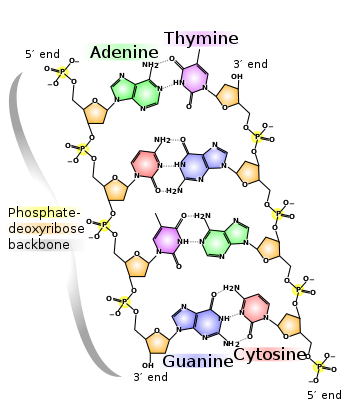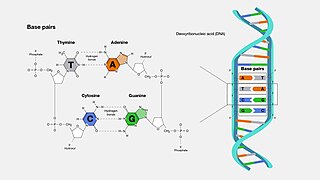
A base pair (bp) is a fundamental unit of double-stranded nucleic acids consisting of two nucleobases bound to each other by hydrogen bonds. They form the building blocks of the DNA double helix and contribute to the folded structure of both DNA and RNA. Dictated by specific hydrogen bonding patterns, "Watson–Crick" base pairs allow the DNA helix to maintain a regular helical structure that is subtly dependent on its nucleotide sequence. The complementary nature of this based-paired structure provides a redundant copy of the genetic information encoded within each strand of DNA. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA and RNA polymerase transcribes DNA into RNA. Many DNA-binding proteins can recognize specific base-pairing patterns that identify particular regulatory regions of genes.

Cytosine is one of the four nucleobases found in DNA and RNA, along with adenine, guanine, and thymine. It is a pyrimidine derivative, with a heterocyclic aromatic ring and two substituents attached. The nucleoside of cytosine is cytidine. In Watson–Crick base pairing, it forms three hydrogen bonds with guanine.
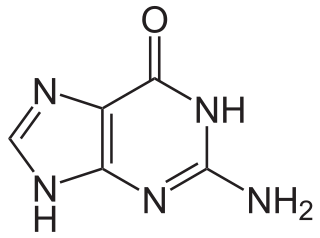
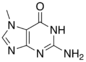
Guanine is one of the four main nucleobases found in the nucleic acids DNA and RNA, the others being adenine, cytosine, and thymine. In DNA, guanine is paired with cytosine. The guanine nucleoside is called guanosine.

Nucleic acids are large biomolecules that are crucial in all cells and viruses. They are composed of nucleotides, which are the monomer components: a 5-carbon sugar, a phosphate group and a nitrogenous base. The two main classes of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). If the sugar is ribose, the polymer is RNA; if the sugar is deoxyribose, a variant of ribose, the polymer is DNA.

Nucleotides are organic molecules composed of a nitrogenous base, a pentose sugar and a phosphate. They serve as monomeric units of the nucleic acid polymers – deoxyribonucleic acid (DNA) and ribonucleic acid (RNA), both of which are essential biomolecules within all life-forms on Earth. Nucleotides are obtained in the diet and are also synthesized from common nutrients by the liver.
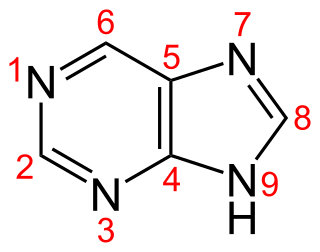
Purine is a heterocyclic aromatic organic compound that consists of two rings fused together. It is water-soluble. Purine also gives its name to the wider class of molecules, purines, which include substituted purines and their tautomers. They are the most widely occurring nitrogen-containing heterocycles in nature.
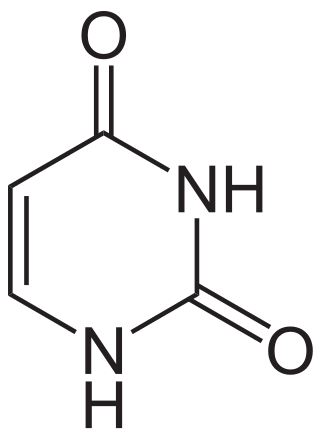
Pyrimidine is an aromatic, heterocyclic, organic compound similar to pyridine. One of the three diazines, it has nitrogen atoms at positions 1 and 3 in the ring. The other diazines are pyrazine and pyridazine.

