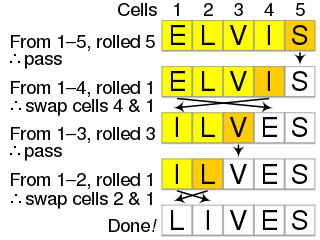
Example
This example is based on the description of the algorithm provided in the book, IT Enabled Practices and Emerging Management Paradigms. [1]
Step 1: Start with a list of numbers: {5, 1, 4, 2, 0, 9, 6, 3, 8, 7 }
Step 2: Next move the first element of the list into a new sub-list: sub-list contains {5}
Step 3: Then iterate through the original list and compare each number to 5 until there is a number greater than 5.
- 1 < 5 so 1 is not added to the sub-list.
- 4 < 5 so 4 is not added to the sub-list.
- 2 < 5 so 2 is not added to the sub-list.
- 0 < 5 so 0 is not added to the sub-list.
- 9 > 5 so 9 is added to the sub-list and removed from the original list.
Step 4: Now compare 9 with the remaining elements in the original list until there is a number greater than 9.
- 6 < 9 so 6 is not added to the sub-list.
- 3 < 9 so 3 is not added to the sub-list.
- 8 < 9 so 8 is not added to the sub-list.
- 7 < 9 so 7 is not added to the sub-list.
Step 5: Now there are no more elements to compare 9 to so merge the sub-list into a new list, called solution-list.
After step 5, the original list contains {1, 4, 2, 0, 6, 3, 8, 7}
The sub-list is empty, and the solution list contains {5, 9}
Step 6: Move the first element of the original list into sub-list: sub-list contains {1}
Step 7: Iterate through the original list and compare each number to 1 until there is a number greater than 1.
- 4 > 1 so 4 is added to the sub-list and 4 is removed from the original list.
Step 8: Now compare 4 with the remaining elements in the original list until there is a number greater than 4.
- 2 < 4 so 2 is not added to the sub-list.
- 0 < 4 so 0 is not added to the sub-list.
- 6 > 4 so 6 is added to the sub-list and is removed from the original list.
Step 9: Now compare 6 with the remaining elements in the original list until there is a number greater than 6.
- 3 < 6 so 3 is not added to the sub-list.
- 8 > 6 so 8 is added to the sub-list and is removed from the original list.
Step 10: Now compare 8 with the remaining elements in the original list until there is a number greater than 8.
- 7 < 8 so 7 is not added to the sub-list.
Step 11: Since there are no more elements in the original list to compare {8} to, the sub-list is merged with the solution list. Now the original list contains {2, 0, 3, 7}, the sub-list is empty and the solution-list contains: {1, 4, 5, 6, 8, 9}.
Step 12: Move the first element of the original list into sub-list. Sub-list contains {2}
Step 13: Iterate through the original list and compare each number to 2 until there is a number greater than 2.
- 0 < 2 so 0 is not added to the sub-list.
- 3 > 2 so 3 is added to the sub-list and is removed from the original list.
Step 14: Now compare 3 with the remaining elements in the original list until there is a number greater than 3.
- 7 > 3 so 7 is added to the sub-list and is removed from the original list.
Step 15: Since there are no more elements in the original list to compare {7} to, the sub-list is merged with the solution list. The original list now contains {0}, the sub-list is empty, and solution list contains: {1, 2, 3, 4, 5, 6, 7, 8, 9}.
Step 16: Move the first element of the original list into sub-list. Sub-list contains {0}.
Step 17: Since the original list is now empty, the sub-list is merged with the solution list. The solution list now contains: {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}. There are now no more elements in the original list, and all of the elements in the solution list have successfully been sorted into increasing numerical order.