
Ribonucleic acid (RNA) is a polymeric molecule essential in various biological roles in coding, decoding, regulation and expression of genes. RNA and deoxyribonucleic acid (DNA) are nucleic acids. Along with lipids, proteins, and carbohydrates, nucleic acids constitute one of the four major macromolecules essential for all known forms of life. Like DNA, RNA is assembled as a chain of nucleotides, but unlike DNA, RNA is found in nature as a single strand folded onto itself, rather than a paired double strand. Cellular organisms use messenger RNA (mRNA) to convey genetic information that directs synthesis of specific proteins. Many viruses encode their genetic information using an RNA genome.

Ribosomes are macromolecular machines, found within all living cells, that perform biological protein synthesis. Ribosomes link amino acids together in the order specified by the codons of messenger RNA (mRNA) molecules to form polypeptide chains. Ribosomes consist of two major components: the small and large ribosomal subunits. Each subunit consists of one or more ribosomal RNA (rRNA) molecules and many ribosomal proteins. The ribosomes and associated molecules are also known as the translational apparatus.

RNA splicing, in molecular biology, is a form of RNA processing in which a newly made precursor messenger RNA (pre-mRNA) transcript is transformed into a mature messenger RNA (mRNA). During splicing, introns are removed and exons are joined together. For nuclear-encoded genes, splicing takes place within the nucleus either during or immediately after transcription. For those eukaryotic genes that contain introns, splicing is usually required in order to create an mRNA molecule that can be translated into protein. For many eukaryotic introns, splicing is carried out in a series of reactions which are catalyzed by the spliceosome, a complex of small nuclear ribonucleoproteins (snRNPs). Self-splicing introns, or ribozymes capable of catalyzing their own excision from their parent RNA molecule, also exist.

In molecular biology, RNA polymerase, is an enzyme that synthesizes RNA from a DNA template.
DNA primase is an enzyme involved in the replication of DNA and is a type of RNA polymerase. Primase catalyzes the synthesis of a short RNA segment called a primer complementary to a ssDNA template. After this elongation, the RNA piece is removed by a 5' to 3' exonuclease and refilled with DNA.
The 5′ untranslated region is the region of an mRNA that is directly upstream from the initiation codon. This region is important for the regulation of translation of a transcript by differing mechanisms in viruses, prokaryotes and eukaryotes. While called untranslated, the 5′ UTR or a portion of it is sometimes translated into a protein product. This product can then regulate the translation of the main coding sequence of the mRNA. In many organisms, however, the 5′ UTR is completely untranslated, instead forming complex secondary structure to regulate translation.
The Shine–Dalgarno (SD) sequence is a ribosomal binding site in bacterial and archaeal messenger RNA, generally located around 8 bases upstream of the start codon AUG. The RNA sequence helps recruit the ribosome to the messenger RNA (mRNA) to initiate protein synthesis by aligning the ribosome with the start codon. Once recruited, tRNA may add amino acids in sequence as dictated by the codons, moving downstream from the translational start site.
Bacterial translation is the process by which messenger RNA is translated into proteins in bacteria.
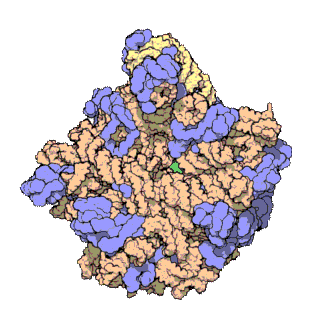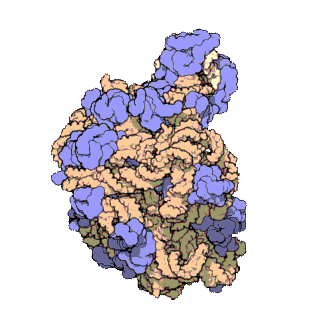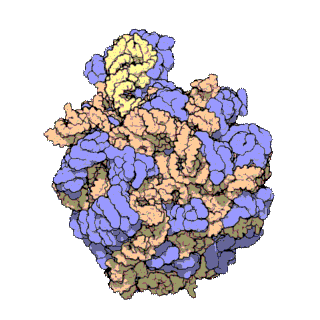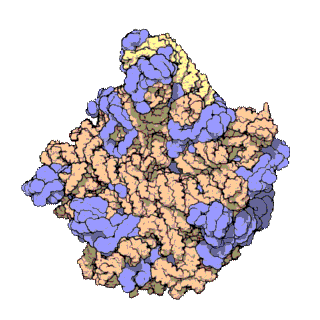
A ribosomal protein is any of the proteins that, in conjunction with rRNA, make up the ribosomal subunits involved in the cellular process of translation. E. coli, other bacteria and Archaea have a 30S small subunit and a 50S large subunit, whereas humans and yeasts have a 40S small subunit and a 60S large subunit. Equivalent subunits are frequently numbered differently between bacteria, Archaea, yeasts and humans.

