words, syllables, or phonemes in spoken natural languages. The term applies both to the mental processes used by humans, and to artificial processes of natural language processing.
Transcriber is an open-source software tool for the transcription and annotation of speech signals for linguistic research. It supports multiple hierarchical layers of segmentation, named entity annotation, speaker lists, topic lists, and overlapping speakers. Two views of the sound pressure waveform at different resolutions may be viewed simultaneously. Various character encodings, including Unicode, are supported.
Automatic pronunciation assessment is the use of speech recognition to verify the correctness of pronounced speech, as distinguished from manual assessment by an instructor or proctor. Also called speech verification, pronunciation evaluation, and pronunciation scoring, the main application of this technology is computer-aided pronunciation teaching (CAPT) when combined with computer-aided instruction for computer-assisted language learning (CALL), speech remediation, or accent reduction. Pronunciation assessment does not determine unknown speech but instead, knowing the expected word(s) in advance, it attempts to verify the correctness of the learner's pronunciation and ideally their intelligibility to listeners, sometimes along with often inconsequential prosody such as intonation, pitch, tempo, rhythm, and syllable and word stress. Pronunciation assessment is also used in reading tutoring, for example in products such as Microsoft Teams and from Amira Learning. Automatic pronunciation assessment can also be used to help diagnose and treat speech disorders such as apraxia.
As of the early 2000s, several speech recognition (SR) software packages exist for Linux. Some of them are free and open-source software and others are proprietary software. Speech recognition usually refers to software that attempts to distinguish thousands of words in a human language. Voice control may refer to software used for communicating operational commands to a computer.

3D Slicer (Slicer) is a free and open source software package for image analysis and scientific visualization. Slicer is used in a variety of medical applications, including autism, multiple sclerosis, systemic lupus erythematosus, prostate cancer, lung cancer, breast cancer, schizophrenia, orthopedic biomechanics, COPD, cardiovascular disease and neurosurgery.

In computer science, Orfeo Toolbox (OTB) is a software library for processing images from Earth observation satellites.

Exaile is a cross-platform free and open-source audio player, tag editor and library organizer. It was originally conceived to be similar in style and functions to KDE's Amarok 1.4, but uses the GTK widget toolkit rather than Qt. It is written in Python and utilizes the GStreamer media framework.
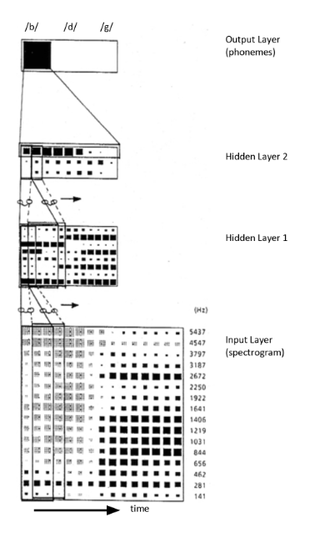
Time delay neural network (TDNN) is a multilayer artificial neural network architecture whose purpose is to 1) classify patterns with shift-invariance, and 2) model context at each layer of the network.
Speech enhancement aims to improve speech quality by using various algorithms. The objective of enhancement is improvement in intelligibility and/or overall perceptual quality of degraded speech signal using audio signal processing techniques.

Puddletag is a graphical audio file metadata editor ("tagger") for Unix-like operating systems.
In signal processing, Feature space Maximum Likelihood Linear Regression (fMLLR) is a global feature transform that are typically applied in a speaker adaptive way, where fMLLR transforms acoustic features to speaker adapted features by a multiplication operation with a transformation matrix. In some literature, fMLLR is also known as the Constrained Maximum Likelihood Linear Regression (cMLLR).

Stephen John Young is a British researcher, Professor of Information Engineering at the University of Cambridge and an entrepreneur. He is one of the pioneers of automated speech recognition and statistical spoken dialogue systems. He served as the Senior Pro-Vice-Chancellor of the University of Cambridge from 2009 to 2015, responsible for planning and resources. From 2015 to 2019, he held a joint appointment between his professorship at Cambridge and Apple, where he was a senior member of the Siri development team.
openSMILE is source-available software for automatic extraction of features from audio signals and for classification of speech and music signals. "SMILE" stands for "Speech & Music Interpretation by Large-space Extraction". The software is mainly applied in the area of automatic emotion recognition and is widely used in the affective computing research community. The openSMILE project exists since 2008 and is maintained by the German company audEERING GmbH since 2013. openSMILE is provided free of charge for research purposes and personal use under a source-available license. For commercial use of the tool, the company audEERING offers custom license options.

SimpleITK is a simplified, open-source interface to the Insight Segmentation and Registration Toolkit (ITK). The SimpleITK image analysis library is available in multiple programming languages including C++, Python, R, Java, C#, Lua, Ruby and Tcl. Binary distributions are available for all three major operating systems.

Voice computing is the discipline that develops hardware or software to process voice inputs.
Deep learning speech synthesis refers to the application of deep learning models to generate natural-sounding human speech from written text (text-to-speech) or spectrum (vocoder). Deep neural networks (DNN) are trained using a large amount of recorded speech and, in the case of a text-to-speech system, the associated labels and/or input text.