In computing, a database is an organized collection of data or a type of data store based on the use of a database management system (DBMS), the software that interacts with end users, applications, and the database itself to capture and analyze the data. The DBMS additionally encompasses the core facilities provided to administer the database. The sum total of the database, the DBMS and the associated applications can be referred to as a database system. Often the term "database" is also used loosely to refer to any of the DBMS, the database system or an application associated with the database.
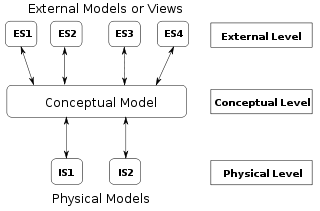
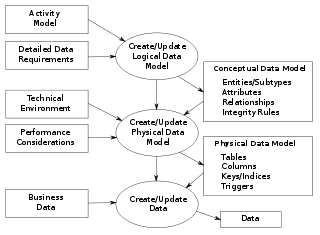
A conceptual schema or conceptual data model is a high-level description of informational needs underlying the design of a database. It typically includes only the main concepts and the main relationships among them. Typically this is a first-cut model, with insufficient detail to build an actual database. This level describes the structure of the whole database for a group of users. The conceptual model is also known as the data model that can be used to describe the conceptual schema when a database system is implemented. It hides the internal details of physical storage and targets the description of entities, datatypes, relationships and constraints.

An object–relational database (ORD), or object–relational database management system (ORDBMS), is a database management system (DBMS) similar to a relational database, but with an object-oriented database model: objects, classes and inheritance are directly supported in database schemas and in the query language. In addition, just as with pure relational systems, it supports extension of the data model with custom data types and methods.
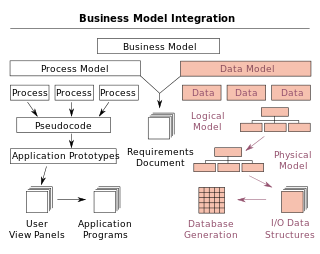
A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities. For instance, a data model may specify that the data element representing a car be composed of a number of other elements which, in turn, represent the color and size of the car and define its owner.
Data modeling in software engineering is the process of creating a data model for an information system by applying certain formal techniques. It may be applied as part of broader Model-driven engineering (MDE) concept.

The Zachman Framework is an enterprise ontology and is a fundamental structure for enterprise architecture which provides a formal and structured way of viewing and defining an enterprise. The ontology is a two dimensional classification schema that reflects the intersection between two historical classifications. The first are primitive interrogatives: What, How, When, Who, Where, and Why. The second is derived from the philosophical concept of reification, the transformation of an abstract idea into an instantiation. The Zachman Framework reification transformations are: identification, definition, representation, specification, configuration and instantiation.
A logical data model or logical schema is a data model of a specific problem domain expressed independently of a particular database management product or storage technology but in terms of data structures such as relational tables and columns, object-oriented classes, or XML tags. This is as opposed to a conceptual data model, which describes the semantics of an organization without reference to technology.
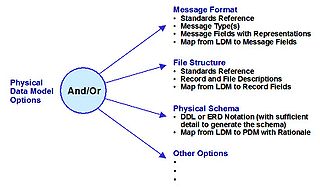
A physical data model is a representation of a data design as implemented, or intended to be implemented, in a database management system. In the lifecycle of a project it typically derives from a logical data model, though it may be reverse-engineered from a given database implementation. A complete physical data model will include all the database artifacts required to create relationships between tables or to achieve performance goals, such as indexes, constraint definitions, linking tables, partitioned tables or clusters. Analysts can usually use a physical data model to calculate storage estimates; it may include specific storage allocation details for a given database system.
A federated database system (FDBS) is a type of meta-database management system (DBMS), which transparently maps multiple autonomous database systems into a single federated database. The constituent databases are interconnected via a computer network and may be geographically decentralized. Since the constituent database systems remain autonomous, a federated database system is a contrastable alternative to the task of merging several disparate databases. A federated database, or virtual database, is a composite of all constituent databases in a federated database system. There is no actual data integration in the constituent disparate databases as a result of data federation.
Data independence is the type of data transparency that matters for a centralized DBMS. It refers to the immunity of user applications to changes made in the definition and organization of data. Application programs should not, ideally, be exposed to details of data representation and storage. The DBMS provides an abstract view of the data that hides such details.

Uniface is a low-code development and deployment platform for enterprise applications that can run in a large range of runtime environments, including mobile, mainframe, web, Service-oriented architecture (SOA), Windows, Java EE, and .NET. Uniface is used to create mission-critical applications.

Integration DEFinition for information modeling (IDEF1X) is a data modeling language for the development of semantic data models. IDEF1X is used to produce a graphical information model which represents the structure and semantics of information within an environment or system.
Data integration involves combining data residing in different sources and providing users with a unified view of them. This process becomes significant in a variety of situations, which include both commercial and scientific domains. Data integration appears with increasing frequency as the volume, complexity and the need to share existing data explodes. It has become the focus of extensive theoretical work, and numerous open problems remain unsolved. Data integration encourages collaboration between internal as well as external users. The data being integrated must be received from a heterogeneous database system and transformed to a single coherent data store that provides synchronous data across a network of files for clients. A common use of data integration is in data mining when analyzing and extracting information from existing databases that can be useful for Business information.

Enterprise modelling is the abstract representation, description and definition of the structure, processes, information and resources of an identifiable business, government body, or other large organization.

The ANSI-SPARC Architecture, is an abstract design standard for a database management system (DBMS), first proposed in 1975.

A semantic data model (SDM) is a high-level semantics-based database description and structuring formalism for databases. This database model is designed to capture more of the meaning of an application environment than is possible with contemporary database models. An SDM specification describes a database in terms of the kinds of entities that exist in the application environment, the classifications and groupings of those entities, and the structural interconnections among them. SDM provides a collection of high-level modeling primitives to capture the semantics of an application environment. By accommodating derived information in a database structural specification, SDM allows the same information to be viewed in several ways; this makes it possible to directly accommodate the variety of needs and processing requirements typically present in database applications. The design of the present SDM is based on our experience in using a preliminary version of it. SDM is designed to enhance the effectiveness and usability of database systems. An SDM database description can serve as a formal specification and documentation tool for a database; it can provide a basis for supporting a variety of powerful user interface facilities, it can serve as a conceptual database model in the database design process; and, it can be used as the database model for a new kind of database management system.

A view model or viewpoints framework in systems engineering, software engineering, and enterprise engineering is a framework which defines a coherent set of views to be used in the construction of a system architecture, software architecture, or enterprise architecture. A view is a representation of the whole system from the perspective of a related set of concerns.

NIST Enterprise Architecture Model is a late-1980s reference model for enterprise architecture. It defines an enterprise architecture by the interrelationship between an enterprise's business, information, and technology environments.
The following is provided as an overview of and topical guide to databases:

Sparx Systems Enterprise Architect is a visual modeling and design tool based on the OMG UML. The platform supports: the design and construction of software systems; modeling business processes; and modeling industry based domains. It is used by businesses and organizations to not only model the architecture of their systems, but to process the implementation of these models across the full application development life-cycle.