Stochastic portfolio theory (SPT) is a mathematical theory for analyzing stock market structure and portfolio behavior introduced by E. Robert Fernholz in 2002. It is descriptive as opposed to normative, and is consistent with the observed behavior of actual markets. Normative assumptions, which serve as a basis for earlier theories like modern portfolio theory (MPT) and the capital asset pricing model (CAPM), are absent from SPT.
SPT uses continuous-time random processes (in particular, continuous semi-martingales) to represent the prices of individual securities. Processes with discontinuities, such as jumps, have also been incorporated* into the theory (*unverifiable claim due to missing citation!).
Stocks, portfolios and markets
SPT considers stocks and stock markets, but its methods can be applied to other classes of assets as well. A stock is represented by its price process, usually in the logarithmic representation. In the case the market is a collection of stock-price processes for each defined by a continuous semimartingale
where is an -dimensional Brownian motion(Wiener) process with , and the processes and are progressively measurable with respect to the Brownian filtration . In this representation is called the (compound) growth rate of and the covariance between and is It is frequently assumed that, for all the process is positive, locally square-integrable, and does not grow too rapidly as
The logarithmic representation is equivalent to the classical arithmetic representation which uses the rate of return however the growth rate can be a meaningful indicator of long-term performance of a financial asset, whereas the rate of return has an upward bias. The relation between the rate of return and the growth rate is
The usual convention in SPT is to assume that each stock has a single share outstanding, so represents the total capitalization of the -th stock at time and is the total capitalization of the market. Dividends can be included in this representation, but are omitted here for simplicity.
An investment strategy is a vector of bounded, progressively measurable processes; the quantity represents the proportion of total wealth invested in the -th stock at time , and is the proportion hoarded (invested in a money market with zero interest rate). Negative weights correspond to short positions. The cash strategy keeps all wealth in the money market. A strategy is called portfolio, if it is fully invested in the stock market, that is holds, at all times.
The value process of a strategy is always positive and satisfies
where the process is called the excess growth rate process and is given by
This expression is non-negative for a portfolio with non-negative weights and has been used in quadratic optimization of stock portfolios, a special case of which is optimization with respect to the logarithmic utility function.
The market weight processes,
where define the market portfolio. With the initial condition the associated value process will satisfy for all
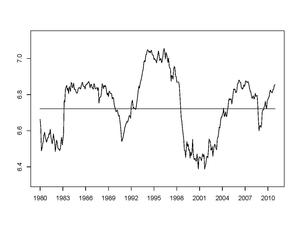
Figure 1 shows the entropy of the U.S. stock market over the period from 1980 to 2012, with the axis at the average value over the period. Although the entropy fluctuates over time, its behavior indicates that there is a certain stability to the stock market. Characterization of this stability is one of the goals of SPT.
A number of conditions can be imposed on a market, sometimes to model actual markets and sometimes to emphasize certain types of hypothetical market behavior. Some commonly invoked conditions are:
A market is nondegenerate if the eigenvalues of the covariance matrix are bounded away from zero. It has bounded variance if the eigenvalues are bounded.
A market is coherent if for all
A market is diverse on if there exists such that for
A market is weakly diverse on if there exists such that
Diversity and weak diversity are rather weak conditions, and markets are generally far more diverse than would be tested by these extremes. A measure of market diversity is market entropy, defined by
Stochastic stability
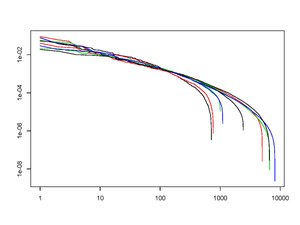
Figure 2 plots the (ranked) capital distribution curves at the end of each of the last nine decades. This log-log plot has exhibited remarkable stability over long periods of time. The study of such stability is one of the major goals of SPT. Figure 3 shows the “cumulative turnover” processes at various ranks over the course of a decade. As expected, the amount of turnover increases as one goes down the capitalization ladder. There is also a pronounced linear growth in time across all displayed ranks.
We consider the vector process with of ranked market weights
where ties are resolved “lexicographically”, always in favor of the lowest index. The log-gaps
where and are continuous, non-negative semimartingales; we denote by their local times at the origin. These quantities measure the amount of turnover between ranks and during the time-interval .
Given any two investment strategies and a real number , we say that is arbitrage relative to over the time-horizon , if and both hold; this relative arbitrage is called “strong” if When is we recover the usual definition of arbitrage relative to cash. We say that a given strategy has the numeraire property, if for any strategy the ratio is a −supermartingale. In such a case, the process is called a “deflator” for the market.
No arbitrage is possible, over any given time horizon, relative to a strategy that has the numeraire property (either with respect to the underlying probability measure , or with respect to any other probability measure which is equivalent to ). A strategy with the numeraire property maximizes the asymptotic growth rate from investment, in the sense that
holds for any strategy ; it also maximizes the expected log-utility from investment, in the sense that for any strategy and real number we have
If the vector of instantaneous rates of return, and the matrix of instantaneous covariances, are known, then the strategy
has the numeraire property whenever the indicated maximum is attained.
The study of the numeraire portfolio links SPT to the so-called Benchmark approach to Mathematical Finance, which takes such a numeraire portfolio as given and provides a way to price contingent claims, without any further assumptions.
