Stress majorization is an optimization strategy used in multidimensional scaling (MDS) where, for a set of nm-dimensional data items, a configuration X of n points in r(<<m)-dimensional space is sought that minimizes the so-called stress function . Usually r is 2 or 3, i.e. the (n x r) matrix X lists points in 2- or 3-dimensional Euclidean space so that the result may be visualised (i.e. an MDS plot). The function is a cost or loss function that measures the squared differences between ideal (-dimensional) distances and actual distances in r-dimensional space. It is defined as:




Multidimensional scaling (MDS) is a means of visualizing the level of similarity of individual cases of a dataset. MDS is used to translate "information about the pairwise 'distances' among a set of n objects or individuals" into a configuration of n points mapped into an abstract Cartesian space.
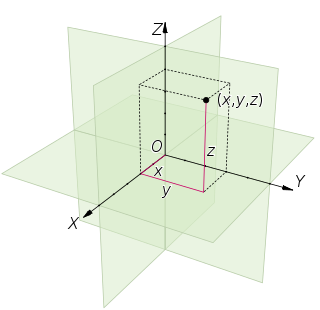
In geometry, Euclidean space encompasses the two-dimensional Euclidean plane, the three-dimensional space of Euclidean geometry, and similar spaces of higher dimension. It is named after the Ancient Greek mathematician Euclid of Alexandria. The term "Euclidean" distinguishes these spaces from other types of spaces considered in modern geometry. Euclidean spaces also generalize to higher dimensions.
In mathematical optimization, statistics, econometrics, decision theory, machine learning and computational neuroscience, a loss function or cost function is a function that maps an event or values of one or more variables onto a real number intuitively representing some "cost" associated with the event. An optimization problem seeks to minimize a loss function. An objective function is either a loss function or its negative, in which case it is to be maximized.
Contents

where is a weight for the measurement between a pair of points , is the euclidean distance between and and is the ideal distance between the points (their separation) in the -dimensional data space. Note that can be used to specify a degree of confidence in the similarity between points (e.g. 0 can be specified if there is no information for a particular pair).








In mathematics, the Euclidean distance or Euclidean metric is the "ordinary" straight-line distance between two points in Euclidean space. With this distance, Euclidean space becomes a metric space. The associated norm is called the Euclidean norm. Older literature refers to the metric as the Pythagorean metric. A generalized term for the Euclidean norm is the L2 norm or L2 distance.
A configuration which minimizes gives a plot in which points that are close together correspond to points that are also close together in the original -dimensional data space.

There are many ways that could be minimized. For example, Kruskal [1] recommended an iterative steepest descent approach. However, a significantly better (in terms of guarantees on, and rate of, convergence) method for minimizing stress was introduced by Jan de Leeuw. [2] De Leeuw's iterative majorization method at each step minimizes a simple convex function which both bounds from above and touches the surface of at a point , called the supporting point. In convex analysis such a function is called a majorizing function. This iterative majorization process is also referred to as the SMACOF algorithm ("Scaling by MAjorizing a COmplicated Function").

Jan de Leeuw is a Dutch statistician and psychometrician. He is Distinguished Professor Emeritus of Statistics and Founding Chair of the Department of Statistics, University of California, Los Angeles. In addition, he is the founding editor and former editor-in-chief of the Journal of Statistical Software, as well as the former editor-in-chief of the Journal of Multivariate Analysis and the "Journal of Educational and Behavioral Statistics".
Convex analysis is the branch of mathematics devoted to the study of properties of convex functions and convex sets, often with applications in convex minimization, a subdomain of optimization theory.