A lexicon is the vocabulary of a language or branch of knowledge. In linguistics, a lexicon is a language's inventory of lexemes. The word lexicon derives from Greek word λεξικόν, neuter of λεξικός meaning 'of or for words'.
The following outline is provided as an overview and topical guide to linguistics:
In linguistics, syntax is the study of how words and morphemes combine to form larger units such as phrases and sentences. Central concerns of syntax include word order, grammatical relations, hierarchical sentence structure (constituency), agreement, the nature of crosslinguistic variation, and the relationship between form and meaning (semantics). There are numerous approaches to syntax that differ in their central assumptions and goals.
In linguistics, transformational grammar (TG) or transformational-generative grammar (TGG) is part of the theory of generative grammar, especially of natural languages. It considers grammar to be a system of rules that generate exactly those combinations of words that form grammatical sentences in a given language and involves the use of defined operations to produce new sentences from existing ones.
Lexical semantics, as a subfield of linguistic semantics, is the study of word meanings. It includes the study of how words structure their meaning, how they act in grammar and compositionality, and the relationships between the distinct senses and uses of a word.
Head-driven phrase structure grammar (HPSG) is a highly lexicalized, constraint-based grammar developed by Carl Pollard and Ivan Sag. It is a type of phrase structure grammar, as opposed to a dependency grammar, and it is the immediate successor to generalized phrase structure grammar. HPSG draws from other fields such as computer science and uses Ferdinand de Saussure's notion of the sign. It uses a uniform formalism and is organized in a modular way which makes it attractive for natural language processing.
Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part.
Tree-adjoining grammar (TAG) is a grammar formalism defined by Aravind Joshi. Tree-adjoining grammars are somewhat similar to context-free grammars, but the elementary unit of rewriting is the tree rather than the symbol. Whereas context-free grammars have rules for rewriting symbols as strings of other symbols, tree-adjoining grammars have rules for rewriting the nodes of trees as other trees.
Construction grammar is a family of theories within the field of cognitive linguistics which posit that constructions, or learned pairings of linguistic patterns with meanings, are the fundamental building blocks of human language. Constructions include words, morphemes, fixed expressions and idioms, and abstract grammatical rules such as the passive voice or the ditransitive. Any linguistic pattern is considered to be a construction as long as some aspect of its form or its meaning cannot be predicted from its component parts, or from other constructions that are recognized to exist. In construction grammar, every utterance is understood to be a combination of multiple different constructions, which together specify its precise meaning and form.
In linguistics, a feature is any characteristic used to classify a phoneme or word. These are often binary or unary conditions which act as constraints in various forms of linguistic analysis.
In linguistics, linguistic competence is the system of unconscious knowledge that one knows when they know a language. It is distinguished from linguistic performance, which includes all other factors that allow one to use one's language in practice.

In linguistics, a treebank is a parsed text corpus that annotates syntactic or semantic sentence structure. The construction of parsed corpora in the early 1990s revolutionized computational linguistics, which benefitted from large-scale empirical data.
Generative lexicon (GL) is a theory of linguistic semantics which focuses on the distributed nature of compositionality in natural language. The first major work outlining the framework is James Pustejovsky's 1991 article "The Generative Lexicon". Subsequent important developments are presented in Pustejovsky and Boguraev (1993), Bouillon (1997), and Busa (1996). The first unified treatment of GL was given in Pustejovsky (1995). Unlike purely verb-based approaches to compositionality, generative lexicon attempts to spread the semantic load across all constituents of the utterance. Central to the philosophical perspective of GL are two major lines of inquiry: (1) How is it that we are able to deploy a finite number of words in our language in an unbounded number of contexts? (2) Is lexical information and the representations used in composing meanings separable from our commonsense knowledge?
Linguistic categories include

Joan Lea Bybee is an American linguist and professor emerita at the University of New Mexico. Much of her work concerns grammaticalization, stochastics, modality, morphology, and phonology. Bybee is best known for proposing the theory of usage-based phonology and for her contributions to cognitive and historical linguistics.
In linguistics, well-formedness is the quality of a clause, word, or other linguistic element that conforms to the grammar of the language of which it is a part. Well-formed words or phrases are grammatical, meaning they obey all relevant rules of grammar. In contrast, a form that violates some grammar rule is ill-formed and does not constitute part of the language.

Aspects of the Theory of Syntax is a book on linguistics written by American linguist Noam Chomsky, first published in 1965. In Aspects, Chomsky presented a deeper, more extensive reformulation of transformational generative grammar (TGG), a new kind of syntactic theory that he had introduced in the 1950s with the publication of his first book, Syntactic Structures. Aspects is widely considered to be the foundational document and a proper book-length articulation of Chomskyan theoretical framework of linguistics. It presented Chomsky's epistemological assumptions with a view to establishing linguistic theory-making as a formal discipline comparable to physical sciences, i.e. a domain of inquiry well-defined in its nature and scope. From a philosophical perspective, it directed mainstream linguistic research away from behaviorism, constructivism, empiricism and structuralism and towards mentalism, nativism, rationalism and generativism, respectively, taking as its main object of study the abstract, inner workings of the human mind related to language acquisition and production.
The Integrational theory of language is the general theory of language that has been developed within the general linguistic approach of integrational linguistics.
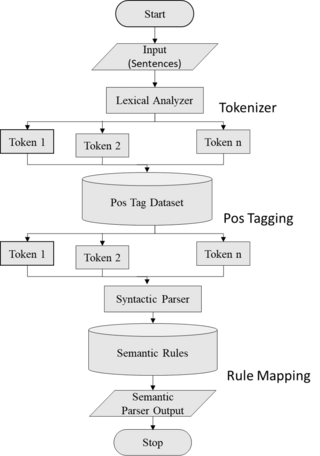
Semantic parsing is the task of converting a natural language utterance to a logical form: a machine-understandable representation of its meaning. Semantic parsing can thus be understood as extracting the precise meaning of an utterance. Applications of semantic parsing include machine translation, question answering, ontology induction, automated reasoning, and code generation. The phrase was first used in the 1970s by Yorick Wilks as the basis for machine translation programs working with only semantic representations. Semantic parsing is one of the important tasks in computational linguistics and natural language processing.
Syntactic parsing is the automatic analysis of syntactic structure of natural language, especially syntactic relations and labelling spans of constituents. It is motivated by the problem of structural ambiguity in natural language: a sentence can be assigned multiple grammatical parses, so some kind of knowledge beyond computational grammar rules is needed to tell which parse is intended. Syntactic parsing is one of the important tasks in computational linguistics and natural language processing, and has been a subject of research since the mid-20th century with the advent of computers.