This article is about the rule of succession in probability theory. For monarchical and presidential rules of succession, see Order of succession.
"Laplace–Bayes estimator" redirects here. For statistical estimators that maximize posterior expected utility or minimize posterior expected loss, see Bayes estimator.
In probability theory, the rule of succession is a formula introduced in the 18th century by Pierre-Simon Laplace in the course of treating the sunrise problem.[1] The formula is still used, particularly to estimate underlying probabilities when there are few observations or events that have not been observed to occur at all in (finite) sample data.
If we repeat an experiment that we know can result in a success or failure, n times independently, and get s successes, and n − s failures, then what is the probability that the next repetition will succeed?
Since we have the prior knowledge that we are looking at an experiment for which both success and failure are possible, our estimate is as if we had observed one success and one failure for sure before we even started the experiments. In a sense we made n+2 observations (known as pseudocounts) with s + 1 successes. Although this may seem the simplest and most reasonable assumption, which also happens to be true, it still requires a proof. Indeed, assuming a pseudocount of one per possibility is one way to generalise the binary result, but has unexpected consequences — see Generalization to any number of possibilities, below.
Nevertheless, if we had not known from the start that both success and failure are possible, then we would have had to assign
But see Mathematical details, below, for an analysis of its validity. In particular it is not valid when , or .
If the number of observations increases, and get more and more similar, which is intuitively clear: the more data we have, the less importance should be assigned to our prior information.
Historical application to the sunrise problem
Laplace used the rule of succession to calculate the probability that the Sun will rise tomorrow, given that it has risen every day for the past 5000 years. One obtains a very large factor of approximately 5000 × 365.25, which gives odds of about 1,826,200 to 1 in favour of the Sun rising tomorrow.
However, as the mathematical details below show, the basic assumption for using the rule of succession would be that we have no prior knowledge about the question whether the Sun will or will not rise tomorrow, except that it can do either. This is not the case for sunrises.
Laplace knew this well, and he wrote to conclude the sunrise example: "But this number is far greater for him who, seeing in the totality of phenomena the principle regulating the days and seasons, realizes that nothing at the present moment can arrest the course of it."[2] Yet Laplace was ridiculed for this calculation; his opponents[who?] gave no heed to that sentence, or failed to understand its importance.[2]
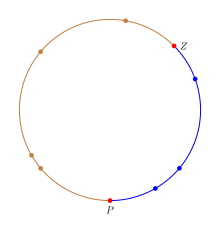
The point Z is the zero point, P is the point such that the fraction of the circle from Z to P (in blue) is equal to p. The value of p is precisely the number of blue arcs divided by the total number of arcs. If we let the first clockwise point of an arc define it, then every point on the circle defines one arc with Z defining a blue arc and P defining a non-blue arc. The estimate for p is then one (Z) more than blue points divided by two (Z and P) more than total number of trials which is the rule of succession.
The rule of succession can be interpreted in an intuitive manner by considering points randomly distributed on a circle rather than counting the number "success"/"failures" in an experiment.[5] To mimic the behavior of the proportion p on the circle, we will color the circle in two colors and the fraction of the circle colored in the "success" color will be equal to p. To express the uncertainty about the value of p, we need to select a fraction of the circle.
A fraction is chosen by selecting two uniformly random points on the circle. The first point Z corresponds to the zero in the [0, 1] interval and the second point P corresponds to p within [0, 1]. In terms of the circle the fraction of the circle from Z to P moving clockwise will be equal to p. The n trials can be interpreted as n points uniformly distributed on the circle; any point in the "success" fraction is a success and a failure otherwise. This provides an exact mapping from success/failure experiments with probability of success p to uniformly random points on the circle. In the figure the success fraction is colored blue to differentiate it from the rest of the circle and the points P and Z are highlighted in red.
Given this circle, the estimate of p is the fraction colored blue. Let us divide the circle into n+2 arcs corresponding to the n+2 points such that the portion from a point on the circle to the next point (moving clockwise) is one arc associated with the first point. Thus, Z defines the first blue arc while P defines the first non-blue/failure arc. Since the next point is a uniformly random point, if it falls in any of the blue arcs then the trial succeeds while if it falls in any of the other arcs, then it fails. So the probability of success p is where b is the number of blue arcs and t is the total number of arcs. Note that there is one more blue arc (that of Z) than success point and two more arcs (those of P and Z) than n points. Substituting the values with number of successes gives the rule of succession.
Note: The actual probability needs to use the length of blue arcs divided by the length of all arcs. However, when k points are uniformly randomly distributed on a circle, the distance from a point to the next point is 1/k. So on average each arc is of the same length and ratio of lengths becomes ratio of counts.
Mathematical details
The proportion p is assigned a uniform distribution to describe the uncertainty about its true value. (This proportion is not random, but uncertain. We assign a probability distribution to p to express our uncertainty, not to attribute randomness top. But this amounts, mathematically, to the same thing as treating p as if it were random).
Let Xi be 1 if we observe a "success" on the ith trial, otherwise 0, with probability p of success on each trial. Thus each X is 0 or 1; each X has a Bernoulli distribution. Suppose these Xs are conditionally independent given p.
