
In biochemistry, denaturation is a process in which proteins or nucleic acids lose the quaternary structure, tertiary structure, and secondary structure which is present in their native state, by application of some external stress or compound such as a strong acid or base, a concentrated inorganic salt, an organic solvent, agitation and radiation or heat. If proteins in a living cell are denatured, this results in disruption of cell activity and possibly cell death. Protein denaturation is also a consequence of cell death. Denatured proteins can exhibit a wide range of characteristics, from conformational change and loss of solubility to aggregation due to the exposure of hydrophobic groups. The loss of solubility as a result of denaturation is called coagulation. Denatured proteins lose their 3D structure and therefore cannot function.

Nucleic acids are biopolymers, macromolecules, essential to all known forms of life. They are composed of nucleotides, which are the monomer components: a 5-carbon sugar, a phosphate group and a nitrogenous base. The two main classes of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). If the sugar is ribose, the polymer is RNA; if the sugar is deoxyribose, a version of ribose, the polymer is DNA.

Protein biosynthesis is a core biological process, occurring inside cells, balancing the loss of cellular proteins through the production of new proteins. Proteins perform a number of critical functions as enzymes, structural proteins or hormones. Protein synthesis is a very similar process for both prokaryotes and eukaryotes but there are some distinct differences.
A biomolecule or biological molecule is a loosely used term for molecules present in organisms that are essential to one or more typically biological processes, such as cell division, morphogenesis, or development. Biomolecules include the primary metabolites which are large macromolecules such as proteins, carbohydrates, lipids, and nucleic acids, as well as small molecules such as vitamins and hormones. A more general name for this class of material is biological materials. Biomolecules are an important element of living organisms, those biomolecules are often endogenous, produced within the organism but organisms usually need exogenous biomolecules, for example certain nutrients, to survive.

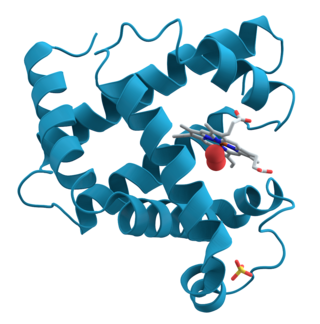
Structural bioinformatics is the branch of bioinformatics that is related to the analysis and prediction of the three-dimensional structure of biological macromolecules such as proteins, RNA, and DNA. It deals with generalizations about macromolecular 3D structures such as comparisons of overall folds and local motifs, principles of molecular folding, evolution, binding interactions, and structure/function relationships, working both from experimentally solved structures and from computational models. The term structural has the same meaning as in structural biology, and structural bioinformatics can be seen as a part of computational structural biology. The main objective of structural bioinformatics is the creation of new methods of analysing and manipulating biological macromolecular data in order to solve problems in biology and generate new knowledge.

A Hoogsteen base pair is a variation of base-pairing in nucleic acids such as the A•T pair. In this manner, two nucleobases, one on each strand, can be held together by hydrogen bonds in the major groove. A Hoogsteen base pair applies the N7 position of the purine base and C6 amino group, which bind the Watson–Crick (N3–C4) face of the pyrimidine base.
The history of molecular biology begins in the 1930s with the convergence of various, previously distinct biological and physical disciplines: biochemistry, genetics, microbiology, virology and physics. With the hope of understanding life at its most fundamental level, numerous physicists and chemists also took an interest in what would become molecular biology.
Nucleic acid structure prediction is a computational method to determine secondary and tertiary nucleic acid structure from its sequence. Secondary structure can be predicted from one or several nucleic acid sequences. Tertiary structure can be predicted from the sequence, or by comparative modeling.
Nucleic acid thermodynamics is the study of how temperature affects the nucleic acid structure of double-stranded DNA (dsDNA). The melting temperature (Tm) is defined as the temperature at which half of the DNA strands are in the random coil or single-stranded (ssDNA) state. Tm depends on the length of the DNA molecule and its specific nucleotide sequence. DNA, when in a state where its two strands are dissociated, is referred to as having been denatured by the high temperature.
Biomolecular engineering is the application of engineering principles and practices to the purposeful manipulation of molecules of biological origin. Biomolecular engineers integrate knowledge of biological processes with the core knowledge of chemical engineering in order to focus on molecular level solutions to issues and problems in the life sciences related to the environment, agriculture, energy, industry, food production, biotechnology and medicine.
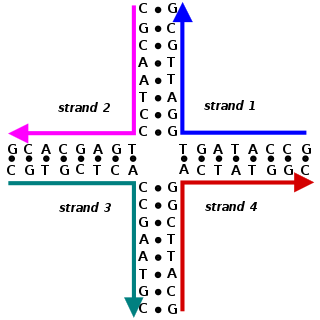
Nucleic acid design is the process of generating a set of nucleic acid base sequences that will associate into a desired conformation. Nucleic acid design is central to the fields of DNA nanotechnology and DNA computing. It is necessary because there are many possible sequences of nucleic acid strands that will fold into a given secondary structure, but many of these sequences will have undesired additional interactions which must be avoided. In addition, there are many tertiary structure considerations which affect the choice of a secondary structure for a given design.
Experimental approaches of determining the structure of nucleic acids, such as RNA and DNA, can be largely classified into biophysical and biochemical methods. Biophysical methods use the fundamental physical properties of molecules for structure determination, including X-ray crystallography, NMR and cryo-EM. Biochemical methods exploit the chemical properties of nucleic acids using specific reagents and conditions to assay the structure of nucleic acids. Such methods may involve chemical probing with specific reagents, or rely on native or analogue chemistry. Different experimental approaches have unique merits and are suitable for different experimental purposes.

