Related Research Articles
Computational linguistics is an interdisciplinary field concerned with the computational modelling of natural language, as well as the study of appropriate computational approaches to linguistic questions. In general, computational linguistics draws upon linguistics, computer science, artificial intelligence, mathematics, logic, philosophy, cognitive science, cognitive psychology, psycholinguistics, anthropology and neuroscience, among others.
The following outline is provided as an overview and topical guide to linguistics:
Natural language processing (NLP) is an interdisciplinary subfield of computer science and artificial intelligence. It is primarily concerned with providing computers the ability to process data encoded in natural language and is thus closely related to information retrieval, knowledge representation and computational linguistics, a subfield of linguistics. Typically data is collected in text corpora, using either rule-based, statistical or neural-based approaches of machine learning and deep learning.
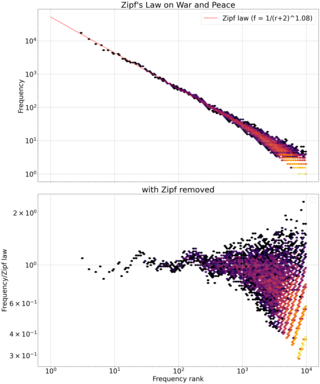
Zipf's law is an empirical law that often holds, approximately, when a list of measured values is sorted in decreasing order. It states that the value of the nth entry is inversely proportional to n.
Linguistic typology is a field of linguistics that studies and classifies languages according to their structural features to allow their comparison. Its aim is to describe and explain the structural diversity and the common properties of the world's languages. Its subdisciplines include, but are not limited to phonological typology, which deals with sound features; syntactic typology, which deals with word order and form; lexical typology, which deals with language vocabulary; and theoretical typology, which aims to explain the universal tendencies.
Historical linguistics, also termed diachronic linguistics, is the scientific study of language change over time. Principal concerns of historical linguistics include:
- to describe and account for observed changes in particular languages
- to reconstruct the pre-history of languages and to determine their relatedness, grouping them into language families
- to develop general theories about how and why language changes
- to describe the history of speech communities
- to study the history of words, i.e. etymology
- to explore the impact of cultural and social factors on language evolution.
Word-sense disambiguation is the process of identifying which sense of a word is meant in a sentence or other segment of context. In human language processing and cognition, it is usually subconscious/automatic, but can often come to conscious attention when ambiguity impairs clarity of communication, given the pervasive polysemy in natural language. In computational linguistics.
Cognitive linguistics is an interdisciplinary branch of linguistics, combining knowledge and research from cognitive science, cognitive psychology, neuropsychology and linguistics. Models and theoretical accounts of cognitive linguistics are considered as psychologically real, and research in cognitive linguistics aims to help understand cognition in general and is seen as a road into the human mind.

In linguistics, Heaps' law is an empirical law which describes the number of distinct words in a document as a function of the document length. It can be formulated as
Language change is the process of alteration in the features of a single language, or of languages in general, across a period of time. It is studied in several subfields of linguistics: historical linguistics, sociolinguistics, and evolutionary linguistics. Traditional theories of historical linguistics identify three main types of change: systematic change in the pronunciation of phonemes, or sound change; borrowing, in which features of a language or dialect are introduced or altered as a result of influence from another language or dialect; and analogical change, in which the shape or grammatical behavior of a word is altered to more closely resemble that of another word.
In linguistics, statistical semantics applies the methods of statistics to the problem of determining the meaning of words or phrases, ideally through unsupervised learning, to a degree of precision at least sufficient for the purpose of information retrieval.

Distributional semantics is a research area that develops and studies theories and methods for quantifying and categorizing semantic similarities between linguistic items based on their distributional properties in large samples of language data. The basic idea of distributional semantics can be summed up in the so-called distributional hypothesis: linguistic items with similar distributions have similar meanings.
Stefan Th. Gries is (full) professor of linguistics in the Department of Linguistics at the University of California, Santa Barbara (UCSB), Honorary Liebig-Professor of the Justus-Liebig-Universität Giessen, and since 1 April 2018 also Chair of English Linguistics in the Department of English at the Justus-Liebig-Universität Giessen.
