The primary market is the part of the capital market that deals with the issuance and sale of securities to purchasers directly by the issuer, with the issuer being paid the proceeds. A primary market means the market for new issues of securities, as distinguished from the secondary market, where previously issued securities are bought and sold. A market is primary if the proceeds of sales go to the issuer of the securities sold. Buyers buy securities that were not previously traded.
An initial public offering (IPO) or stock launch is a public offering in which shares of a company are sold to institutional investors and usually also to retail (individual) investors. An IPO is typically underwritten by one or more investment banks, who also arrange for the shares to be listed on one or more stock exchanges. Through this process, colloquially known as floating, or going public, a privately held company is transformed into a public company. Initial public offerings can be used to raise new equity capital for companies, to monetize the investments of private shareholders such as company founders or private equity investors, and to enable easy trading of existing holdings or future capital raising by becoming publicly traded.
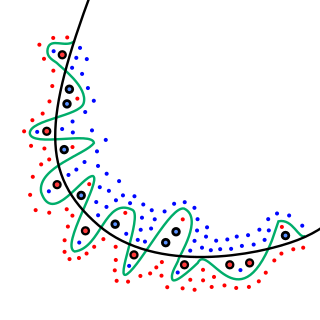
In mathematical modeling, overfitting is "the production of an analysis that corresponds too closely or exactly to a particular set of data, and may therefore fail to fit to additional data or predict future observations reliably". An overfitted model is a mathematical model that contains more parameters than can be justified by the data. In a mathematical sense, these parameters represent the degree of a polynomial. The essence of overfitting is to have unknowingly extracted some of the residual variation as if that variation represented underlying model structure.

Learning classifier systems, or LCS, are a paradigm of rule-based machine learning methods that combine a discovery component with a learning component. Learning classifier systems seek to identify a set of context-dependent rules that collectively store and apply knowledge in a piecewise manner in order to make predictions. This approach allows complex solution spaces to be broken up into smaller, simpler parts for the reinforcement learning that is inside artificial intelligence research.
Underwriting (UW) services are provided by some large financial institutions, such as banks, insurance companies and investment houses, whereby they guarantee payment in case of damage or financial loss and accept the financial risk for liability arising from such guarantee. An underwriting arrangement may be created in a number of situations including insurance, issues of security in a public offering, and bank lending, among others. The person or institution that agrees to sell a minimum number of securities of the company for commission is called the underwriter.
The secondary market, also called the aftermarket and follow on public offering, is the financial market in which previously issued financial instruments such as stock, bonds, options, and futures are bought and sold. The initial sale of the security by the issuer to a purchaser, who pays proceeds to the issuer, is the primary market. All sales after the initial sale of the security are sales in the secondary market. Whereas the term primary market refers to the market for new issues of securities, and "[a] market is primary if the proceeds of sales go to the issuer of the securities sold," the secondary market in contrast is the market created by the later trading of such securities.
Gross spread refers to the fees that underwriters receive for arranging and underwriting an offering of debt or equity securities. The gross spread for an initial public offering (IPO) can be higher than 10% while the gross spread on a debt offering can be as low as 0.05%.
Greenshoe, or over-allotment clause, is the term commonly used to describe a special arrangement in a U.S. registered share offering, for example an initial public offering (IPO), which enables the investment bank representing the underwriters to support the share price after the offering without putting their own capital at risk. This clause is codified as a provision in the underwriting agreement between the leading underwriter, the lead manager, and the issuer or vendor. The provision allows the underwriter to purchase up to 15% in additional company shares at the offering share price.
In statistics, the k-nearest neighbors algorithm (k-NN) is a non-parametric supervised learning method first developed by Evelyn Fix and Joseph Hodges in 1951, and later expanded by Thomas Cover. It is used for classification and regression. In both cases, the input consists of the k closest training examples in a data set. The output depends on whether k-NN is used for classification or regression:
In contract theory, signalling is the idea that one party credibly conveys some information about itself to another party.
A special-purpose acquisition company, also known as a "blank check company", is a shell corporation listed on a stock exchange with the purpose of acquiring a private company, thus making the private company public without going through the initial public offering process, which often carries significant procedural and regulatory burdens. According to the U.S. Securities and Exchange Commission (SEC), SPACs are created specifically to pool funds to finance a future merger or acquisition opportunity within a set timeframe; these opportunities usually have yet to be identified while raising funds.
Book building is a systematic process of generating, capturing, and recording investor demand for shares. Usually, the issuer appoints a major investment bank to act as a major securities underwriter or bookrunner.
Popular Science Predictions Exchange (PPX) was an online virtual prediction market run as part of the Popular Science website. The application was designed by the same group behind the Hollywood Stock Exchange using their virtual specialist application. Users traded virtual currency, known as POP$, based on the likelihood of a certain event being realized by a given date. Stock prices would range between POP$0 and POP$100 and were intended to reflect the general confidence of the users about that event. A stock at price POP$95 would mean roughly that users believed there to be a 95% chance of the event happening. If an event was realized by the given date, the stock will pay out POP$100 per share. A stock that did not occur by the closing date was worth POP$0 per share.

A French auction is a multiple-price auction used for pricing initial public offerings.
The technology company Facebook, Inc., held its initial public offering (IPO) on Friday, May 18, 2012. The IPO was one of the biggest in technology and Internet history, with a peak market capitalization of over $104 billion.
Following is a glossary of stock market terms.
The following outline is provided as an overview of and topical guide to machine learning:
Soft computing is an umbrella term used to describe types of algorithms that produce approximate solutions to unsolvable high-level problems in computer science. Typically, traditional hard-computing algorithms heavily rely on concrete data and mathematical models to produce solutions to problems. Soft computing was coined in the late 20th century. During this period, revolutionary research in three fields greatly impacted soft computing. Fuzzy logic is a computational paradigm that entertains the uncertainties in data by using levels of truth rather than rigid 0s and 1s in binary. Next, neural networks which are computational models influenced by human brain functions. Finally, evolutionary computation is a term to describe groups of algorithm that mimic natural processes such as evolution and natural selection.

Financial Technology Partners is an American boutique investment bank which focuses on the fintech sector.
Lawrence M. Benveniste is an American mathematician, financial strategist, and academic. He is the Asa Griggs Candler Professor of Finance at the Goizueta Business School at Emory University.