EF-Tu is a prokaryotic elongation factor responsible for catalyzing the binding of an aminoacyl-tRNA (aa-tRNA) to the ribosome. It is a G-protein, and facilitates the selection and binding of an aa-tRNA to the A-site of the ribosome. As a reflection of its crucial role in translation, EF-Tu is one of the most abundant and highly conserved proteins in prokaryotes. It is found in eukaryotic mitochrondria as TUFM.
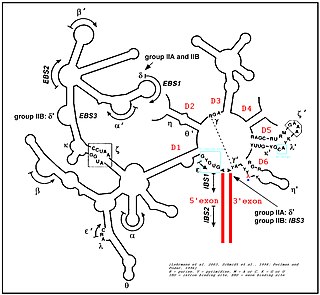
Group II introns are a large class of self-catalytic ribozymes and mobile genetic elements found within the genes of all three domains of life. Ribozyme activity can occur under high-salt conditions in vitro. However, assistance from proteins is required for in vivo splicing. In contrast to group I introns, intron excision occurs in the absence of GTP and involves the formation of a lariat, with an A-residue branchpoint strongly resembling that found in lariats formed during splicing of nuclear pre-mRNA. It is hypothesized that pre-mRNA splicing may have evolved from group II introns, due to the similar catalytic mechanism as well as the structural similarity of the Group II Domain V substructure to the U6/U2 extended snRNA. Finally, their ability to site-specifically mobilize to new DNA sites has been exploited as a tool for biotechnology.

In molecular biology, LSm proteins are a family of RNA-binding proteins found in virtually every cellular organism. LSm is a contraction of 'like Sm', because the first identified members of the LSm protein family were the Sm proteins. LSm proteins are defined by a characteristic three-dimensional structure and their assembly into rings of six or seven individual LSm protein molecules, and play a large number of various roles in mRNA processing and regulation.
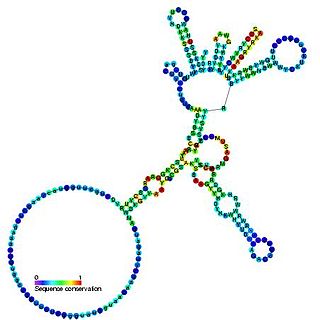
Group I introns are large self-splicing ribozymes. They catalyze their own excision from mRNA, tRNA and rRNA precursors in a wide range of organisms. The core secondary structure consists of nine paired regions (P1-P9). These fold to essentially two domains – the P4-P6 domain and the P3-P9 domain. The secondary structure mark-up for this family represents only this conserved core. Group I introns often have long open reading frames inserted in loop regions.

The signal recognition particle RNA, is part of the signal recognition particle (SRP) ribonucleoprotein complex. SRP recognizes the signal peptide and binds to the ribosome, halting protein synthesis. SRP-receptor is a protein that is embedded in a membrane, and which contains a transmembrane pore. When the SRP-ribosome complex binds to SRP-receptor, SRP releases the ribosome and drifts away. The ribosome resumes protein synthesis, but now the protein is moving through the SRP-receptor transmembrane pore.
Rev is a transactivating protein that is essential to the regulation of HIV-1 protein expression. A nuclear localization signal is encoded in the rev gene, which allows the Rev protein to be localized to the nucleus, where it is involved in the export of unspliced and incompletely spliced mRNAs. In the absence of Rev, mRNAs of the HIV-1 late (structural) genes are retained in the nucleus, preventing their translation.
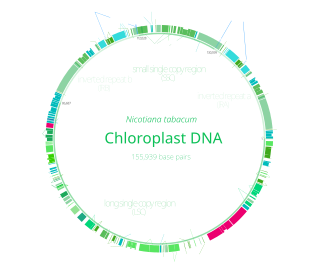
Chloroplasts have their own DNA, often abbreviated as cpDNA. It is also known as the plastome when referring to genomes of other plastids. Its existence was first proven in 1962. The first complete chloroplast genome sequences were published in 1986, Nicotiana tabacum (tobacco) by Sugiura and colleagues and Marchantia polymorpha (liverwort) by Ozeki et al. Since then, hundreds of chloroplast DNAs from various species have been sequenced, but they are mostly those of land plants and green algae—glaucophytes, red algae, and other algae groups are extremely underrepresented, potentially introducing some bias in views of "typical" chloroplast DNA structure and content.
Numerous key discoveries in biology have emerged from studies of RNA, including seminal work in the fields of biochemistry, genetics, microbiology, molecular biology, molecular evolution and structural biology. As of 2010, 30 scientists have been awarded Nobel Prizes for experimental work that includes studies of RNA. Specific discoveries of high biological significance are discussed in this article.

In molecular biology, the single-domain protein SUI1 is a translation initiation factor often found in the fungus, Saccharomyces cerevisiae but it is also found in other eukaryotes and prokaryotes as well as archaea. It is otherwise known as Eukaryotic translation initiation factor 1 (eIF1) in eukaryotes or YciH in bacteria.
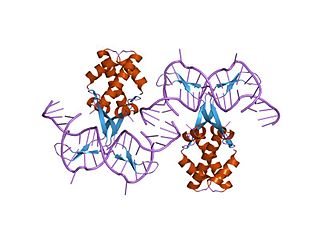
In molecular biology, bacterial DNA binding proteins are a family of small, usually basic proteins of about 90 residues that bind DNA and are known as histone-like proteins. Since bacterial binding proteins have a diversity of functions, it has been difficult to develop a common function for all of them. They are commonly referred to as histone-like and have many similar traits with the eukaryotic histone proteins. Eukaryotic histones package DNA to help it to fit in the nucleus, and they are known to be the most conserved proteins in nature. Examples include the HU protein in Escherichia coli, a dimer of closely related alpha and beta chains and in other bacteria can be a dimer of identical chains. HU-type proteins have been found in a variety of bacteria and archaea, and are also encoded in the chloroplast genome of some algae. The integration host factor (IHF), a dimer of closely related chains which is suggested to function in genetic recombination as well as in translational and transcriptional control is found in Enterobacteria and viral proteins including the African swine fever virus protein A104R.
Alice Barkan is an American molecular biologist and a professor of biology at the University of Oregon. She is known for her work on chloroplast gene regulation and protein synthesis.
