
In probability theory and statistics, the binomial distribution with parameters n and p is the discrete probability distribution of the number of successes in a sequence of n independent experiments, each asking a yes–no question, and each with its own Boolean-valued outcome: success or failure. A single success/failure experiment is also called a Bernoulli trial or Bernoulli experiment, and a sequence of outcomes is called a Bernoulli process; for a single trial, i.e., n = 1, the binomial distribution is a Bernoulli distribution. The binomial distribution is the basis for the popular binomial test of statistical significance.

In statistics, the Kolmogorov–Smirnov test is a nonparametric test of the equality of continuous, one-dimensional probability distributions that can be used to compare a sample with a reference probability distribution, or to compare two samples. In essence, the test answers the question "How likely is it that we would see a collection of samples like this if they were drawn from that probability distribution?" or, in the second case, "How likely is it that we would see two sets of samples like this if they were drawn from the same probability distribution?". It is named after Andrey Kolmogorov and Nikolai Smirnov.

In statistics and probability theory, the median is the value separating the higher half from the lower half of a data sample, a population, or a probability distribution. For a data set, it may be thought of as "the middle" value. The basic feature of the median in describing data compared to the mean is that it is not skewed by a small proportion of extremely large or small values, and therefore provides a better representation of the center. Median income, for example, may be a better way to describe center of the income distribution because increases in the largest incomes alone have no effect on median. For this reason, the median is of central importance in robust statistics.

In probability and statistics, Student's t-distribution is a continuous probability distribution that generalizes the standard normal distribution. Like the latter, it is symmetric around zero and bell-shaped.
In probability theory, Chebyshev's inequality guarantees that, for a wide class of probability distributions, no more than a certain fraction of values can be more than a certain distance from the mean. Specifically, no more than 1/k2 of the distribution's values can be k or more standard deviations away from the mean. The rule is often called Chebyshev's theorem, about the range of standard deviations around the mean, in statistics. The inequality has great utility because it can be applied to any probability distribution in which the mean and variance are defined. For example, it can be used to prove the weak law of large numbers.
In statistics, point estimation involves the use of sample data to calculate a single value which is to serve as a "best guess" or "best estimate" of an unknown population parameter. More formally, it is the application of a point estimator to the data to obtain a point estimate.
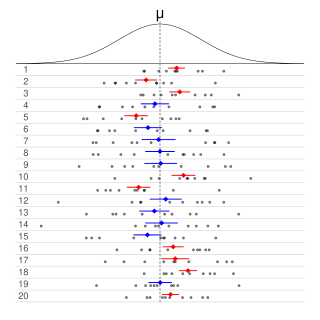
In frequentist statistics, a confidence interval (CI) is a range of estimates for an unknown parameter. A confidence interval is computed at a designated confidence level; the 95% confidence level is most common, but other levels, such as 90% or 99%, are sometimes used. The confidence level, degree of confidence or confidence coefficient represents the long-run proportion of CIs that theoretically contain the true value of the parameter; this is tantamount to the nominal coverage probability. For example, out of all intervals computed at the 95% level, 95% of them should contain the parameter's true value.

The standard error (SE) of a statistic is the standard deviation of its sampling distribution or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).
A tolerance interval (TI) is a statistical interval within which, with some confidence level, a specified sampled proportion of a population falls. "More specifically, a 100×p%/100×(1−α) tolerance interval provides limits within which at least a certain proportion (p) of the population falls with a given level of confidence (1−α)." "A (p, 1−α) tolerance interval (TI) based on a sample is constructed so that it would include at least a proportion p of the sampled population with confidence 1−α; such a TI is usually referred to as p-content − (1−α) coverage TI." "A (p, 1−α) upper tolerance limit (TL) is simply a 1−α upper confidence limit for the 100 p percentile of the population."
In probability theory, Hoeffding's inequality provides an upper bound on the probability that the sum of bounded independent random variables deviates from its expected value by more than a certain amount. Hoeffding's inequality was proven by Wassily Hoeffding in 1963.
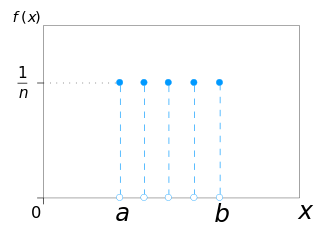
In probability theory and statistics, the discrete uniform distribution is a symmetric probability distribution wherein a finite number of values are equally likely to be observed; every one of n values has equal probability 1/n. Another way of saying "discrete uniform distribution" would be "a known, finite number of outcomes equally likely to happen".

In probability theory and statistics, the continuous uniform distributions or rectangular distributions are a family of symmetric probability distributions. Such a distribution describes an experiment where there is an arbitrary outcome that lies between certain bounds. The bounds are defined by the parameters, and which are the minimum and maximum values. The interval can either be closed or open. Therefore, the distribution is often abbreviated where stands for uniform distribution. The difference between the bounds defines the interval length; all intervals of the same length on the distribution's support are equally probable. It is the maximum entropy probability distribution for a random variable under no constraint other than that it is contained in the distribution's support.

In statistics, an empirical distribution function is the distribution function associated with the empirical measure of a sample. This cumulative distribution function is a step function that jumps up by 1/n at each of the n data points. Its value at any specified value of the measured variable is the fraction of observations of the measured variable that are less than or equal to the specified value.
In statistics, a binomial proportion confidence interval is a confidence interval for the probability of success calculated from the outcome of a series of success–failure experiments. In other words, a binomial proportion confidence interval is an interval estimate of a success probability p when only the number of experiments n and the number of successes nS are known.
Bootstrapping is any test or metric that uses random sampling with replacement, and falls under the broader class of resampling methods. Bootstrapping assigns measures of accuracy to sample estimates. This technique allows estimation of the sampling distribution of almost any statistic using random sampling methods.

In the theory of probability and statistics, the Dvoretzky–Kiefer–Wolfowitz–Massart inequality bounds how close an empirically determined distribution function will be to the distribution function from which the empirical samples are drawn. It is named after Aryeh Dvoretzky, Jack Kiefer, and Jacob Wolfowitz, who in 1956 proved the inequality

A probability box is a characterization of uncertain numbers consisting of both aleatoric and epistemic uncertainties that is often used in risk analysis or quantitative uncertainty modeling where numerical calculations must be performed. Probability bounds analysis is used to make arithmetic and logical calculations with p-boxes.
In probability theory, the rectified Gaussian distribution is a modification of the Gaussian distribution when its negative elements are reset to 0. It is essentially a mixture of a discrete distribution and a continuous distribution as a result of censoring.
In probability theory, concentration inequalities provide bounds on how a random variable deviates from some value. The law of large numbers of classical probability theory states that sums of independent random variables are, under very mild conditions, close to their expectation with a large probability. Such sums are the most basic examples of random variables concentrated around their mean. Recent results show that such behavior is shared by other functions of independent random variables.




















