
The Chomsky hierarchy in the fields of formal language theory, computer science, and linguistics, is a containment hierarchy of classes of formal grammars. A formal grammar describes how to form strings from a language's vocabulary that are valid according to the language's syntax. The linguist Noam Chomsky theorized that four different classes of formal grammars existed that could generate increasingly complex languages. Each class can also completely generate the language of all inferior classes.

In formal language theory, a context-free grammar (CFG) is a formal grammar whose production rules can be applied to a nonterminal symbol regardless of its context. In particular, in a context-free grammar, each production rule is of the form
In computer science, the Earley parser is an algorithm for parsing strings that belong to a given context-free language, though it may suffer problems with certain nullable grammars. The algorithm, named after its inventor, Jay Earley, is a chart parser that uses dynamic programming; it is mainly used for parsing in computational linguistics. It was first introduced in his dissertation in 1968.
In computer science, LR parsers are a type of bottom-up parser that analyse deterministic context-free languages in linear time. There are several variants of LR parsers: SLR parsers, LALR parsers, canonical LR(1) parsers, minimal LR(1) parsers, and generalized LR parsers. LR parsers can be generated by a parser generator from a formal grammar defining the syntax of the language to be parsed. They are widely used for the processing of computer languages.
In computer science, the Cocke–Younger–Kasami algorithm is a parsing algorithm for context-free grammars published by Itiroo Sakai in 1961. The algorithm is named after some of its rediscoverers: John Cocke, Daniel Younger, Tadao Kasami, and Jacob T. Schwartz. It employs bottom-up parsing and dynamic programming.
In computer science, an LL parser is a top-down parser for a restricted context-free language. It parses the input from Left to right, performing Leftmost derivation of the sentence.
In computer science, a recursive descent parser is a kind of top-down parser built from a set of mutually recursive procedures where each such procedure implements one of the nonterminals of the grammar. Thus the structure of the resulting program closely mirrors that of the grammar it recognizes.
Grammar theory to model symbol strings originated from work in computational linguistics aiming to understand the structure of natural languages. Probabilistic context free grammars (PCFGs) have been applied in probabilistic modeling of RNA structures almost 40 years after they were introduced in computational linguistics.
Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part.
In computing, memoization or memoisation is an optimization technique used primarily to speed up computer programs by storing the results of expensive function calls to pure functions and returning the cached result when the same inputs occur again. Memoization has also been used in other contexts, such as in simple mutually recursive descent parsing. It is a type of caching, distinct from other forms of caching such as buffering and page replacement. In the context of some logic programming languages, memoization is also known as tabling.
In computer science, a parsing expression grammar (PEG) is a type of analytic formal grammar, i.e. it describes a formal language in terms of a set of rules for recognizing strings in the language. The formalism was introduced by Bryan Ford in 2004 and is closely related to the family of top-down parsing languages introduced in the early 1970s. Syntactically, PEGs also look similar to context-free grammars (CFGs), but they have a different interpretation: the choice operator selects the first match in PEG, while it is ambiguous in CFG. This is closer to how string recognition tends to be done in practice, e.g. by a recursive descent parser.
The Packrat parser is a type of parser that shares similarities with the recursive descent parser in its construction. However, it differs because it takes parsing expression grammars (PEGs) as input rather than LL grammars.
In the formal language theory of computer science, left recursion is a special case of recursion where a string is recognized as part of a language by the fact that it decomposes into a string from that same language and a suffix. For instance, can be recognized as a sum because it can be broken into , also a sum, and , a suitable suffix.
ID/LP Grammars are a subset of Phrase Structure Grammars, differentiated from other formal grammars by distinguishing between immediate dominance (ID) and linear precedence (LP) constraints. Whereas traditional phrase structure rules incorporate dominance and precedence into a single rule, ID/LP Grammars maintains separate rule sets which need not be processed simultaneously. ID/LP Grammars are used in Computational Linguistics.

In computer science, recursion is a method of solving a computational problem where the solution depends on solutions to smaller instances of the same problem. Recursion solves such recursive problems by using functions that call themselves from within their own code. The approach can be applied to many types of problems, and recursion is one of the central ideas of computer science.
The power of recursion evidently lies in the possibility of defining an infinite set of objects by a finite statement. In the same manner, an infinite number of computations can be described by a finite recursive program, even if this program contains no explicit repetitions.
In computer science, a grammar is informally called a recursive grammar if it contains production rules that are recursive, meaning that expanding a non-terminal according to these rules can eventually lead to a string that includes the same non-terminal again. Otherwise it is called a non-recursive grammar.
In computer programming, a parser combinator is a higher-order function that accepts several parsers as input and returns a new parser as its output. In this context, a parser is a function accepting strings as input and returning some structure as output, typically a parse tree or a set of indices representing locations in the string where parsing stopped successfully. Parser combinators enable a recursive descent parsing strategy that facilitates modular piecewise construction and testing. This parsing technique is called combinatory parsing.

A formal grammar describes which strings from an alphabet of a formal language are valid according to the language's syntax. A grammar does not describe the meaning of the strings or what can be done with them in whatever context—only their form. A formal grammar is defined as a set of production rules for such strings in a formal language.
A filtered-popping recursive transition network (FPRTN), or simply filtered-popping network (FPN), is a recursive transition network (RTN) extended with a map of states to keys where returning from a subroutine jump requires the acceptor and return states to be mapped to the same key. RTNs are finite-state machines that can be seen as finite-state automata extended with a stack of return states; as well as consuming transitions and -transitions, RTNs may define call transitions. These transitions perform a subroutine jump by pushing the transition's target state onto the stack and bringing the machine to the called state. Each time an acceptor state is reached, the return state at the top of the stack is popped out, provided that the stack is not empty, and the machine is brought to this state.
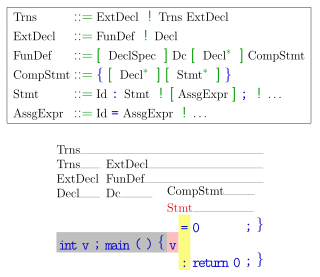
In formal language theory, an LL grammar is a context-free grammar that can be parsed by an LL parser, which parses the input from Left to right, and constructs a Leftmost derivation of the sentence. A language that has an LL grammar is known as an LL language. These form subsets of deterministic context-free grammars (DCFGs) and deterministic context-free languages (DCFLs), respectively. One says that a given grammar or language "is an LL grammar/language" or simply "is LL" to indicate that it is in this class.