A probability measure is called equivalent martingale measure (EMM) on a given time-horizon , if it has the same null sets as on , and if the processes with are all −martingales. Assuming that such an EMM exists, arbitrage is not possible on relative to either cash or to the market portfolio (or more generally, relative to any strategy whose wealth process is a martingale under some EMM). Conversely, if are portfolios and one of them is arbitrage relative to the other on then no EMM can exist on this horizon.
Functionally-generated portfolios
Suppose we are given a smooth function on some neighborhood of the unit simplex in . We call
the portfolio generated by the function . It can be shown that all the weights of this portfolio are non-negative, if its generating function is concave. Under mild conditions, the relative performance of this functionally-generated portfolio with respect to the market portfolio , is given by the F-G decomposition
which involves no stochastic integrals. Here the expression
is called the drift process of the portfolio (and it is a non-negative quantity if the generating function is concave); and the quantities
with are called the relative covariances between and with respect to the market.
Examples
The constant function generates the market portfolio,
The geometric mean function generates the equal-weighted portfolio for all ,
The modified entropy function for any generates the modified entropy-weighted portfolio,
The function with generates the diversity-weighted portfolio with drift process.
Arbitrage relative to the market
The excess growth rate of the market portfolio admits the representation as a capitalization-weighted average relative stock variance. This quantity is nonnegative; if it happens to be bounded away from zero, namely
for all for some real constant , then it can be shown using the F-G decomposition that, for every there exists a constant for which the modified entropic portfolio is strict arbitrage relative to the market over ; see Fernholz and Karatzas (2005) for details. It is an open question, whether such arbitrage exists over arbitrary time horizons (for two special cases, in which the answer to this question turns out to be affirmative, please see the paragraph below and the next section).
If the eigenvalues of the covariance matrix are bounded away from both zero and infinity, the condition can be shown to be equivalent to diversity, namely for a suitable Then the diversity-weighted portfolio leads to strict arbitrage relative to the market portfolio over sufficiently long time horizons; whereas, suitable modifications of this diversity-weighted portfolio realize such strict arbitrage over arbitrary time horizons.
with given real constants and an -dimensional Brownian motion It follows from the work of Bass and Perkins (2002) that this system has a weak solution, which is unique in distribution. Fernholz and Karatzas (2005) show how to construct this solution in terms of scaled and time-changed squared Bessel processes, and prove that the resulting system is coherent.
The total market capitalization behaves here as geometric Brownian motion with drift, and has the same constant growth rate as the largest stock; whereas the excess growth rate of the market portfolio is a positive constant. On the other hand, the relative market weights with have the dynamics of multi-allele Wright-Fisher processes. This model is an example of a non-diverse market with unbounded variances, in which strong arbitrage opportunities with respect to the market portfolio exist over arbitrary time horizons, as was shown by Banner and Fernholz (2008). Moreover, Pal (2012) derived the joint density of market weights at fixed times and at certain stopping times.
Rank-based portfolios
We fix an integer and construct two capitalization-weighted portfolios: one consisting of the top stocks, denoted , and one consisting of the bottom stocks, denoted . More specifically,
for Fernholz (1999), (2002) showed that the relative performance of the large-stock portfolio with respect to the market is given as
Indeed, if there is no turnover at the mth rank during the interval , the fortunes of relative to the market are determined solely on the basis of how the total capitalization of this sub-universe of the largest stocks fares, at time versus time 0; whenever there is turnover at the -th rank, though, has to sell at a loss a stock that gets “relegated” to the lower league, and buy a stock that has risen in value and been promoted. This accounts for the “leakage” that is evident in the last term, an integral with respect to the cumulative turnover process of the relative weight in the large-cap portfolio of the stock that occupies the mth rank.
The reverse situation prevails with the portfolio of small stocks, which gets to sell at a profit stocks that are being promoted to the “upper capitalization” league, and buy relatively cheaply stocks that are being relegated:
It is clear from these two expressions that, in a coherent and stochastically stable market, the small- stock cap-weighted portfolio will tend to outperform its large-stock counterpart , at least over large time horizons and; in particular, we have under those conditions
This quantifies the so-called size effect. In Fernholz (1999, 2002), constructions such as these are generalized to include functionally generated portfolios based on ranked market weights.
First- and second-order models
First- and second-order models are hybrid Atlas models that reproduce some of the structure of real stock markets. First-order models have only rank-based parameters, and second-order models have both rank-based and name-based parameters.
Suppose that is a coherent market, and that the limits
and
exist for , where is the rank of . Then the Atlas model defined by
where is the rank of and is an -dimensional Brownian motion process, is the first-order model for the original market, .
Under reasonable conditions, the capital distribution curve for a first-order model will be close to that of the original market. However, a first-order model is ergodic in the sense that each stock asymptotically spends -th of its time at each rank, a property that is not present in actual markets. In order to vary the proportion of time that a stock spends at each rank, it is necessary to use some form of hybrid Atlas model with parameters that depend on both rank and name. An effort in this direction was made by Fernholz, Ichiba, and Karatzas (2013), who introduced a second-order model for the market with rank- and name-based growth parameters, and variance parameters that depended on rank alone.
References
Fernholz, E.R. (2002). Stochastic Portfolio Theory. New York: Springer-Verlag.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.