
Computer science is the study of computation, information, and automation. Computer science spans theoretical disciplines to applied disciplines. Though more often considered an academic discipline, computer science is closely related to computer programming.
Data mining is the process of extracting and discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems. Data mining is an interdisciplinary subfield of computer science and statistics with an overall goal of extracting information from a data set and transforming the information into a comprehensible structure for further use. Data mining is the analysis step of the "knowledge discovery in databases" process, or KDD. Aside from the raw analysis step, it also involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating.

Computational biology refers to the use of data analysis, mathematical modeling and computational simulations to understand biological systems and relationships. An intersection of computer science, biology, and big data, the field also has foundations in applied mathematics, chemistry, and genetics. It differs from biological computing, a subfield of computer science and engineering which uses bioengineering to build computers.
Computer science is the study of the theoretical foundations of information and computation and their implementation and application in computer systems. One well known subject classification system for computer science is the ACM Computing Classification System devised by the Association for Computing Machinery.
Text mining, text data mining (TDM) or text analytics is the process of deriving high-quality information from text. It involves "the discovery by computer of new, previously unknown information, by automatically extracting information from different written resources." Written resources may include websites, books, emails, reviews, and articles. High-quality information is typically obtained by devising patterns and trends by means such as statistical pattern learning. According to Hotho et al. (2005) we can distinguish between three different perspectives of text mining: information extraction, data mining, and a knowledge discovery in databases (KDD) process. Text mining usually involves the process of structuring the input text, deriving patterns within the structured data, and finally evaluation and interpretation of the output. 'High quality' in text mining usually refers to some combination of relevance, novelty, and interest. Typical text mining tasks include text categorization, text clustering, concept/entity extraction, production of granular taxonomies, sentiment analysis, document summarization, and entity relation modeling.

Analytics is the systematic computational analysis of data or statistics. It is used for the discovery, interpretation, and communication of meaningful patterns in data. It also entails applying data patterns toward effective decision-making. It can be valuable in areas rich with recorded information; analytics relies on the simultaneous application of statistics, computer programming, and operations research to quantify performance.

Computational sociology is a branch of sociology that uses computationally intensive methods to analyze and model social phenomena. Using computer simulations, artificial intelligence, complex statistical methods, and analytic approaches like social network analysis, computational sociology develops and tests theories of complex social processes through bottom-up modeling of social interactions.
Human-centered computing (HCC) studies the design, development, and deployment of mixed-initiative human-computer systems. It is emerged from the convergence of multiple disciplines that are concerned both with understanding human beings and with the design of computational artifacts. Human-centered computing is closely related to human-computer interaction and information science. Human-centered computing is usually concerned with systems and practices of technology use while human-computer interaction is more focused on ergonomics and the usability of computing artifacts and information science is focused on practices surrounding the collection, manipulation, and use of information.
In predictive analytics, data science, machine learning and related fields, concept drift or drift is an evolution of data that invalidates the data model. It happens when the statistical properties of the target variable, which the model is trying to predict, change over time in unforeseen ways. This causes problems because the predictions become less accurate as time passes. Drift detection and drift adaptation are of paramount importance in the fields that involve dynamically changing data and data models.

Data and information visualization is the practice of designing and creating easy-to-communicate and easy-to-understand graphic or visual representations of a large amount of complex quantitative and qualitative data and information with the help of static, dynamic or interactive visual items. Typically based on data and information collected from a certain domain of expertise, these visualizations are intended for a broader audience to help them visually explore and discover, quickly understand, interpret and gain important insights into otherwise difficult-to-identify structures, relationships, correlations, local and global patterns, trends, variations, constancy, clusters, outliers and unusual groupings within data. When intended for the general public to convey a concise version of known, specific information in a clear and engaging manner, it is typically called information graphics.
In data analysis, anomaly detection is generally understood to be the identification of rare items, events or observations which deviate significantly from the majority of the data and do not conform to a well defined notion of normal behavior. Such examples may arouse suspicions of being generated by a different mechanism, or appear inconsistent with the remainder of that set of data.

