Computer vision is an interdisciplinary scientific field that deals with how computers can gain high-level understanding from digital images or videos. From the perspective of engineering, it seeks to understand and automate tasks that the human visual system can do.

Attention is the behavioral and cognitive process of selectively concentrating on a discrete aspect of information, whether considered subjective or objective, while ignoring other perceivable information. William James (1890) wrote that "Attention is the taking possession by the mind, in clear and vivid form, of one out of what seem several simultaneously possible objects or trains of thought. Focalization, concentration, of consciousness are of its essence." Attention has also been described as the allocation of limited cognitive processing resources. Attention is manifested by an attentional bottleneck, in term of the amount of data the brain can process each second; for example, in human vision, only less than 1% of the visual input data can enter the bottleneck, leading to inattentional blindness.

In digital image processing and computer vision, image segmentation is the process of partitioning a digital image into multiple segments. The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze. Image segmentation is typically used to locate objects and boundaries in images. More precisely, image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics.
The receptive field, or sensory space, is a delimited medium where some physiological stimuli can evoke a sensory neuronal response in specific organisms.

Sensor fusion is the process of combining sensory data or data derived from disparate sources such that the resulting information has less uncertainty than would be possible when these sources were used individually. For instance, one could potentially obtain a more accurate location estimate of an indoor object by combining multiple data sources such as video cameras and WiFi localization signals. The term uncertainty reduction in this case can mean more accurate, more complete, or more dependable, or refer to the result of an emerging view, such as stereoscopic vision.
The two-streams hypothesis is a model of the neural processing of vision as well as hearing. The hypothesis, given its initial characterisation in a paper by David Milner and Melvyn A. Goodale in 1992, argues that humans possess two distinct visual systems. Recently there seems to be evidence of two distinct auditory systems as well. As visual information exits the occipital lobe, and as sound leaves the phonological network, it follows two main pathways, or "streams". The ventral stream leads to the temporal lobe, which is involved with object and visual identification and recognition. The dorsal stream leads to the parietal lobe, which is involved with processing the object's spatial location relative to the viewer and with speech repetition.
The salience of an item is the state or quality by which it stands out from its neighbors. Saliency detection is considered to be a key attentional mechanism that facilitates learning and survival by enabling organisms to focus their limited perceptual and cognitive resources on the most pertinent subset of the available sensory data.

Long short-term memory (LSTM) is an artificial recurrent neural network (RNN) architecture used in the field of deep learning. Unlike standard feedforward neural networks, LSTM has feedback connections. It can process not only single data points, but also entire sequences of data. For example, LSTM is applicable to tasks such as unsegmented, connected handwriting recognition, speech recognition and anomaly detection in network traffic or IDSs.
Activity recognition aims to recognize the actions and goals of one or more agents from a series of observations on the agents' actions and the environmental conditions. Since the 1980s, this research field has captured the attention of several computer science communities due to its strength in providing personalized support for many different applications and its connection to many different fields of study such as medicine, human-computer interaction, or sociology.

Object detection is a computer technology related to computer vision and image processing that deals with detecting instances of semantic objects of a certain class in digital images and videos. Well-researched domains of object detection include face detection and pedestrian detection. Object detection has applications in many areas of computer vision, including image retrieval and video surveillance.
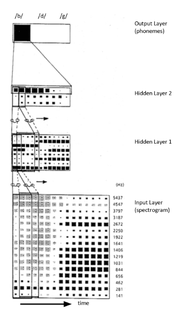
Time delay neural network (TDNN) is a multilayer artificial neural network architecture whose purpose is to 1) classify patterns with shift-invariance, and 2) model context at each layer of the network.
Video content analysis or video content analytics (VCA), also known as video analysis or video analytics (VA), is the capability of automatically analyzing video to detect and determine temporal and spatial events.
In deep learning, a convolutional neural network is a class of artificial neural network, most commonly applied to analyze visual imagery. They are also known as shift invariant or space invariant artificial neural networks (SIANN), based on the shared-weight architecture of the convolution kernels or filters that slide along input features and provide translation equivariant responses known as feature maps. Counter-intuitively, most convolutional neural networks are only equivariant, as opposed to invariant, to translation. They have applications in image and video recognition, recommender systems, image classification, image segmentation, medical image analysis, natural language processing, brain-computer interfaces, and financial time series.
Visual spatial attention is a form of visual attention that involves directing attention to a location in space. Similar to its temporal counterpart visual temporal attention, these attention modules have been widely implemented in video analytics in computer vision to provide enhanced performance and human interpretable explanation of deep learning models.
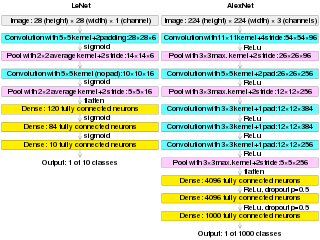
AlexNet is the name of a convolutional neural network (CNN) architecture, designed by Alex Krizhevsky in collaboration with Ilya Sutskever and Geoffrey Hinton, who was Krizhevsky's Ph.D. advisor.

In computer vision, object co-segmentation is a special case of image segmentation, which is defined as jointly segmenting semantically similar objects in multiple images or video frames.
Proposed as an extension of image epitomes in the field of video content analysis, video imprint is obtained by recasting video contents into a fixed-sized tensor representation regardless of video resolution or duration. Specifically, statistical characteristics are retained to some degrees so that common video recognition tasks can be carried out directly on such imprints, e.g., event retrieval, temporal action localization. It is claimed that both spatio-temporal interdependences are accounted for and redundancies are mitigated during the computation of video imprints.
In the context of neural networks, attention is a technique that mimics cognitive attention. The effect enhances the important parts of the input data and fades out the rest—the thought being that the network should devote more computing power to that small but important part of the data. Which part of the data is more important than others depends on the context and is learned through training data by gradient descent.

Video Super-Resolution (VSR) is the process of generating high-resolution video frames from the given low-resolution ones. Unlike single image super-resolution (SISR), the main goal is not only to restore more fine details while saving coarse ones, but also to preserve motion consistensy.
A Vision Transformer (ViT) is a transformer that is targeted at vision processing tasks such as image recognition.

