
Principal component analysis (PCA) is a linear dimensionality reduction technique with applications in exploratory data analysis, visualization and data preprocessing.
In linear algebra, an orthogonal matrix, or orthonormal matrix, is a real square matrix whose columns and rows are orthonormal vectors.

Nonlinear dimensionality reduction, also known as manifold learning, refers to various related techniques that aim to project high-dimensional data onto lower-dimensional latent manifolds, with the goal of either visualizing the data in the low-dimensional space, or learning the mapping itself. The techniques described below can be understood as generalizations of linear decomposition methods used for dimensionality reduction, such as singular value decomposition and principal component analysis.

In linear algebra and functional analysis, a projection is a linear transformation from a vector space to itself such that . That is, whenever is applied twice to any vector, it gives the same result as if it were applied once. It leaves its image unchanged. This definition of "projection" formalizes and generalizes the idea of graphical projection. One can also consider the effect of a projection on a geometrical object by examining the effect of the projection on points in the object.
Dimensionality reduction, or dimension reduction, is the transformation of data from a high-dimensional space into a low-dimensional space so that the low-dimensional representation retains some meaningful properties of the original data, ideally close to its intrinsic dimension. Working in high-dimensional spaces can be undesirable for many reasons; raw data are often sparse as a consequence of the curse of dimensionality, and analyzing the data is usually computationally intractable. Dimensionality reduction is common in fields that deal with large numbers of observations and/or large numbers of variables, such as signal processing, speech recognition, neuroinformatics, and bioinformatics.
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text. A matrix containing word counts per document is constructed from a large piece of text and a mathematical technique called singular value decomposition (SVD) is used to reduce the number of rows while preserving the similarity structure among columns. Documents are then compared by cosine similarity between any two columns. Values close to 1 represent very similar documents while values close to 0 represent very dissimilar documents.
The curse of dimensionality refers to various phenomena that arise when analyzing and organizing data in high-dimensional spaces that do not occur in low-dimensional settings such as the three-dimensional physical space of everyday experience. The expression was coined by Richard E. Bellman when considering problems in dynamic programming. The curse generally refers to issues that arise when the number of datapoints is small relative to the intrinsic dimension of the data.
In statistics, the k-nearest neighbors algorithm (k-NN) is a non-parametric supervised learning method first developed by Evelyn Fix and Joseph Hodges in 1951, and later expanded by Thomas Cover. It is used for classification and regression. In both cases, the input consists of the k closest training examples in a data set. The output depends on whether k-NN is used for classification or regression:
Biclustering, block clustering, Co-clustering or two-mode clustering is a data mining technique which allows simultaneous clustering of the rows and columns of a matrix. The term was first introduced by Boris Mirkin to name a technique introduced many years earlier, in 1972, by John A. Hartigan.
Non-negative matrix factorization, also non-negative matrix approximation is a group of algorithms in multivariate analysis and linear algebra where a matrix V is factorized into (usually) two matrices W and H, with the property that all three matrices have no negative elements. This non-negativity makes the resulting matrices easier to inspect. Also, in applications such as processing of audio spectrograms or muscular activity, non-negativity is inherent to the data being considered. Since the problem is not exactly solvable in general, it is commonly approximated numerically.
An autoencoder is a type of artificial neural network used to learn efficient codings of unlabeled data. An autoencoder learns two functions: an encoding function that transforms the input data, and a decoding function that recreates the input data from the encoded representation. The autoencoder learns an efficient representation (encoding) for a set of data, typically for dimensionality reduction.
In computer science, locality-sensitive hashing (LSH) is a fuzzy hashing technique that hashes similar input items into the same "buckets" with high probability. Since similar items end up in the same buckets, this technique can be used for data clustering and nearest neighbor search. It differs from conventional hashing techniques in that hash collisions are maximized, not minimized. Alternatively, the technique can be seen as a way to reduce the dimensionality of high-dimensional data; high-dimensional input items can be reduced to low-dimensional versions while preserving relative distances between items.
In multivariate statistics, spectral clustering techniques make use of the spectrum (eigenvalues) of the similarity matrix of the data to perform dimensionality reduction before clustering in fewer dimensions. The similarity matrix is provided as an input and consists of a quantitative assessment of the relative similarity of each pair of points in the dataset.
In mathematics, the Johnson–Lindenstrauss lemma is a result named after William B. Johnson and Joram Lindenstrauss concerning low-distortion embeddings of points from high-dimensional into low-dimensional Euclidean space. The lemma states that a set of points in a high-dimensional space can be embedded into a space of much lower dimension in such a way that distances between the points are nearly preserved. In the classical proof of the lemma, the embedding is a random orthogonal projection.
In computer science, lattice problems are a class of optimization problems related to mathematical objects called lattices. The conjectured intractability of such problems is central to the construction of secure lattice-based cryptosystems: lattice problems are an example of NP-hard problems which have been shown to be average-case hard, providing a test case for the security of cryptographic algorithms. In addition, some lattice problems which are worst-case hard can be used as a basis for extremely secure cryptographic schemes. The use of worst-case hardness in such schemes makes them among the very few schemes that are very likely secure even against quantum computers. For applications in such cryptosystems, lattices over vector space or free modules are generally considered.
Sparse distributed memory (SDM) is a mathematical model of human long-term memory introduced by Pentti Kanerva in 1988 while he was at NASA Ames Research Center.
In data mining and machine learning, kq-flats algorithm is an iterative method which aims to partition m observations into k clusters where each cluster is close to a q-flat, where q is a given integer.
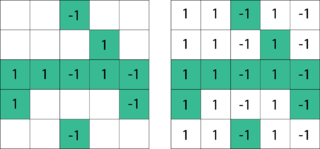
Matrix completion is the task of filling in the missing entries of a partially observed matrix, which is equivalent to performing data imputation in statistics. A wide range of datasets are naturally organized in matrix form. One example is the movie-ratings matrix, as appears in the Netflix problem: Given a ratings matrix in which each entry represents the rating of movie by customer , if customer has watched movie and is otherwise missing, we would like to predict the remaining entries in order to make good recommendations to customers on what to watch next. Another example is the document-term matrix: The frequencies of words used in a collection of documents can be represented as a matrix, where each entry corresponds to the number of times the associated term appears in the indicated document.
Sparse dictionary learning is a representation learning method which aims at finding a sparse representation of the input data in the form of a linear combination of basic elements as well as those basic elements themselves. These elements are called atoms and they compose a dictionary. Atoms in the dictionary are not required to be orthogonal, and they may be an over-complete spanning set. This problem setup also allows the dimensionality of the signals being represented to be higher than the one of the signals being observed. The above two properties lead to having seemingly redundant atoms that allow multiple representations of the same signal but also provide an improvement in sparsity and flexibility of the representation.
In statistics, machine learning and algorithms, a tensor sketch is a type of dimensionality reduction that is particularly efficient when applied to vectors that have tensor structure. Such a sketch can be used to speed up explicit kernel methods, bilinear pooling in neural networks and is a cornerstone in many numerical linear algebra algorithms.








