In computing, online analytical processing, or OLAP, is an approach to quickly answer multi-dimensional analytical (MDA) queries. OLAP is part of the broader category of business intelligence, which also encompasses relational databases, report writing and data mining. Typical applications of OLAP include business reporting for sales, marketing, management reporting, business process management (BPM), budgeting and forecasting, financial reporting and similar areas, with new applications emerging, such as agriculture.

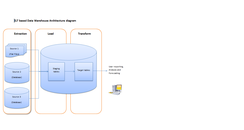
In computing, extract, transform, load (ETL) is a three-phase process where data is extracted from an input source, transformed, and loaded into an output data container. The data can be collated from one or more sources and it can also be output to one or more destinations. ETL processing is typically executed using software applications but it can also be done manually by system operators. ETL software typically automates the entire process and can be run manually or on recurring schedules either as single jobs or aggregated into a batch of jobs.

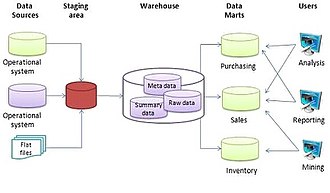
A data mart is a structure/access pattern specific to data warehouse environments, used to retrieve client-facing data. The data mart is a subset of the data warehouse and is usually oriented to a specific business line or team. Whereas data warehouses have an enterprise-wide depth, the information in data marts pertains to a single department. In some deployments, each department or business unit is considered the owner of its data mart including all the hardware, software and data. This enables each department to isolate the use, manipulation and development of their data. In other deployments where conformed dimensions are used, this business unit owner will not hold true for shared dimensions like customer, product, etc.

In computing, the star schema or star model is the simplest style of data mart schema and is the approach most widely used to develop data warehouses and dimensional data marts. The star schema consists of one or more fact tables referencing any number of dimension tables. The star schema is an important special case of the snowflake schema, and is more effective for handling simpler queries.
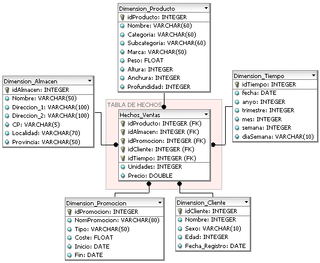
In data warehousing, a fact table consists of the measurements, metrics or facts of a business process. It is located at the center of a star schema or a snowflake schema surrounded by dimension tables. Where multiple fact tables are used, these are arranged as a fact constellation schema. A fact table typically has two types of columns: those that contain facts and those that are a foreign key to dimension tables. The primary key of a fact table is usually a composite key that is made up of all of its foreign keys. Fact tables contain the content of the data warehouse and store different types of measures like additive, non-additive, and semi-additive measures.

In computing, a snowflake schema or snowflake model is a logical arrangement of tables in a multidimensional database such that the entity relationship diagram resembles a snowflake shape. The snowflake schema is represented by centralized fact tables which are connected to multiple dimensions. "Snowflaking" is a method of normalizing the dimension tables in a star schema. When it is completely normalized along all the dimension tables, the resultant structure resembles a snowflake with the fact table in the middle. The principle behind snowflaking is normalization of the dimension tables by removing low cardinality attributes and forming separate tables.
Essbase is a multidimensional database management system (MDBMS) that provides a platform upon which to build analytic applications. Essbase began as a product from Arbor Software, which merged with Hyperion Software in 1998. Oracle Corporation acquired Hyperion Solutions Corporation in 2007. Until late 2005 IBM also marketed an OEM version of Essbase as DB2 OLAP Server.
Online transaction processing (OLTP) is a type of database system used in transaction-oriented applications, such as many operational systems. "Online" refers to that such systems are expected to respond to user requests and process them in real-time. The term is contrasted with online analytical processing (OLAP) which instead focuses on data analysis.

A dimension is a structure that categorizes facts and measures in order to enable users to answer business questions. Commonly used dimensions are people, products, place and time.
Ralph Kimball is an author on the subject of data warehousing and business intelligence. He is one of the original architects of data warehousing and is known for long-term convictions that data warehouses must be designed to be understandable and fast. His bottom-up methodology, also known as dimensional modeling or the Kimball methodology, is one of the two main data warehousing methodologies alongside Bill Inmon.
According to Ralph Kimball, in a data warehouse, a degenerate dimension is a dimension key in the fact table that does not have its own dimension table, because all the interesting attributes have been placed in analytic dimensions. The term "degenerate dimension" was originated by Ralph Kimball.
Dimensional modeling (DM) is part of the Business Dimensional Lifecycle methodology developed by Ralph Kimball which includes a set of methods, techniques and concepts for use in data warehouse design. The approach focuses on identifying the key business processes within a business and modelling and implementing these first before adding additional business processes, as a bottom-up approach. An alternative approach from Inmon advocates a top down design of the model of all the enterprise data using tools such as entity-relationship modeling (ER).
A column-oriented DBMS or columnar DBMS is a database management system (DBMS) that stores data tables by column rather than by row. Benefits include more efficient access to data when only querying a subset of columns, and more options for data compression. However, they are typically less efficient for inserting new data.
Operational database management systems, are used to update data in real-time. These types of databases allow users to do more than simply view archived data. Operational databases allow you to modify that data, doing it in real-time. OLTP databases provide transactions as main abstraction to guarantee data consistency that guarantee the so-called ACID properties. Basically, the consistency of the data is guaranteed in the case of failures and/or concurrent access to the data.

Datavault or data vault modeling is a database modeling method that is designed to provide long-term historical storage of data coming in from multiple operational systems. It is also a method of looking at historical data that deals with issues such as auditing, tracing of data, loading speed and resilience to change as well as emphasizing the need to trace where all the data in the database came from. This means that every row in a data vault must be accompanied by record source and load date attributes, enabling an auditor to trace values back to the source. The concept was published in 2000 by Dan Linstedt.
The enterprise bus matrix is a data warehouse planning tool and model created by Ralph Kimball, and is part of the data warehouse bus architecture. The matrix is the logical definition of one of the core concepts of Kimball’s approach to dimensional modeling conformed dimension.
The following is provided as an overview of and topical guide to databases:

SAP HANA is an in-memory, column-oriented, relational database management system developed and marketed by SAP SE. Its primary function as the software running a database server is to store and retrieve data as requested by the applications. In addition, it performs advanced analytics and includes extract, transform, load (ETL) capabilities as well as an application server.
Hybrid transaction/analytical processing (HTAP) is a term created by Gartner Inc., an information technology research and advisory company, in its early 2014 research report Hybrid Transaction/Analytical Processing Will Foster Opportunities for Dramatic Business Innovation. As defined by Gartner:
Hybrid transaction/analytical processing (HTAP) is an emerging application architecture that "breaks the wall" between transaction processing and analytics. It enables more informed and "in business real time" decision making.
The functional database model is used to support analytics applications such as financial planning and performance management. The functional database model, or the functional model for short, is different from but complementary to the relational model. The functional model is also distinct from other similarly named concepts, including the DAPLEX functional database model and functional language databases.