
In probability theory and statistics, the binomial distribution with parameters n and p is the discrete probability distribution of the number of successes in a sequence of n independent experiments, each asking a yes–no question, and each with its own Boolean-valued outcome: success or failure. A single success/failure experiment is also called a Bernoulli trial or Bernoulli experiment, and a sequence of outcomes is called a Bernoulli process; for a single trial, i.e., n = 1, the binomial distribution is a Bernoulli distribution. The binomial distribution is the basis for the popular binomial test of statistical significance.
In mathematics, the Lp spaces are function spaces defined using a natural generalization of the p-norm for finite-dimensional vector spaces. They are sometimes called Lebesgue spaces, named after Henri Lebesgue, although according to the Bourbaki group they were first introduced by Frigyes Riesz.

Multidimensional scaling (MDS) is a means of visualizing the level of similarity of individual cases of a data set. MDS is used to translate distances between each pair of objects in a set into a configuration of points mapped into an abstract Cartesian space.

In probability theory, the total variation distance is a distance measure for probability distributions. It is an example of a statistical distance metric, and is sometimes called the statistical distance, statistical difference or variational distance.
In mathematics, a norm is a function from a real or complex vector space to the non-negative real numbers that behaves in certain ways like the distance from the origin: it commutes with scaling, obeys a form of the triangle inequality, and is zero only at the origin. In particular, the Euclidean distance in a Euclidean space is defined by a norm on the associated Euclidean vector space, called the Euclidean norm, the 2-norm, or, sometimes, the magnitude of the vector. This norm can be defined as the square root of the inner product of a vector with itself.
In mathematical statistics, the Kullback–Leibler (KL) divergence, denoted , is a type of statistical distance: a measure of how one probability distribution P is different from a second, reference probability distribution Q. A simple interpretation of the KL divergence of P from Q is the expected excess surprise from using Q as a model instead of P when the actual distribution is P. While it is a measure of how different two distributions are, and in some sense is thus a "distance", it is not actually a metric, which is the most familiar and formal type of distance. In particular, it is not symmetric in the two distributions, and does not satisfy the triangle inequality. Instead, in terms of information geometry, it is a type of divergence, a generalization of squared distance, and for certain classes of distributions, it satisfies a generalized Pythagorean theorem.

In mathematics, the real coordinate space or real coordinate n-space, of dimension n, denoted Rn or , is the set of all ordered n-tuples of real numbers, that is the set of all sequences of n real numbers, also known as coordinate vectors. Special cases are called the real lineR1, the real coordinate planeR2, and the real coordinate three-dimensional spaceR3. With component-wise addition and scalar multiplication, it is a real vector space.
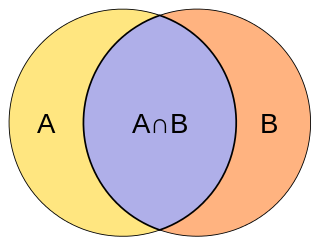
The Jaccard index, also known as the Jaccard similarity coefficient, is a statistic used for gauging the similarity and diversity of sample sets.
In quantum mechanics, notably in quantum information theory, fidelity is a measure of the "closeness" of two quantum states. It expresses the probability that one state will pass a test to identify as the other. The fidelity is not a metric on the space of density matrices, but it can be used to define the Bures metric on this space.
In the mathematical discipline of graph theory, the expander walk sampling theorem intuitively states that sampling vertices in an expander graph by doing relatively short random walk can simulate sampling the vertices independently from a uniform distribution. The earliest version of this theorem is due to Ajtai, Komlós & Szemerédi (1987), and the more general version is typically attributed to Gillman (1998).
In mathematics and economics, transportation theory or transport theory is a name given to the study of optimal transportation and allocation of resources. The problem was formalized by the French mathematician Gaspard Monge in 1781.
In mathematics, the Wasserstein distance or Kantorovich–Rubinstein metric is a distance function defined between probability distributions on a given metric space . It is named after Leonid Vaseršteĭn.
Stein's method is a general method in probability theory to obtain bounds on the distance between two probability distributions with respect to a probability metric. It was introduced by Charles Stein, who first published it in 1972, to obtain a bound between the distribution of a sum of -dependent sequence of random variables and a standard normal distribution in the Kolmogorov (uniform) metric and hence to prove not only a central limit theorem, but also bounds on the rates of convergence for the given metric.
In applied mathematics, topological data analysis (TDA) is an approach to the analysis of datasets using techniques from topology. Extraction of information from datasets that are high-dimensional, incomplete and noisy is generally challenging. TDA provides a general framework to analyze such data in a manner that is insensitive to the particular metric chosen and provides dimensionality reduction and robustness to noise. Beyond this, it inherits functoriality, a fundamental concept of modern mathematics, from its topological nature, which allows it to adapt to new mathematical tools.

In probability theory and statistics, the Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time if these events occur with a known constant mean rate and independently of the time since the last event. It can also be used for the number of events in other types of intervals than time, and in dimension greater than 1.

In statistics and in probability theory, distance correlation or distance covariance is a measure of dependence between two paired random vectors of arbitrary, not necessarily equal, dimension. The population distance correlation coefficient is zero if and only if the random vectors are independent. Thus, distance correlation measures both linear and nonlinear association between two random variables or random vectors. This is in contrast to Pearson's correlation, which can only detect linear association between two random variables.
A sum-of-squares optimization program is an optimization problem with a linear cost function and a particular type of constraint on the decision variables. These constraints are of the form that when the decision variables are used as coefficients in certain polynomials, those polynomials should have the polynomial SOS property. When fixing the maximum degree of the polynomials involved, sum-of-squares optimization is also known as the Lasserre hierarchy of relaxations in semidefinite programming.
The distributional learning theory or learning of probability distribution is a framework in computational learning theory. It has been proposed from Michael Kearns, Yishay Mansour, Dana Ron, Ronitt Rubinfeld, Robert Schapire and Linda Sellie in 1994 and it was inspired from the PAC-framework introduced by Leslie Valiant.
In functional analysis and related areas of mathematics, a metrizable topological vector space (TVS) is a TVS whose topology is induced by a metric. An LM-space is an inductive limit of a sequence of locally convex metrizable TVS.
A Stein discrepancy is a statistical divergence between two probability measures that is rooted in Stein's method. It was first formulated as a tool to assess the quality of Markov chain Monte Carlo samplers, but has since been used in diverse settings in statistics, machine learning and computer science.

































