In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.
A splay tree is a binary search tree with the additional property that recently accessed elements are quick to access again. Like self-balancing binary search trees, a splay tree performs basic operations such as insertion, look-up and removal in O(log n) amortized time. For random access patterns drawn from a non-uniform random distribution, their amortized time can be faster than logarithmic, proportional to the entropy of the access pattern. For many patterns of non-random operations, also, splay trees can take better than logarithmic time, without requiring advance knowledge of the pattern. According to the unproven dynamic optimality conjecture, their performance on all access patterns is within a constant factor of the best possible performance that could be achieved by any other self-adjusting binary search tree, even one selected to fit that pattern. The splay tree was invented by Daniel Sleator and Robert Tarjan in 1985.

In computer science, the treap and the randomized binary search tree are two closely related forms of binary search tree data structures that maintain a dynamic set of ordered keys and allow binary searches among the keys. After any sequence of insertions and deletions of keys, the shape of the tree is a random variable with the same probability distribution as a random binary tree; in particular, with high probability its height is proportional to the logarithm of the number of keys, so that each search, insertion, or deletion operation takes logarithmic time to perform.
In computing, a persistent data structure or not ephemeral data structure is a data structure that always preserves the previous version of itself when it is modified. Such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead always yield a new updated structure. The term was introduced in Driscoll, Sarnak, Sleator, and Tarjans' 1986 article.
In computer science, a fusion tree is a type of tree data structure that implements an associative array on w-bit integers on a finite universe, where each of the input integers has size less than 2w and is non-negative. When operating on a collection of n key–value pairs, it uses O(n) space and performs searches in O(logwn) time, which is asymptotically faster than a traditional self-balancing binary search tree, and also better than the van Emde Boas tree for large values of w. It achieves this speed by using certain constant-time operations that can be done on a machine word. Fusion trees were invented in 1990 by Michael Fredman and Dan Willard.
A B+ tree is an m-ary tree with a variable but often large number of children per node. A B+ tree consists of a root, internal nodes and leaves. The root may be either a leaf or a node with two or more children.

In computer science, a k-d tree is a space-partitioning data structure for organizing points in a k-dimensional space. K-dimensional is that which concerns exactly k orthogonal axes or a space of any number of dimensions. k-d trees are a useful data structure for several applications, such as:
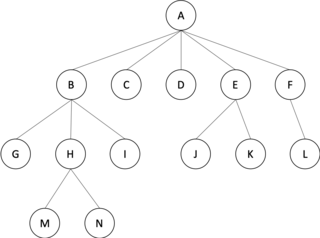
In graph theory, an m-ary tree is an arborescence in which each node has no more than m children. A binary tree is the special case where m = 2, and a ternary tree is another case with m = 3 that limits its children to three.
In graph theory and computer science, the lowest common ancestor (LCA) of two nodes v and w in a tree or directed acyclic graph (DAG) T is the lowest node that has both v and w as descendants, where we define each node to be a descendant of itself.
In computer science, fractional cascading is a technique to speed up a sequence of binary searches for the same value in a sequence of related data structures. The first binary search in the sequence takes a logarithmic amount of time, as is standard for binary searches, but successive searches in the sequence are faster. The original version of fractional cascading, introduced in two papers by Chazelle and Guibas in 1986, combined the idea of cascading, originating in range searching data structures of Lueker (1978) and Willard (1978), with the idea of fractional sampling, which originated in Chazelle (1983). Later authors introduced more complex forms of fractional cascading that allow the data structure to be maintained as the data changes by a sequence of discrete insertion and deletion events.

In computer science, a segment tree, also known as a statistic tree, is a tree data structure used for storing information about intervals, or segments. It allows querying which of the stored segments contain a given point. It is, in principle, a static structure and cannot be modified once built. A similar data structure is the interval tree.
In computer science, a range tree is an ordered tree data structure to hold a list of points. It allows all points within a given range to be reported efficiently, and is typically used in two or higher dimensions. Range trees were introduced by Jon Louis Bentley in 1979. Similar data structures were discovered independently by Lueker, Lee and Wong, and Willard. The range tree is an alternative to the k-d tree. Compared to k-d trees, range trees offer faster query times of but worse storage of , where n is the number of points stored in the tree, d is the dimension of each point and k is the number of points reported by a given query.

In computer science, a Cartesian tree is a binary tree derived from a sequence of distinct numbers. To construct the Cartesian tree, set its root to be the minimum number in the sequence, and recursively construct its left and right subtrees from the subsequences before and after this number. It is uniquely defined as a min-heap whose symmetric (in-order) traversal returns the original sequence.
In computer science, the Bx tree is a query that is used to update efficient B+ tree-based index structures for moving objects.

A Fenwick tree or binary indexed tree(BIT) is a data structure that can efficiently update values and calculate prefix sums in an array of values.
In data structures, a range query consists of pre-processing some input data into a data structure to efficiently answer any number of queries on any subset of the input. Particularly, there is a group of problems that have been extensively studied where the input is an array of unsorted numbers and a query consists of computing some function, such as the minimum, on a specific range of the array.
In computer science, the longest common prefix array is an auxiliary data structure to the suffix array. It stores the lengths of the longest common prefixes (LCPs) between all pairs of consecutive suffixes in a sorted suffix array.
In computer science, a fractal tree index is a tree data structure that keeps data sorted and allows searches and sequential access in the same time as a B-tree but with insertions and deletions that are asymptotically faster than a B-tree. Like a B-tree, a fractal tree index is a generalization of a binary search tree in that a node can have more than two children. Furthermore, unlike a B-tree, a fractal tree index has buffers at each node, which allow insertions, deletions and other changes to be stored in intermediate locations. The goal of the buffers is to schedule disk writes so that each write performs a large amount of useful work, thereby avoiding the worst-case performance of B-trees, in which each disk write may change a small amount of data on disk. Like a B-tree, fractal tree indexes are optimized for systems that read and write large blocks of data. The fractal tree index has been commercialized in databases by Tokutek. Originally, it was implemented as a cache-oblivious lookahead array, but the current implementation is an extension of the Bε tree. The Bε is related to the Buffered Repository Tree. The Buffered Repository Tree has degree 2, whereas the Bε tree has degree Bε. The fractal tree index has also been used in a prototype filesystem. An open source implementation of the fractal tree index is available, which demonstrates the implementation details outlined below.
In computer science, the augmented map is an abstract data type (ADT) based on ordered maps, which associates each ordered map an augmented value. For an ordered map with key type , comparison function on and value type , the augmented value is defined based on two functions: a base function and a combine function , where is the type of the augmented value. The base function converts a single entry in to an augmented value, and the combine function combines multiple augmented values. The combine function is required to be associative and have an identity . We extend the definition of the associative function as follows:
The PH-tree is a tree data structure used for spatial indexing of multi-dimensional data (keys) such as geographical coordinates, points, feature vectors, rectangles or bounding boxes. The PH-tree is space partitioning index with a structure similar to that of a quadtree or octree. However, unlike quadtrees, it uses a splitting policy based on tries and similar to Crit bit trees that is based on the bit-representation of the keys. The bit-based splitting policy, when combined with the use of different internal representations for nodes, provides scalability with high-dimensional data. The bit-representation splitting policy also imposes a maximum depth, thus avoiding degenerated trees and the need for rebalancing.