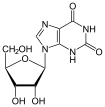
Adenine is a purine nucleobase. It is one of the four nucleobases in the nucleic acids of DNA, the other three being guanine (G), cytosine (C), and thymine (T). Adenine derivatives have various roles in biochemistry including cellular respiration, in the form of both the energy-rich adenosine triphosphate (ATP) and the cofactors nicotinamide adenine dinucleotide (NAD), flavin adenine dinucleotide (FAD) and Coenzyme A. It also has functions in protein synthesis and as a chemical component of DNA and RNA. The shape of adenine is complementary to either thymine in DNA or uracil in RNA.
Uracil is one of the four nucleobases in the nucleic acid RNA. The others are adenine (A), cytosine (C), and guanine (G). In RNA, uracil binds to adenine via two hydrogen bonds. In DNA, the uracil nucleobase is replaced by thymine (T). Uracil is a demethylated form of thymine.

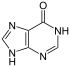
Thymine is one of the four nucleobases in the nucleic acid of DNA that are represented by the letters G–C–A–T. The others are adenine, guanine, and cytosine. Thymine is also known as 5-methyluracil, a pyrimidine nucleobase. In RNA, thymine is replaced by the nucleobase uracil. Thymine was first isolated in 1893 by Albrecht Kossel and Albert Neumann from calf thymus glands, hence its name.

Hypoxanthine is a naturally occurring purine derivative. It is occasionally found as a constituent of nucleic acids, where it is present in the anticodon of tRNA in the form of its nucleoside inosine. It has a tautomer known as 6-hydroxypurine. Hypoxanthine is a necessary additive in certain cells, bacteria, and parasite cultures as a substrate and nitrogen source. For example, it is commonly a required reagent in malaria parasite cultures, since Plasmodium falciparum requires a source of hypoxanthine for nucleic acid synthesis and energy metabolism.
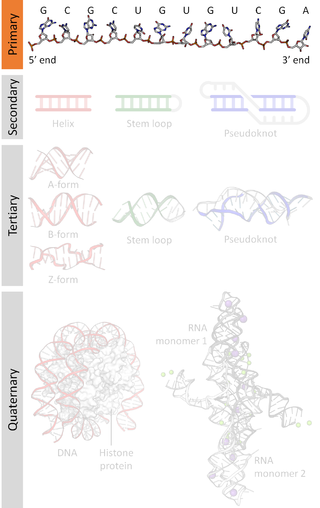
A nucleic acid sequence is a succession of bases within the nucleotides forming alleles within a DNA or RNA (GACU) molecule. This succession is denoted by a series of a set of five different letters that indicate the order of the nucleotides. By convention, sequences are usually presented from the 5' end to the 3' end. For DNA, with its double helix, there are two possible directions for the notated sequence; of these two, the sense strand is used. Because nucleic acids are normally linear (unbranched) polymers, specifying the sequence is equivalent to defining the covalent structure of the entire molecule. For this reason, the nucleic acid sequence is also termed the primary structure.

