In formal language theory, a context-free grammar (CFG) is a certain type of formal grammar: a set of production rules that describe all possible strings in a given formal language. Production rules are simple replacements. For example, the rule
In tensor analysis, a mixed tensor is a tensor which is neither strictly covariant nor strictly contravariant; at least one of the indices of a mixed tensor will be a subscript (covariant) and at least one of the indices will be a superscript (contravariant).

In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] parametrized by two positive shape parameters, denoted by α and β, that appear as exponents of the random variable and control the shape of the distribution. The generalization to multiple variables is called a Dirichlet distribution.

In probability theory and statistics, the gamma distribution is a two-parameter family of continuous probability distributions. The exponential distribution, Erlang distribution, and chi-squared distribution are special cases of the gamma distribution. There are three different parametrizations in common use:
- With a shape parameter k and a scale parameter θ.
- With a shape parameter α = k and an inverse scale parameter β = 1/θ, called a rate parameter.
- With a shape parameter k and a mean parameter μ = kθ = α/β.
In linear algebra, a Vandermonde matrix, named after Alexandre-Théophile Vandermonde, is a matrix with the terms of a geometric progression in each row, i.e., an m × n matrix
In mathematics, the Smith normal form is a normal form that can be defined for any matrix with entries in a principal ideal domain (PID). The Smith normal form of a matrix is diagonal, and can be obtained from the original matrix by multiplying on the left and right by invertible square matrices. In particular, the integers are a PID, so one can always calculate the Smith normal form of an integer matrix. The Smith normal form is very useful for working with finitely generated modules over a PID, and in particular for deducing the structure of a quotient of a free module. It is named after the British mathematician Henry John Stephen Smith.

In linear algebra, a basis for a vector space is a linearly independent set spanning the vector space. This article deals mainly with finite-dimensional vector spaces, but many of the theorems are also valid for infinite-dimensional vector spaces. A basis for a vector space of dimension n is a set of n vectors (α1, …, αn), called basis vectors, with the property that every vector in the space can be expressed as a unique linear combination of the basis vectors. The matrix representations of operators are also determined by the chosen basis. Since it is often desirable to work with more than one basis for a vector space, it is of fundamental importance in linear algebra to be able to easily transform coordinate-wise representations of vectors and operators taken with respect to one basis to their equivalent representations with respect to another basis. Such a transformation is called a change of basis.
In the formal language theory of computer science, left recursion is a special case of recursion where a string is recognized as part of a language by the fact that it decomposes into a string from that same language and a suffix. For instance, can be recognized as a sum because it can be broken into , also a sum, and , a suitable suffix.

In probability theory and statistics, the inverse gamma distribution is a two-parameter family of continuous probability distributions on the positive real line, which is the distribution of the reciprocal of a variable distributed according to the gamma distribution. Perhaps the chief use of the inverse gamma distribution is in Bayesian statistics, where the distribution arises as the marginal posterior distribution for the unknown variance of a normal distribution, if an uninformative prior is used, and as an analytically tractable conjugate prior, if an informative prior is required.(Hoff, 2009:74)

In probability theory and statistics, the generalized inverse Gaussian distribution (GIG) is a three-parameter family of continuous probability distributions with probability density function
ID/LP Grammars are a subset of Phrase Structure Grammars, differentiated from other formal grammars by distinguishing between immediate dominance (ID) and linear precedence (LP) constraints. Whereas traditional phrase structure rules incorporate dominance and precedence into a single rule, ID/LP Grammars maintains separate rule sets which need not be processed simultaneously. ID/LP Grammars are used in Computational Linguistics.
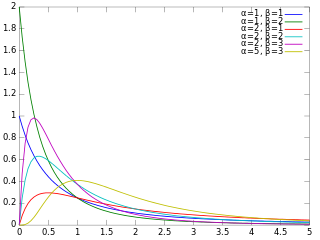
In probability theory and statistics, the beta prime distribution is an absolutely continuous probability distribution defined for with two parameters α and β, having the probability density function:

In probability theory and statistics, the U-quadratic distribution is a continuous probability distribution defined by a unique convex quadratic function with lower limit a and upper limit b.

In probability and statistics, the log-logistic distribution is a continuous probability distribution for a non-negative random variable. It is used in survival analysis as a parametric model for events whose rate increases initially and decreases later, as, for example, mortality rate from cancer following diagnosis or treatment. It has also been used in hydrology to model stream flow and precipitation, in economics as a simple model of the distribution of wealth or income, and in networking to model the transmission times of data considering both the network and the software.

In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.
In electrical engineering, the alpha-betatransformation is a mathematical transformation employed to simplify the analysis of three-phase circuits. Conceptually it is similar to the dq0 transformation. One very useful application of the transformation is the generation of the reference signal used for space vector modulation control of three-phase inverters.
In continuum mechanics, a compatible deformation tensor field in a body is that unique tensor field that is obtained when the body is subjected to a continuous, single-valued, displacement field. Compatibility is the study of the conditions under which such a displacement field can be guaranteed. Compatibility conditions are particular cases of integrability conditions and were first derived for linear elasticity by Barré de Saint-Venant in 1864 and proved rigorously by Beltrami in 1886.
Head grammar (HG) is a grammar formalism introduced in Carl Pollard (1984) as an extension of the context-free grammar class of grammars. Head grammar is therefore a type of phrase structure grammar, as opposed to a dependency grammar. The class of head grammars is a subset of the linear context-free rewriting systems.
In probability theory, a beta negative binomial distribution is the probability distribution of a discrete random variable X equal to the number of failures needed to get r successes in a sequence of independent Bernoulli trials where the probability p of success on each trial is constant within any given experiment but is itself a random variable following a beta distribution, varying between different experiments. Thus the distribution is a compound probability distribution.
In statistics, the matrix t-distribution is the generalization of the multivariate t-distribution from vectors to matrices. The matrix t-distribution shares the same relationship with the multivariate t-distribution that the matrix normal distribution shares with the multivariate normal distribution. For example, the matrix t-distribution is the compound distribution that results from sampling from a matrix normal distribution having sampled the covariance matrix of the matrix normal from an inverse Wishart distribution.