We can use Bayes' theorem to find the conditional probability distribution of p given the data Xi, i = 1, ..., n. For the "prior" (i.e., marginal) probability measure of p we assigned a uniform distribution over the open interval (0,1)
For the likelihood of a given p under our observations, we use the likelihood function
where s=x1+...+xn is the number of "successes" and n is the number of trials (we are using capital X to denote a random variable and lower-case x as the data actually observed). Putting it all together, we can calculate the posterior:
Since p tells us the probability of success in any experiment, and each experiment is conditionally independent, the conditional probability for success in the next experiment is just p. As p is being treated as if it is a random variable, the law of total probability tells us that the expected probability of success in the next experiment is just the expected value of p. Since p is conditional on the observed data Xi for i = 1, ..., n, we have
The same calculation can be performed with the (improper) prior that expresses total ignorance of p, including ignorance with regard to the question whether the experiment can succeed, or can fail. This improper prior is 1/(p(1−p)) for 0≤p≤1 and 0 otherwise.[6] If the calculation above is repeated with this prior, we get
Thus, with the prior specifying total ignorance, the probability of success is governed by the observed frequency of success. However, the posterior distribution that led to this result is the Beta(s,n−s) distribution, which is not proper when s=n or s=0 (i.e. the normalisation constant is infinite when s=0 or s=n). This means that we cannot use this form of the posterior distribution to calculate the probability of the next observation succeeding when s=0 or s=n. This puts the information contained in the rule of succession in greater light: it can be thought of as expressing the prior assumption that if sampling was continued indefinitely, we would eventually observe at least one success, and at least one failure in the sample. The prior expressing total ignorance does not assume this knowledge.
To evaluate the "complete ignorance" case when s=0 or s=n can be dealt with, we first go back to the hypergeometric distribution, denoted by . This is the approach taken in Jaynes (2003). The binomial Failed to parse (SVG (MathML can be enabled via browser plugin): Invalid response ("Math extension cannot connect to Restbase.") from server "http://localhost:6011/en.wikipedia.org/v1/":): {\mathrm {Bin}}(r|n,p) can be derived as a limiting form, where in such a way that their ratio remains fixed. One can think of as the number of successes in the total population, of size .
The equivalent prior to is , with a domain of . Working conditional to means that estimating is equivalent to estimating , and then dividing this estimate by . The posterior for can be given as:
And it can be seen that, if s=n or s=0, then one of the factorials in the numerator cancels exactly with one in the denominator. Taking the s=0 case, we have:
Adding in the normalising constant, which is always finite (because there are no singularities in the range of the posterior, and there are a finite number of terms) gives:
So the posterior expectation for is:
An approximate analytical expression for large N is given by first making the approximation to the product term:
and then replacing the summation in the numerator with an integral
The same procedure is followed for the denominator, but the process is a bit more tricky, as the integral is harder to evaluate
where ln is the natural logarithm plugging in these approximations into the expectation gives
where the base 10 logarithm has been used in the final answer for ease of calculation. For instance if the population is of size 10k then probability of success on the next sample is given by:
So for example, if the population be on the order of tens of billions, so that k=10, and we observe n=10 results without success, then the expected proportion in the population is approximately 0.43%. If the population is smaller, so that n=10, k=5 (tens of thousands), the expected proportion rises to approximately 0.86%, and so on. Similarly, if the number of observations is smaller, so that n=5, k=10, the proportion rise to approximately 0.86% again.
This probability has no positive lower bound, and can be made arbitrarily small for larger and larger choices of N, or k. This means that the probability depends on the size of the population from which one is sampling. In passing to the limit of infinite N (for the simpler analytic properties) we are "throwing away" a piece of very important information. Note that this ignorance relationship only holds as long as only no successes are observed. It is correspondingly revised back to the observed frequency rule as soon as one success is observed. The corresponding results are found for the s=n case by switching labels, and then subtracting the probability from1.
Generalization to any number of possibilities
This section gives a heuristic derivation similar to that in Probability Theory: The Logic of Science.[7]
The rule of succession has many different intuitive interpretations, and depending on which intuition one uses, the generalisation may be different. Thus, the way to proceed from here is very carefully, and to re-derive the results from first principles, rather than to introduce an intuitively sensible generalisation. The full derivation can be found in Jaynes' book, but it does admit an easier to understand alternative derivation, once the solution is known. Another point to emphasise is that the prior state of knowledge described by the rule of succession is given as an enumeration of the possibilities, with the additional information that it is possible to observe each category. This can be equivalently stated as observing each category once prior to gathering the data. To denote that this is the knowledge used, an Im is put as part of the conditions in the probability assignments.
