
Konqueror is a free and open-source web browser and file manager that provides web access and file-viewer functionality for file systems. It forms a core part of the KDE Software Compilation. Developed by volunteers, Konqueror can run on most Unix-like operating systems. The KDE community licenses and distributes Konqueror under GNU GPL-2.0-or-later.
Corpus linguistics is the study of a language as that language is expressed in its text corpus, its body of "real world" text. Corpus linguistics proposes that a reliable analysis of a language is more feasible with corpora collected in the field—the natural context ("realia") of that language—with minimal experimental interference.
RealAudio, or also spelled as Real Audio is a proprietary audio format developed by RealNetworks and first released in April 1995. It uses a variety of audio codecs, ranging from low-bitrate formats that can be used over dialup modems, to high-fidelity formats for music. It can also be used as a streaming audio format, that is played at the same time as it is downloaded. In the past, many internet radio stations used RealAudio to stream their programming over the internet in real time. In recent years, however, the format has become less common and has given way to more popular audio formats. RealAudio was heavily used by the BBC websites until 2009, though it was discontinued due to its declining use. BBC World Service, the last of the BBC websites to use RealAudio, discontinued its use in March 2011.

Eur-Lex is an official website of European Union law and other public documents of the European Union (EU), published in 24 official languages of the EU. The Official Journal (OJ) of the European Union is also published on EUR-Lex. Users can access EUR-Lex free of charge and also register for a free account, which offers extra features.

File Explorer, previously known as Windows Explorer, is a file manager application that is included with releases of the Microsoft Windows operating system from Windows 95 onwards. It provides a graphical user interface for accessing the file systems. It is also the component of the operating system that presents many user interface items on the screen such as the taskbar and desktop. Controlling the computer is possible without File Explorer running.
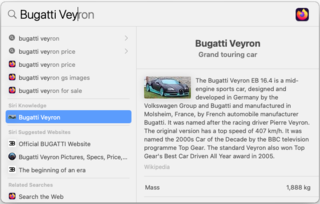
Spotlight is a system-wide desktop search feature of Apple's macOS and iOS operating systems. Spotlight is a selection-based search system, which creates an index of all items and files on the system. It is designed to allow the user to quickly locate a wide variety of items on the computer, including documents, pictures, music, applications, and System Settings. In addition, specific words in documents and in web pages in a web browser's history or bookmarks can be searched. It also allows the user to narrow down searches with creation dates, modification dates, sizes, types and other attributes. Spotlight also offers quick access to definitions from the built-in New Oxford American Dictionary and to calculator functionality. There are also command-line tools to perform functions such as Spotlight searches.
Desktop organizer software applications are applications that automatically create useful organizational structures from desktop content from heterogeneous types of content including email, files, contacts, companies, RSS news feeds, photos, music and chat sessions. The organization is based on a combination of automated scanning of metadata similar to data mining and manual tagging of content. The metadata stored in applications is correlated based on a structure for the data type handled by the organizer tool. For example, the email address of a sender of an email allows the email to be filed in a virtual folder for the author and company the author works for or a music file is filed by the musician and album label. The resulting visualization simplifies use of desktop content to navigate, search, and use related information stored on the desktop computer. The data in desktop organizer tools is normally stored in a database rather than the computer's file system in order to produce virtual folders where the same item can appear in multiple folders to the user based on its relationship to the folder.
The American National Corpus (ANC) is a text corpus of American English containing 22 million words of written and spoken data produced since 1990. Currently, the ANC includes a range of genres, including emerging genres such as email, tweets, and web data that are not included in earlier corpora such as the British National Corpus. It is annotated for part of speech and lemma, shallow parse, and named entities.
A video search engine is a web-based search engine which crawls the web for video content. Some video search engines parse externally hosted content while others allow content to be uploaded and hosted on their own servers. Some engines also allow users to search by video format type and by length of the clip. The video search results are usually accompanied by a thumbnail view of the video.
Metadata publishing is the process of making metadata data elements available to external users, both people and machines using a formal review process and a commitment to change control processes.
The British National Corpus (BNC) is a 100-million-word text corpus of samples of written and spoken English from a wide range of sources. The corpus covers British English of the late 20th century from a wide variety of genres, with the intention that it be a representative sample of spoken and written British English of that time. It is used in corpus linguistics for analysis of corpora.
An audio search engine is a web-based search engine which crawls the web for audio content. The information can consist of web pages, images, audio files, or another type of document. Various techniques exist for research on these engines.
The International Corpus of English(ICE) is a set of corpora representing varieties of English from around the world. Over twenty countries or groups of countries where English is the first language or an official second language are included.
The Corpus of Contemporary American English (COCA) is a one-billion-word corpus of contemporary American English. It was created by Mark Davies, retired professor of corpus linguistics at Brigham Young University (BYU).

Windows Search is a content index desktop search platform by Microsoft introduced in Windows Vista as a replacement for both the previous Indexing Service of Windows 2000 and the optional MSN Desktop Search for Windows XP and Windows Server 2003, designed to facilitate local and remote queries for files and non-file items in compatible applications including Windows Explorer. It was developed after the postponement of WinFS and introduced to Windows constituents originally touted as benefits of that platform.
The Survey of English Usage was the first research centre in Europe to carry out research with corpora. The Survey is based in the Department of English Language and Literature at University College London.
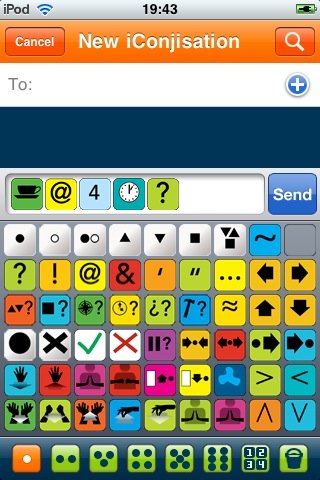
iConji is a free pictographic communication system based on an open, visual vocabulary of characters with built-in translations for most major languages.
HTML5 Audio is a subject of the HTML5 specification, incorporating audio input, playback, and synthesis, as well as speech to text, in the browser.
The Spoken English Corpus (SEC) is a speech corpus collection of recordings of spoken British English compiled during 1984-7. The corpus manual can be found on ICAME.
A corpus manager is a tool for multilingual corpus analysis, which allows effective searching in corpora.