Molecular models of DNA structures are representations of the molecular geometry and topology of deoxyribonucleic acid (DNA) molecules using one of several means, with the aim of simplifying and presenting the essential, physical and chemical, properties of DNA molecular structures either in vivo or in vitro. These representations include closely packed spheres made of plastic, metal wires for skeletal models, graphic computations and animations by computers, artistic rendering. Computer molecular models also allow animations and molecular dynamics simulations that are very important for understanding how DNA functions in vivo.
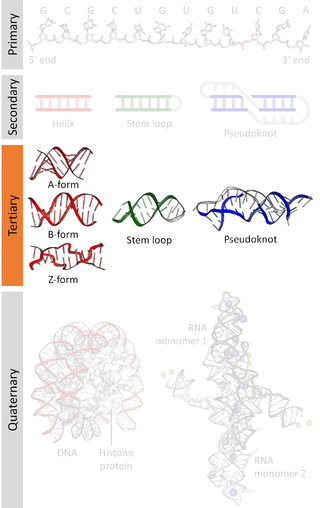
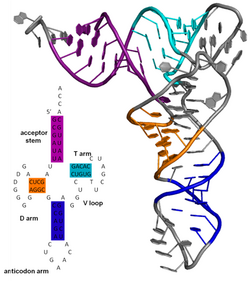
Nucleic acid tertiary structure is the three-dimensional shape of a nucleic acid polymer. RNA and DNA molecules are capable of diverse functions ranging from molecular recognition to catalysis. Such functions require a precise three-dimensional structure. While such structures are diverse and seemingly complex, they are composed of recurring, easily recognizable tertiary structural motifs that serve as molecular building blocks. Some of the most common motifs for RNA and DNA tertiary structure are described below, but this information is based on a limited number of solved structures. Many more tertiary structural motifs will be revealed as new RNA and DNA molecules are structurally characterized.

Nucleic acid structure refers to the structure of nucleic acids such as DNA and RNA. Chemically speaking, DNA and RNA are very similar. Nucleic acid structure is often divided into four different levels: primary, secondary, tertiary, and quaternary.

Nucleic acid secondary structure is the basepairing interactions within a single nucleic acid polymer or between two polymers. It can be represented as a list of bases which are paired in a nucleic acid molecule. The secondary structures of biological DNAs and RNAs tend to be different: biological DNA mostly exists as fully base paired double helices, while biological RNA is single stranded and often forms complex and intricate base-pairing interactions due to its increased ability to form hydrogen bonds stemming from the extra hydroxyl group in the ribose sugar.
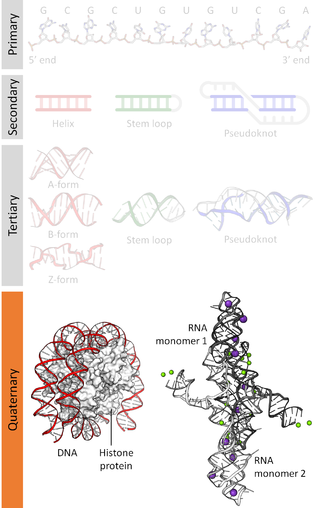
Nucleic acidquaternary structure refers to the interactions between separate nucleic acid molecules, or between nucleic acid molecules and proteins. The concept is analogous to protein quaternary structure, but as the analogy is not perfect, the term is used to refer to a number of different concepts in nucleic acids and is less commonly encountered. Similarly other biomolecules such as proteins, nucleic acids have four levels of structural arrangement: primary, secondary, tertiary, and quaternary structure. Primary structure is the linear sequence of nucleotides, secondary structure involves small local folding motifs, and tertiary structure is the 3D folded shape of nucleic acid molecule. In general, quaternary structure refers to 3D interactions between multiple subunits. In the case of nucleic acids, quaternary structure refers to interactions between multiple nucleic acid molecules or between nucleic acids and proteins. Nucleic acid quaternary structure is important for understanding DNA, RNA, and gene expression because quaternary structure can impact function. For example, when DNA is packed into heterochromatin, therefore exhibiting a type of quaternary structure, gene transcription will be inhibited.
PSI-blast based secondary structure PREDiction (PSIPRED) is a method used to investigate protein structure. It uses artificial neural network machine learning methods in its algorithm. It is a server-side program, featuring a website serving as a front-end interface, which can predict a protein's secondary structure from the primary sequence.
The ViennaRNA Package is a set of standalone programs and libraries used for prediction and analysis of RNA secondary structures. The source code for the package is distributed freely and compiled binaries are available for Linux, macOS and Windows platforms. The original paper has been cited over 2000 times.
Non-canonical base pairs are planar hydrogen bonded pairs of nucleobases, having hydrogen bonding patterns which differ from the patterns observed in Watson-Crick base pairs, as in the classic double helical DNA. The structures of polynucleotide strands of both DNA and RNA molecules can be understood in terms of sugar-phosphate backbones consisting of phosphodiester-linked D 2’ deoxyribofuranose sugar moieties, with purine or pyrimidine nucleobases covalently linked to them. Here, the N9 atoms of the purines, guanine and adenine, and the N1 atoms of the pyrimidines, cytosine and thymine, respectively, form glycosidic linkages with the C1’ atom of the sugars. These nucleobases can be schematically represented as triangles with one of their vertices linked to the sugar, and the three sides accounting for three edges through which they can form hydrogen bonds with other moieties, including with other nucleobases. The side opposite to the sugar linked vertex is traditionally called the Watson-Crick edge, since they are involved in forming the Watson-Crick base pairs which constitute building blocks of double helical DNA. The two sides adjacent to the sugar-linked vertex are referred to, respectively, as the Sugar and Hoogsteen edges.



-en.svg){kind=link}