In common usage, data is a collection of discrete or continuous values that convey information, describing the quantity, quality, fact, statistics, other basic units of meaning, or simply sequences of symbols that may be further interpreted formally. A datum is an individual value in a collection of data. Data is usually organized into structures such as tables that provide additional context and meaning, and which may themselves be used as data in larger structures. Data may be used as variables in a computational process. Data may represent abstract ideas or concrete measurements. Data is commonly used in scientific research, economics, and in virtually every other form of human organizational activity. Examples of data sets include price indices, unemployment rates, literacy rates, and census data. In this context, data represents the raw facts and figures from which useful information can be extracted.
Computational thinking (CT) refers to the thought processes involved in formulating problems so their solutions can be represented as computational steps and algorithms. In education, CT is a set of problem-solving methods that involve expressing problems and their solutions in ways that a computer could also execute. It involves automation of processes, but also using computing to explore, analyze, and understand processes.
Computer science education or computing education is the field of teaching and learning the discipline of computer science, and computational thinking. The field of computer science education encompasses a wide range of topics, from basic programming skills to advanced algorithm design and data analysis. It is a rapidly growing field that is essential to preparing students for careers in the technology industry and other fields that require computational skills.
Social media mining is the process of obtaining big data from user-generated content on social media sites and mobile apps in order to extract actionable patterns, form conclusions about users, and act upon the information, often for the purpose of advertising to users or conducting research. The term is an analogy to the resource extraction process of mining for rare minerals. Resource extraction mining requires mining companies to shift through vast quantities of raw ore to find the precious minerals; likewise, social media mining requires human data analysts and automated software programs to shift through massive amounts of raw social media data in order to discern patterns and trends relating to social media usage, online behaviours, sharing of content, connections between individuals, online buying behaviour, and more. These patterns and trends are of interest to companies, governments and not-for-profit organizations, as these organizations can use these patterns and trends to design their strategies or introduce new programs, new products, processes or services.
Emotion recognition is the process of identifying human emotion. People vary widely in their accuracy at recognizing the emotions of others. Use of technology to help people with emotion recognition is a relatively nascent research area. Generally, the technology works best if it uses multiple modalities in context. To date, the most work has been conducted on automating the recognition of facial expressions from video, spoken expressions from audio, written expressions from text, and physiology as measured by wearables.
A Master of Science in Data Science is an interdisciplinary degree program designed to provide studies in scientific methods, processes, and systems to extract knowledge or insights from data in various forms, either structured or unstructured, similar to data mining.
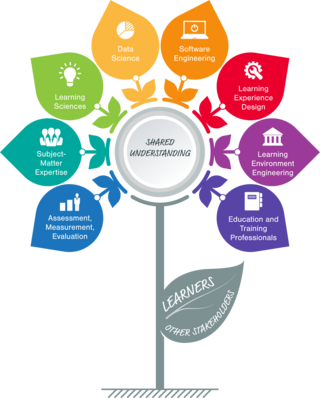
Learning Engineering is the systematic application of evidence-based principles and methods from educational technology and the learning sciences to create engaging and effective learning experiences, support the difficulties and challenges of learners as they learn, and come to better understand learners and learning. It emphasizes the use of a human-centered design approach in conjunction with analyses of rich data sets to iteratively develop and improve those designs to address specific learning needs, opportunities, and problems, often with the help of technology. Working with subject-matter and other experts, the Learning Engineer deftly combines knowledge, tools, and techniques from a variety of technical, pedagogical, empirical, and design-based disciplines to create effective and engaging learning experiences and environments and to evaluate the resulting outcomes. While doing so, the Learning Engineer strives to generate processes and theories that afford generalization of best practices, along with new tools and infrastructures that empower others to create their own learning designs based on those best practices.
Biomedical data science is a multidisciplinary field which leverages large volumes of data to promote biomedical innovation and discovery. Biomedical data science draws from various fields including Biostatistics, Biomedical informatics, and machine learning, with the goal of understanding biological and medical data. It can be viewed as the study and application of data science to solve biomedical problems. Modern biomedical datasets often have specific features which make their analyses difficult, including:


