Discrete-time
Board games played with dice
A game of snakes and ladders or any other game whose moves are determined entirely by dice is a Markov chain, indeed, an absorbing Markov chain. This is in contrast to card games such as blackjack, where the cards represent a 'memory' of the past moves. To see the difference, consider the probability for a certain event in the game. In the above-mentioned dice games, the only thing that matters is the current state of the board. The next state of the board depends on the current state, and the next roll of the dice. It does not depend on how things got to their current state. In a game such as blackjack, a player can gain an advantage by remembering which cards have already been shown (and hence which cards are no longer in the deck), so the next state (or hand) of the game is not independent of the past states.
Random walk Markov chains
A center-biased random walk
Consider a random walk on the number line where, at each step, the position (call it x) may change by +1 (to the right) or −1 (to the left) with probabilities:


(where c is a constant greater than 0)
For example, if the constant, c, equals 1, the probabilities of a move to the left at positions x = −2,−1,0,1,2 are given by respectively. The random walk has a centering effect that weakens as c increases.

Since the probabilities depend only on the current position (value of x) and not on any prior positions, this biased random walk satisfies the definition of a Markov chain.
Gambling
Suppose that one starts with $10, and one wagers $1 on an unending, fair, coin toss indefinitely, or until all of the money is lost. If represents the number of dollars one has after n tosses, with , then the sequence is a Markov process. If one knows that one has $12 now, then it would be expected that with even odds, one will either have $11 or $13 after the next toss. This guess is not improved by the added knowledge that one started with $10, then went up to $11, down to $10, up to $11, and then to $12. The fact that the guess is not improved by the knowledge of earlier tosses showcases the Markov property, the memoryless property of a stochastic process. [1]



A model of language
This example came from Markov himself. [2] Markov chose 20,000 letters from Pushkin’s Eugene Onegin , classified them into vowels and consonants, and counted the transition probabilities.The stationary distribution is 43.2 percent vowels and 56.8 percent consonants, which is close to the actual count in the book. [3]

A simple weather model
The probabilities of weather conditions (modeled as either rainy or sunny), given the weather on the preceding day, can be represented by a transition matrix:

The matrix P represents the weather model in which a sunny day is 90% likely to be followed by another sunny day, and a rainy day is 50% likely to be followed by another rainy day. The columns can be labelled "sunny" and "rainy", and the rows can be labelled in the same order.

(P)i j is the probability that, if a given day is of type i, it will be followed by a day of type j.
Notice that the rows of P sum to 1: this is because P is a stochastic matrix.
Predicting the weather
The weather on day 0 (today) is known to be sunny. This is represented by an initial state vector in which the "sunny" entry is 100%, and the "rainy" entry is 0%:

The weather on day 1 (tomorrow) can be predicted by multiplying the state vector from day 0 by the transition matrix:

Thus, there is a 90% chance that day 1 will also be sunny.
The weather on day 2 (the day after tomorrow) can be predicted in the same way, from the state vector we computed for day 1:

or

General rules for day n are:


Steady state of the weather
In this example, predictions for the weather on more distant days change less and less on each subsequent day and tend towards a steady state vector. This vector represents the probabilities of sunny and rainy weather on all days, and is independent of the initial weather.
The steady state vector is defined as:

but converges to a strictly positive vector only if P is a regular transition matrix (that is, there is at least one Pn with all non-zero entries).
Since q is independent from initial conditions, it must be unchanged when transformed by P. [4] This makes it an eigenvector (with eigenvalue 1), and means it can be derived from P.
In layman's terms, the steady-state vector is the vector that, when we multiply it by P, we get the exact same vector back. [5] For the weather example, we can use this to set up a matrix equation:

and since they are a probability vector we know that

Solving this pair of simultaneous equations gives the steady state vector:

In conclusion, in the long term about 83.3% of days are sunny. Not all Markov processes have a steady state vector. In particular, the transition matrix must be regular. Otherwise, the state vectors will oscillate over time without converging.
Stock market
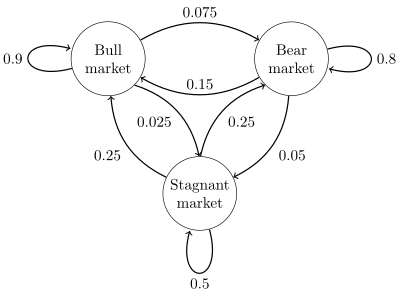
A state diagram for a simple example is shown in the figure on the right, using a directed graph to picture the state transitions. The states represent whether a hypothetical stock market is exhibiting a bull market, bear market, or stagnant market trend during a given week. According to the figure, a bull week is followed by another bull week 90% of the time, a bear week 7.5% of the time, and a stagnant week the other 2.5% of the time. Labeling the state space {1 = bull, 2 = bear, 3 = stagnant} the transition matrix for this example is

The distribution over states can be written as a stochastic row vector x with the relation x(n + 1) = x(n)P. So if at time n the system is in state x(n), then three time periods later, at time n + 3 the distribution is

In particular, if at time n the system is in state 2 (bear), then at time n + 3 the distribution is

Using the transition matrix it is possible to calculate, for example, the long-term fraction of weeks during which the market is stagnant, or the average number of weeks it will take to go from a stagnant to a bull market. Using the transition probabilities, the steady-state probabilities indicate that 62.5% of weeks will be in a bull market, 31.25% of weeks will be in a bear market and 6.25% of weeks will be stagnant, since:

A thorough development and many examples can be found in the on-line monograph Meyn & Tweedie 2005. [6]
A finite-state machine can be used as a representation of a Markov chain. Assuming a sequence of independent and identically distributed input signals (for example, symbols from a binary alphabet chosen by coin tosses), if the machine is in state y at time n, then the probability that it moves to state x at time n + 1 depends only on the current state.
