Analysis of variance (ANOVA) is a collection of statistical models and their associated estimation procedures used to analyze the differences among means. ANOVA was developed by the statistician Ronald Fisher. ANOVA is based on the law of total variance, where the observed variance in a particular variable is partitioned into components attributable to different sources of variation. In its simplest form, ANOVA provides a statistical test of whether two or more population means are equal, and therefore generalizes the t-test beyond two means. In other words, the ANOVA is used to test the difference between two or more means.
Psychological statistics is application of formulas, theorems, numbers and laws to psychology. Statistical methods for psychology include development and application statistical theory and methods for modeling psychological data. These methods include psychometrics, factor analysis, experimental designs, and Bayesian statistics. The article also discusses journals in the same field.
Psychometrics is a field of study within psychology concerned with the theory and technique of measurement. Psychometrics generally covers specialized fields within psychology and education devoted to testing, measurement, assessment, and related activities. Psychometrics is concerned with the objective measurement of latent constructs that cannot be directly observed. Examples of latent constructs include intelligence, introversion, mental disorders, and educational achievement. The levels of individuals on nonobservable latent variables are inferred through mathematical modeling based on what is observed from individuals' responses to items on tests and scales.
Factor analysis is a statistical method used to describe variability among observed, correlated variables in terms of a potentially lower number of unobserved variables called factors. For example, it is possible that variations in six observed variables mainly reflect the variations in two unobserved (underlying) variables. Factor analysis searches for such joint variations in response to unobserved latent variables. The observed variables are modelled as linear combinations of the potential factors plus "error" terms, hence factor analysis can be thought of as a special case of errors-in-variables models.

An F-test is any statistical test used to compare the variances of two samples or the ratio of variances between multiple samples. The test statistic, random variable F, is used to determine if the tested data has an F-distribution under the true null hypothesis, and true customary assumptions about the error term (ε). It is most often used when comparing statistical models that have been fitted to a data set, in order to identify the model that best fits the population from which the data were sampled. Exact "F-tests" mainly arise when the models have been fitted to the data using least squares. The name was coined by George W. Snedecor, in honour of Ronald Fisher. Fisher initially developed the statistic as the variance ratio in the 1920s.
Analysis of covariance (ANCOVA) is a general linear model that blends ANOVA and regression. ANCOVA evaluates whether the means of a dependent variable (DV) are equal across levels of one or more categorical independent variables (IV) and across one or more continuous variables. For example, the categorical variable(s) might describe treatment and the continuous variable(s) might be covariates or nuisance variables; or vice versa. Mathematically, ANCOVA decomposes the variance in the DV into variance explained by the CV(s), variance explained by the categorical IV, and residual variance. Intuitively, ANCOVA can be thought of as 'adjusting' the DV by the group means of the CV(s).
In statistics, path analysis is used to describe the directed dependencies among a set of variables. This includes models equivalent to any form of multiple regression analysis, factor analysis, canonical correlation analysis, discriminant analysis, as well as more general families of models in the multivariate analysis of variance and covariance analyses.

In statistics, the coefficient of determination, denoted R2 or r2 and pronounced "R squared", is the proportion of the variation in the dependent variable that is predictable from the independent variable(s).
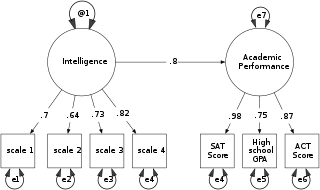
Structural equation modeling (SEM) is a diverse set of methods used by scientists doing both observational and experimental research. SEM is used mostly in the social and behavioral sciences but it is also used in epidemiology, business, and other fields. A definition of SEM is difficult without reference to technical language, but a good starting place is the name itself.
In statistics, the number of degrees of freedom is the number of values in the final calculation of a statistic that are free to vary.
In statistics, homogeneity and its opposite, heterogeneity, arise in describing the properties of a dataset, or several datasets. They relate to the validity of the often convenient assumption that the statistical properties of any one part of an overall dataset are the same as any other part. In meta-analysis, which combines the data from several studies, homogeneity measures the differences or similarities between the several studies.
In psychology, discriminant validity tests whether concepts or measurements that are not supposed to be related are actually unrelated.
In statistics, confirmatory factor analysis (CFA) is a special form of factor analysis, most commonly used in social science research. It is used to test whether measures of a construct are consistent with a researcher's understanding of the nature of that construct. As such, the objective of confirmatory factor analysis is to test whether the data fit a hypothesized measurement model. This hypothesized model is based on theory and/or previous analytic research. CFA was first developed by Jöreskog (1969) and has built upon and replaced older methods of analyzing construct validity such as the MTMM Matrix as described in Campbell & Fiske (1959).
The multitrait-multimethod (MTMM) matrix is an approach to examining construct validity developed by Campbell and Fiske (1959). It organizes convergent and discriminant validity evidence for comparison of how a measure relates to other measures. The conceptual approach has influenced experimental design and measurement theory in psychology, including applications in structural equation models.
Psychometric software is software that is used for psychometric analysis of data from tests, questionnaires, or inventories reflecting latent psychoeducational variables. While some psychometric analyses can be performed with standard statistical software like SPSS, most analyses require specialized tools.
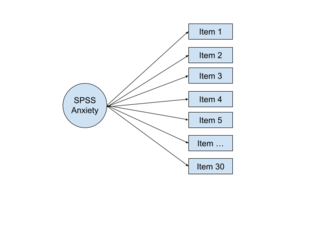
In multivariate statistics, exploratory factor analysis (EFA) is a statistical method used to uncover the underlying structure of a relatively large set of variables. EFA is a technique within factor analysis whose overarching goal is to identify the underlying relationships between measured variables. It is commonly used by researchers when developing a scale and serves to identify a set of latent constructs underlying a battery of measured variables. It should be used when the researcher has no a priori hypothesis about factors or patterns of measured variables. Measured variables are any one of several attributes of people that may be observed and measured. Examples of measured variables could be the physical height, weight, and pulse rate of a human being. Usually, researchers would have a large number of measured variables, which are assumed to be related to a smaller number of "unobserved" factors. Researchers must carefully consider the number of measured variables to include in the analysis. EFA procedures are more accurate when each factor is represented by multiple measured variables in the analysis.

SmartPLS is a software with graphical user interface for variance-based structural equation modeling (SEM) using the partial least squares (PLS) path modeling method. Users can estimate models with their data by using basic PLS-SEM, weighted PLS-SEM (WPLS), consistent PLS-SEM (PLSc-SEM), and sumscores regression algorithms. The software computes standard results assessment criteria and it supports additional statistical analyses . Since SmartPLS is programmed in Java, it can be executed and run on different computer operating systems such as Windows and Mac.
In statistics, confirmatory composite analysis (CCA) is a sub-type of structural equation modeling (SEM). Although, historically, CCA emerged from a re-orientation and re-start of partial least squares path modeling (PLS-PM), it has become an independent approach and the two should not be confused. In many ways it is similar to, but also quite distinct from confirmatory factor analysis (CFA). It shares with CFA the process of model specification, model identification, model estimation, and model assessment. However, in contrast to CFA which always assumes the existence of latent variables, in CCA all variables can be observable, with their interrelationships expressed in terms of composites, i.e., linear compounds of subsets of the variables. The composites are treated as the fundamental objects and path diagrams can be used to illustrate their relationships. This makes CCA particularly useful for disciplines examining theoretical concepts that are designed to attain certain goals, so-called artifacts, and their interplay with theoretical concepts of behavioral sciences.

In statistics, a sequence of random variables is homoscedastic if all its random variables have the same finite variance; this is also known as homogeneity of variance. The complementary notion is called heteroscedasticity, also known as heterogeneity of variance. The spellings homoskedasticity and heteroskedasticity are also frequently used. Assuming a variable is homoscedastic when in reality it is heteroscedastic results in unbiased but inefficient point estimates and in biased estimates of standard errors, and may result in overestimating the goodness of fit as measured by the Pearson coefficient.
Barbara M. Byrne was a Canadian quantitative psychologist known for her work in psychometrics, specifically regarding construct validity, structural equation modeling (SEM), and statistics. She held the position of Professor Emerita in the School of Psychology at the University of Ottawa and was a fellow of the International Testing Committee (ITC), International Association for Applied Psychology (IAAP), and American Psychological Association (APA) throughout her research career.



