Related Research Articles
Knowledge representation and reasoning is the field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can use to solve complex tasks such as diagnosing a medical condition or having a dialog in a natural language. Knowledge representation incorporates findings from psychology about how humans solve problems, and represent knowledge in order to design formalisms that will make complex systems easier to design and build. Knowledge representation and reasoning also incorporates findings from logic to automate various kinds of reasoning.

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
In information science, an ontology encompasses a representation, formal naming, and definitions of the categories, properties, and relations between the concepts, data, or entities that pertain to one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of terms and relational expressions that represent the entities in that subject area. The field which studies ontologies so conceived is sometimes referred to as applied ontology.
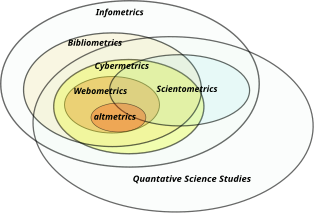
Information science is an academic field which is primarily concerned with analysis, collection, classification, manipulation, storage, retrieval, movement, dissemination, and protection of information. Practitioners within and outside the field study the application and the usage of knowledge in organizations in addition to the interaction between people, organizations, and any existing information systems with the aim of creating, replacing, improving, or understanding the information systems.
A modeling language is any artificial language that can be used to express data, information or knowledge or systems in a structure that is defined by a consistent set of rules. The rules are used for interpretation of the meaning of components in the structure of a programing language.
Question answering (QA) is a computer science discipline within the fields of information retrieval and natural language processing (NLP) that is concerned with building systems that automatically answer questions that are posed by humans in a natural language.
GNOWSYS is a specification for a generic distributed network based memory/knowledge management. It is developed as an application for developing and maintaining semantic web content. It is written in Python. It is implemented as a Django app. The GNOWSYS project was launched by Nagarjuna G. in 2001, while he was working at Homi Bhabha Centre for Science Education (HBCSE).
Gellish is an ontology language for data storage and communication, designed and developed by Andries van Renssen since mid-1990s. It started out as an engineering modeling language but evolved into a universal and extendable conceptual data modeling language with general applications. Because it includes domain-specific terminology and definitions, it is also a semantic data modelling language and the Gellish modeling methodology is a member of the family of semantic modeling methodologies.
Terminology extraction is a subtask of information extraction. The goal of terminology extraction is to automatically extract relevant terms from a given corpus.
The concept of the Social Semantic Web subsumes developments in which social interactions on the Web lead to the creation of explicit and semantically rich knowledge representations. The Social Semantic Web can be seen as a Web of collective knowledge systems, which are able to provide useful information based on human contributions and which get better as more people participate. The Social Semantic Web combines technologies, strategies and methodologies from the Semantic Web, social software and the Web 2.0.
Ontology learning is the automatic or semi-automatic creation of ontologies, including extracting the corresponding domain's terms and the relationships between the concepts that these terms represent from a corpus of natural language text, and encoding them with an ontology language for easy retrieval. As building ontologies manually is extremely labor-intensive and time-consuming, there is great motivation to automate the process.
Data preprocessing can refer to manipulation, filtration or augmentation of data before it is analyzed, and is often an important step in the data mining process. Data collection methods are often loosely controlled, resulting in out-of-range values, impossible data combinations, and missing values, amongst other issues.
Contemporary ontologies share many structural similarities, regardless of the ontology language in which they are expressed. Most ontologies describe individuals (instances), classes (concepts), attributes, and relations.
There is a large body of knowledge that designers call upon and use during the design process to match the ever-increasing complexity of design problems. Design knowledge can be classified into two categories: product knowledge and design process knowledge.
Knowledge-based configuration, also referred to as product configuration or product customization, is an activity of customising a product to meet the needs of a particular customer. The product in question may consist of mechanical parts, services, and software. Knowledge-based configuration is a major application area for artificial intelligence (AI), and it is based on modelling of the configurations in a manner that allows the utilisation of AI techniques for searching for a valid configuration to meet the needs of a particular customer.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
In information technology a reasoning system is a software system that generates conclusions from available knowledge using logical techniques such as deduction and induction. Reasoning systems play an important role in the implementation of artificial intelligence and knowledge-based systems.
The following outline is provided as an overview of and topical guide to natural-language processing:
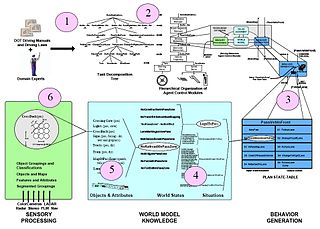
Knowledge acquisition is the process used to define the rules and ontologies required for a knowledge-based system. The phrase was first used in conjunction with expert systems to describe the initial tasks associated with developing an expert system, namely finding and interviewing domain experts and capturing their knowledge via rules, objects, and frame-based ontologies.

UMBEL is a logically organized knowledge graph of 34,000 concepts and entity types that can be used in information science for relating information from disparate sources to one another. It was retired at the end of 2019. UMBEL was first released in July 2008. Version 1.00 was released in February 2011. Its current release is version 1.50.
References
- ↑ Mahmoud R. Hejazi, Maryam S. Mirian, Kourosh Neshatian, Azam Jalali, and Bahadorreza Ofoghi, A Telecommunication Literature Question/Answering System Benefits from a Text Categorization Mechanism, International Conference on Information and Knowledge Engineering (IKE2003), July 2003, USA.
- ↑ Kourosh Neshatian and Mahmoud R. Hejazi, An Object Oriented Ontology Interface for Information Retrieval Purposes in Telecommunication Domain, International Symposium on Telecommunication (IST2003).