Linguistics is the scientific study of language. Linguistics is based on a theoretical as well as a descriptive study of language and is also interlinked with the applied fields of language studies and language learning, which entails the study of specific languages. Before the 20th century, linguistics evolved in conjunction with literary study and did not employ scientific methods. Modern-day linguistics is considered a science because it entails a comprehensive, systematic, objective, and precise analysis of all aspects of language – i.e., the cognitive, the social, the cultural, the psychological, the environmental, the biological, the literary, the grammatical, the paleographical, and the structural.
Quantitative linguistics (QL) is a sub-discipline of general linguistics and, more specifically, of mathematical linguistics. Quantitative linguistics deals with language learning, language change, and application as well as structure of natural languages. QL investigates languages using statistical methods; its most demanding objective is the formulation of language laws and, ultimately, of a general theory of language in the sense of a set of interrelated languages laws. Synergetic linguistics was from its very beginning specifically designed for this purpose. QL is empirically based on the results of language statistics, a field which can be interpreted as statistics of languages or as statistics of any linguistic object. This field is not necessarily connected to substantial theoretical ambitions. Corpus linguistics and computational linguistics are other fields which contribute important empirical evidence.
A word list is a list of a language's lexicon within some given text corpus, serving the purpose of vocabulary acquisition. A lexicon sorted by frequency "provides a rational basis for making sure that learners get the best return for their vocabulary learning effort", but is mainly intended for course writers, not directly for learners. Frequency lists are also made for lexicographical purposes, serving as a sort of checklist to ensure that common words are not left out. Some major pitfalls are the corpus content, the corpus register, and the definition of "word". While word counting is a thousand years old, with still gigantic analysis done by hand in the mid-20th century, natural language electronic processing of large corpora such as movie subtitles has accelerated the research field.
Paul Nation is an internationally recognized scholar in the field of linguistics and teaching methodology. As a professor in the field of applied linguistics with a specialization in pedagogical methodology, he has been able to create a language teaching framework to identify key areas of language teaching focus. Paul Nation is best known for this framework, which has been labelled The Four Strands. He has also made notable contributions through his research in the field of language acquisition that focuses on the benefits of extensive reading and repetition as well as intensive reading. Nation's numerous contributions to the linguistics research community through his published work has allowed him to share his knowledge and experience so that others may adopt and adapt it. He is credited with bringing « legitimization to second language vocabulary researches » in 1990.
Norbert Schmitt is an American applied linguist and Emeritus Professor of Applied Linguistics at the University of Nottingham in the United Kingdom. He is known for his work on second-language vocabulary acquisition and second-language vocabulary teaching. He has published numerous books and papers on vocabulary acquisition.
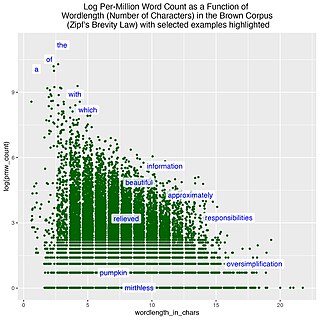
In linguistics, the brevity law is a linguistic law that qualitatively states that the more frequently a word is used, the shorter that word tends to be, and vice versa; the less frequently a word is used, the longer it tends to be. This is a statistical regularity that can be found in natural languages and other natural systems and that claims to be a general rule.
The usage-based linguistics is a linguistics approach within a broader functional/cognitive framework, that emerged since the late 1980s, and that assumes a profound relation between linguistic structure and usage. It challenges the dominant focus, in 20th century linguistics, on considering language as an isolated system removed from its use in human interaction and human cognition. Rather, usage-based models posit that linguistic information is expressed via context-sensitive mental processing and mental representations, which have the cognitive ability to succinctly account for the complexity of actual language use at all levels. Broadly speaking, a usage-based model of language accounts for language acquisition and processing, synchronic and diachronic patterns, and both low-level and high-level structure in language, by looking at actual language use.
References
- ↑ "Word length and frequency - Laws in Quantitative Linguistics". 2015-02-15. Archived from the original on 2015-02-15. Retrieved 2024-06-18.
- ↑ "Polysemy and length - Laws in Quantitative Linguistics". 2016-01-30. Archived from the original on 2016-01-30. Retrieved 2024-06-18.
- ↑ "Distribution of Polysemous Words". Archived from the original on 2015-12-24. Retrieved 2024-06-18.
- ↑ "Frequency and polytextuality". Archived from the original on 2015-04-02. Retrieved 2024-06-18.