In biochemistry, a ribonucleotide is a nucleotide containing ribose as its pentose component. It is considered a molecular precursor of nucleic acids. Nucleotides are the basic building blocks of DNA and RNA. Ribonucleotides themselves are basic monomeric building blocks for RNA. Deoxyribonucleotides, formed by reducing ribonucleotides with the enzyme ribonucleotide reductase (RNR), are essential building blocks for DNA. There are several differences between DNA deoxyribonucleotides and RNA ribonucleotides. Successive nucleotides are linked together via phosphodiester bonds.
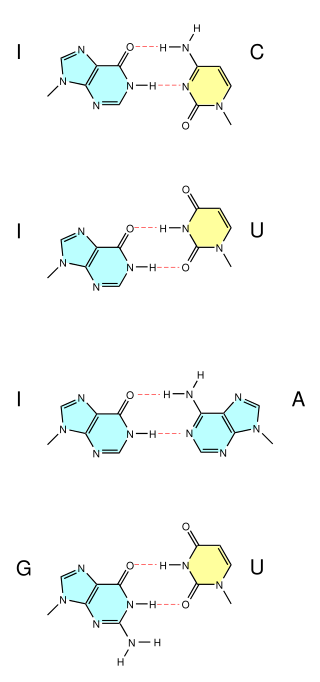
A wobble base pair is a pairing between two nucleotides in RNA molecules that does not follow Watson-Crick base pair rules. The four main wobble base pairs are guanine-uracil (G-U), hypoxanthine-uracil (I-U), hypoxanthine-adenine (I-A), and hypoxanthine-cytosine (I-C). In order to maintain consistency of nucleic acid nomenclature, "I" is used for hypoxanthine because hypoxanthine is the nucleobase of inosine; nomenclature otherwise follows the names of nucleobases and their corresponding nucleosides. The thermodynamic stability of a wobble base pair is comparable to that of a Watson-Crick base pair. Wobble base pairs are fundamental in RNA secondary structure and are critical for the proper translation of the genetic code.
A nucleoside triphosphate is a nucleoside containing a nitrogenous base bound to a 5-carbon sugar, with three phosphate groups bound to the sugar. They are the molecular precursors of both DNA and RNA, which are chains of nucleotides made through the processes of DNA replication and transcription. Nucleoside triphosphates also serve as a source of energy for cellular reactions and are involved in signalling pathways.

Nucleic acid metabolism is a collective term that refers to the variety of chemical reactions by which nucleic acids are either synthesized or degraded. Nucleic acids are polymers made up of a variety of monomers called nucleotides. Nucleotide synthesis is an anabolic mechanism generally involving the chemical reaction of phosphate, pentose sugar, and a nitrogenous base. Degradation of nucleic acids is a catabolic reaction and the resulting parts of the nucleotides or nucleobases can be salvaged to recreate new nucleotides. Both synthesis and degradation reactions require multiple enzymes to facilitate the event. Defects or deficiencies in these enzymes can lead to a variety of diseases.
Nucleic acid analogues are compounds which are analogous to naturally occurring RNA and DNA, used in medicine and in molecular biology research. Nucleic acids are chains of nucleotides, which are composed of three parts: a phosphate backbone, a pentose sugar, either ribose or deoxyribose, and one of four nucleobases. An analogue may have any of these altered. Typically the analogue nucleobases confer, among other things, different base pairing and base stacking properties. Examples include universal bases, which can pair with all four canonical bases, and phosphate-sugar backbone analogues such as PNA, which affect the properties of the chain . Nucleic acid analogues are also called xeno nucleic acids and represent one of the main pillars of xenobiology, the design of new-to-nature forms of life based on alternative biochemistries.

Nucleic acid structure refers to the structure of nucleic acids such as DNA and RNA. Chemically speaking, DNA and RNA are very similar. Nucleic acid structure is often divided into four different levels: primary, secondary, tertiary, and quaternary.

Nucleic acid secondary structure is the basepairing interactions within a single nucleic acid polymer or between two polymers. It can be represented as a list of bases which are paired in a nucleic acid molecule. The secondary structures of biological DNAs and RNAs tend to be different: biological DNA mostly exists as fully base paired double helices, while biological RNA is single stranded and often forms complex and intricate base-pairing interactions due to its increased ability to form hydrogen bonds stemming from the extra hydroxyl group in the ribose sugar.
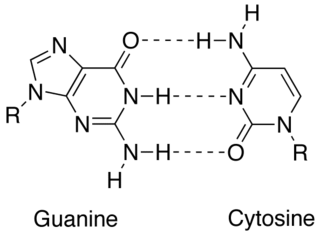
In molecular biology, complementarity describes a relationship between two structures each following the lock-and-key principle. In nature complementarity is the base principle of DNA replication and transcription as it is a property shared between two DNA or RNA sequences, such that when they are aligned antiparallel to each other, the nucleotide bases at each position in the sequences will be complementary, much like looking in the mirror and seeing the reverse of things. This complementary base pairing allows cells to copy information from one generation to another and even find and repair damage to the information stored in the sequences.