
A random variable is a mathematical formalization of a quantity or object which depends on random events. The term 'random variable' can be misleading as its mathematical definition is not actually random nor a variable, but rather it is a function from possible outcomes in a sample space to a measurable space, often to the real numbers.
Independence is a fundamental notion in probability theory, as in statistics and the theory of stochastic processes. Two events are independent, statistically independent, or stochastically independent if, informally speaking, the occurrence of one does not affect the probability of occurrence of the other or, equivalently, does not affect the odds. Similarly, two random variables are independent if the realization of one does not affect the probability distribution of the other.
The proposition in probability theory known as the law of total expectation, the law of iterated expectations (LIE), Adam's law, the tower rule, and the smoothing theorem, among other names, states that if is a random variable whose expected value is defined, and is any random variable on the same probability space, then
In probability theory, the conditional expectation, conditional expected value, or conditional mean of a random variable is its expected value – the value it would take "on average" over an arbitrarily large number of occurrences – given that a certain set of "conditions" is known to occur. If the random variable can take on only a finite number of values, the "conditions" are that the variable can only take on a subset of those values. More formally, in the case when the random variable is defined over a discrete probability space, the "conditions" are a partition of this probability space.
In probability theory and statistics, given two jointly distributed random variables and , the conditional probability distribution of given is the probability distribution of when is known to be a particular value; in some cases the conditional probabilities may be expressed as functions containing the unspecified value of as a parameter. When both and are categorical variables, a conditional probability table is typically used to represent the conditional probability. The conditional distribution contrasts with the marginal distribution of a random variable, which is its distribution without reference to the value of the other variable.
In mathematics, the total variation identifies several slightly different concepts, related to the (local or global) structure of the codomain of a function or a measure. For a real-valued continuous function f, defined on an interval [a, b] ⊂ R, its total variation on the interval of definition is a measure of the one-dimensional arclength of the curve with parametric equation x ↦ f(x), for x ∈ [a, b]. Functions whose total variation is finite are called functions of bounded variation.
Probability theory and statistics have some commonly used conventions, in addition to standard mathematical notation and mathematical symbols.
A Dynkin system, named after Eugene Dynkin, is a collection of subsets of another universal set satisfying a set of axioms weaker than those of 𝜎-algebra. Dynkin systems are sometimes referred to as 𝜆-systems or d-system. These set families have applications in measure theory and probability.
In mathematics, the Gibbs measure, named after Josiah Willard Gibbs, is a probability measure frequently seen in many problems of probability theory and statistical mechanics. It is a generalization of the canonical ensemble to infinite systems. The canonical ensemble gives the probability of the system X being in state x as
In mathematics, a π-system on a set is a collection of certain subsets of such that
In probability theory, random element is a generalization of the concept of random variable to more complicated spaces than the simple real line. The concept was introduced by Maurice Fréchet (1948) who commented that the “development of probability theory and expansion of area of its applications have led to necessity to pass from schemes where (random) outcomes of experiments can be described by number or a finite set of numbers, to schemes where outcomes of experiments represent, for example, vectors, functions, processes, fields, series, transformations, and also sets or collections of sets.”
This article discusses how information theory is related to measure theory.
In mathematics, more specifically measure theory, there are various notions of the convergence of measures. For an intuitive general sense of what is meant by convergence of measures, consider a sequence of measures μn on a space, sharing a common collection of measurable sets. Such a sequence might represent an attempt to construct 'better and better' approximations to a desired measure μ that is difficult to obtain directly. The meaning of 'better and better' is subject to all the usual caveats for taking limits; for any error tolerance ε > 0 we require there be N sufficiently large for n ≥ N to ensure the 'difference' between μn and μ is smaller than ε. Various notions of convergence specify precisely what the word 'difference' should mean in that description; these notions are not equivalent to one another, and vary in strength.
In mathematics, the disintegration theorem is a result in measure theory and probability theory. It rigorously defines the idea of a non-trivial "restriction" of a measure to a measure zero subset of the measure space in question. It is related to the existence of conditional probability measures. In a sense, "disintegration" is the opposite process to the construction of a product measure.
In probability theory, a random measure is a measure-valued random element. Random measures are for example used in the theory of random processes, where they form many important point processes such as Poisson point processes and Cox processes.
In probability theory, a standard probability space, also called Lebesgue–Rokhlin probability space or just Lebesgue space is a probability space satisfying certain assumptions introduced by Vladimir Rokhlin in 1940. Informally, it is a probability space consisting of an interval and/or a finite or countable number of atoms.
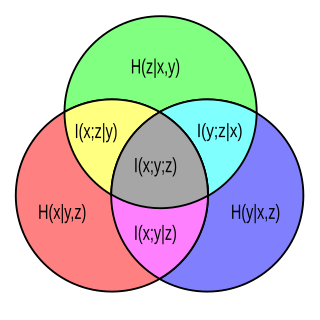
In probability theory, particularly information theory, the conditional mutual information is, in its most basic form, the expected value of the mutual information of two random variables given the value of a third.
In probability theory, a Markov kernel is a map that in the general theory of Markov processes plays the role that the transition matrix does in the theory of Markov processes with a finite state space.
In machine learning, the kernel embedding of distributions comprises a class of nonparametric methods in which a probability distribution is represented as an element of a reproducing kernel Hilbert space (RKHS). A generalization of the individual data-point feature mapping done in classical kernel methods, the embedding of distributions into infinite-dimensional feature spaces can preserve all of the statistical features of arbitrary distributions, while allowing one to compare and manipulate distributions using Hilbert space operations such as inner products, distances, projections, linear transformations, and spectral analysis. This learning framework is very general and can be applied to distributions over any space on which a sensible kernel function may be defined. For example, various kernels have been proposed for learning from data which are: vectors in , discrete classes/categories, strings, graphs/networks, images, time series, manifolds, dynamical systems, and other structured objects. The theory behind kernel embeddings of distributions has been primarily developed by Alex Smola, Le Song , Arthur Gretton, and Bernhard Schölkopf. A review of recent works on kernel embedding of distributions can be found in.
Poisson-type random measures are a family of three random counting measures which are closed under restriction to a subspace, i.e. closed under thinning. They are the only distributions in the canonical non-negative power series family of distributions to possess this property and include the Poisson distribution, negative binomial distribution, and binomial distribution. The PT family of distributions is also known as the Katz family of distributions, the Panjer or (a,b,0) class of distributions and may be retrieved through the Conway–Maxwell–Poisson distribution.















































