Pattern recognition is the automated recognition of patterns and regularities in data. It has applications in statistical data analysis, signal processing, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. Pattern recognition has its origins in statistics and engineering; some modern approaches to pattern recognition include the use of machine learning, due to the increased availability of big data and a new abundance of processing power. These activities can be viewed as two facets of the same field of application, and they have undergone substantial development over the past few decades.
In mathematics, the Laplace operator or Laplacian is a differential operator given by the divergence of the gradient of a scalar function on Euclidean space. It is usually denoted by the symbols , (where is the nabla operator), or . In a Cartesian coordinate system, the Laplacian is given by the sum of second partial derivatives of the function with respect to each independent variable. In other coordinate systems, such as cylindrical and spherical coordinates, the Laplacian also has a useful form. Informally, the Laplacian Δf (p) of a function f at a point p measures by how much the average value of f over small spheres or balls centered at p deviates from f (p).

In physics and mathematics, the Lorentz group is the group of all Lorentz transformations of Minkowski spacetime, the classical and quantum setting for all (non-gravitational) physical phenomena. The Lorentz group is named for the Dutch physicist Hendrik Lorentz.
In probability theory and statistics, a Gaussian process is a stochastic process, such that every finite collection of those random variables has a multivariate normal distribution, i.e. every finite linear combination of them is normally distributed. The distribution of a Gaussian process is the joint distribution of all those random variables, and as such, it is a distribution over functions with a continuous domain, e.g. time or space.
In mathematics, and specifically differential geometry, a connection form is a manner of organizing the data of a connection using the language of moving frames and differential forms.
In physics, the Hamilton–Jacobi equation, named after William Rowan Hamilton and Carl Gustav Jacob Jacobi, is an alternative formulation of classical mechanics, equivalent to other formulations such as Newton's laws of motion, Lagrangian mechanics and Hamiltonian mechanics. The Hamilton–Jacobi equation is particularly useful in identifying conserved quantities for mechanical systems, which may be possible even when the mechanical problem itself cannot be solved completely.
In mathematics, a π-system on a set is a collection of certain subsets of such that
The Franz–Keldysh effect is a change in optical absorption by a semiconductor when an electric field is applied. The effect is named after the German physicist Walter Franz and Russian physicist Leonid Keldysh.
In many-body theory, the term Green's function is sometimes used interchangeably with correlation function, but refers specifically to correlators of field operators or creation and annihilation operators.
Linear Programming Boosting (LPBoost) is a supervised classifier from the boosting family of classifiers. LPBoost maximizes a margin between training samples of different classes and hence also belongs to the class of margin-maximizing supervised classification algorithms. Consider a classification function
One-shot learning is an object categorization problem, found mostly in computer vision. Whereas most machine learning-based object categorization algorithms require training on hundreds or thousands of examples, one-shot learning aims to classify objects from one, or only a few, examples. The term few-shot learning is also used for these problems, especially when more than one example is needed.

In mathematics, especially in the area of mathematical analysis known as dynamical systems theory, a linear flow on the torus is a flow on the n-dimensional torus
Least-squares support-vector machines (LS-SVM) for statistics and in statistical modeling, are least-squares versions of support-vector machines (SVM), which are a set of related supervised learning methods that analyze data and recognize patterns, and which are used for classification and regression analysis. In this version one finds the solution by solving a set of linear equations instead of a convex quadratic programming (QP) problem for classical SVMs. Least-squares SVM classifiers were proposed by Johan Suykens and Joos Vandewalle. LS-SVMs are a class of kernel-based learning methods.
In optics, the Fraunhofer diffraction equation is used to model the diffraction of waves when the diffraction pattern is viewed at a long distance from the diffracting object, and also when it is viewed at the focal plane of an imaging lens.
Calculations in the Newman–Penrose (NP) formalism of general relativity normally begin with the construction of a complex null tetrad, where is a pair of real null vectors and is a pair of complex null vectors. These tetrad vectors respect the following normalization and metric conditions assuming the spacetime signature

Symmetries in quantum mechanics describe features of spacetime and particles which are unchanged under some transformation, in the context of quantum mechanics, relativistic quantum mechanics and quantum field theory, and with applications in the mathematical formulation of the standard model and condensed matter physics. In general, symmetry in physics, invariance, and conservation laws, are fundamentally important constraints for formulating physical theories and models. In practice, they are powerful methods for solving problems and predicting what can happen. While conservation laws do not always give the answer to the problem directly, they form the correct constraints and the first steps to solving a multitude of problems.
Bayesian hierarchical modelling is a statistical model written in multiple levels that estimates the parameters of the posterior distribution using the Bayesian method. The sub-models combine to form the hierarchical model, and Bayes' theorem is used to integrate them with the observed data and account for all the uncertainty that is present. The result of this integration is the posterior distribution, also known as the updated probability estimate, as additional evidence on the prior distribution is acquired.
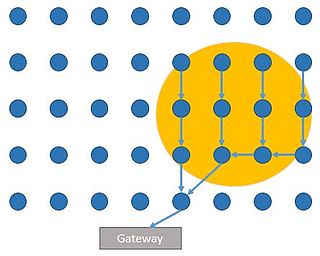
This article is about event detection for WSN.
The product of exponentials (POE) method is a robotics convention for mapping the links of a spatial kinematic chain. It is an alternative to Denavit–Hartenberg parameterization. While the latter method uses the minimal number of parameters to represent joint motions, the former method has a number of advantages: uniform treatment of prismatic and revolute joints, definition of only two reference frames, and an easy geometric interpretation from the use of screw axes for each joint.
Paden–Kahan subproblems are a set of solved geometric problems which occur frequently in inverse kinematics of common robotic manipulators. Although the set of problems is not exhaustive, it may be used to simplify inverse kinematic analysis for many industrial robots.