The rule of succession comes from setting a binomial likelihood, and a uniform prior distribution. Thus a straightforward generalisation is just the multivariate extensions of these two distributions: 1) Setting a uniform prior over the initial m categories, and 2) using the multinomial distribution as the likelihood function (which is the multivariate generalisation of the binomial distribution). It can be shown that the uniform distribution is a special case of the Dirichlet distribution with all of its parameters equal to 1 (just as the uniform is Beta(1,1) in the binary case). The Dirichlet distribution is the conjugate prior for the multinomial distribution, which means that the posterior distribution is also a Dirichlet distribution with different parameters. Let pi denote the probability that category i will be observed, and let ni denote the number of times category i (i=1,...,m) actually was observed. Then the joint posterior distribution of the probabilities p1,...,pm is given by:
To get the generalised rule of succession, note that the probability of observing category i on the next observation, conditional on the pi is just pi, we simply require its expectation. Letting Ai denote the event that the next observation is in category i (i=1,...,m), and let n=n1+...+nm be the total number of observations made. The result, using the properties of the Dirichlet distribution is:
This solution reduces to the probability that would be assigned using the principle of indifference before any observations made (i.e. n=0), consistent with the original rule of succession. It also contains the rule of succession as a special case, when m=2, as a generalisation should.
Because the propositions or events Ai are mutually exclusive, it is possible to collapse the m categories into2. Simply add up the Ai probabilities that correspond to "success" to get the probability of success. Supposing that this aggregates c categories as "success" and m-c categories as "failure". Let s denote the sum of the relevant ni values that have been termed "success". The probability of "success" at the next trial is then:
which is different from the original rule of succession. But note that the original rule of succession is based on I2, whereas the generalisation is based on Im. This means that the information contained in Im is different from that contained in I2. This indicates that mere knowledge of more than two outcomes we know are possible is relevant information when collapsing these categories down to just two. This illustrates the subtlety in describing the prior information, and why it is important to specify which prior information one is using.
Further analysis
A good model is essential (i.e., a good compromise between accuracy and practicality). To paraphrase Laplace on the sunrise problem: Although we have a huge number of samples of the sun rising, there are far better models of the sun than assuming it has a certain probability of rising each day, e.g., simply having a half-life.
Given a good model, it is best to make as many observations as practicable, depending on the expected reliability of prior knowledge, cost of observations, time and resources available, and accuracy required.
One of the most difficult aspects of the rule of succession is not the mathematical formulas, but answering the question: When does the rule of succession apply? In the generalisation section, it was noted very explicitly by adding the prior information Im into the calculations. Thus, when all that is known about a phenomenon is that there are m known possible outcomes prior to observing any data, only then does the rule of succession apply. If the rule of succession is applied in problems where this does not accurately describe the prior state of knowledge, then it may give counter-intuitive results. This is not because the rule of succession is defective, but that it is effectively answering a different question, based on different prior information.
In principle (see Cromwell's rule), no possibility should have its probability (or its pseudocount) set to zero, since nothing in the physical world should be assumed strictly impossible (though it may be)—even if contrary to all observations and current theories. Indeed, Bayes rule takes absolutely no account of an observation previously believed to have zero probability—it is still declared impossible. However, only considering a fixed set of the possibilities is an acceptable route, one just needs to remember that the results are conditional on (or restricted to) the set being considered, and not some "universal" set. In fact Larry Bretthorst shows that including the possibility of "something else" into the hypothesis space makes no difference to the relative probabilities of the other hypothesis—it simply renormalises them to add up to a value less than 1.[8] Until "something else" is specified, the likelihood function conditional on this "something else" is indeterminate, for how is one to determine ? Thus no updating of the prior probability for "something else" can occur until it is more accurately defined.
However, it is sometimes debatable whether prior knowledge should affect the relative probabilities, or also the total weight of the prior knowledge compared to actual observations. This does not have a clear cut answer, for it depends on what prior knowledge one is considering. In fact, an alternative prior state of knowledge could be of the form "I have specified m potential categories, but I am sure that only one of them is possible prior to observing the data. However, I do not know which particular category this is." A mathematical way to describe this prior is the Dirichlet distribution with all parameters equal to m−1, which then gives a pseudocount of 1 to the denominator instead of m, and adds a pseudocount of m−1 to each category. This gives a slightly different probability in the binary case of .
Prior probabilities are only worth spending significant effort estimating when likely to have significant effect. They may be important when there are few observations — especially when so few that there have been few, if any, observations of some possibilities – such as a rare animal, in a given region. Also important when there are many observations, where it is believed that the expectation should be heavily weighted towards the prior estimates, in spite of many observations to the contrary, such as for a roulette wheel in a well-respected casino. In the latter case, at least some of the pseudocounts may need to be very large. They are not always small, and thereby soon outweighed by actual observations, as is often assumed. However, although a last resort, for everyday purposes, prior knowledge is usually vital. So most decisions must be subjective to some extent (dependent upon the analyst and analysis used).
In statistics and probability theory, the median is the value separating the higher half from the lower half of a data sample, a population, or a probability distribution. For a data set, it may be thought of as "the middle" value. The basic feature of the median in describing data compared to the mean is that it is not skewed by a small proportion of extremely large or small values, and therefore provides a better representation of the center. Median income, for example, may be a better way to describe center of the income distribution because increases in the largest incomes alone have no effect on median. For this reason, the median is of central importance in robust statistics.
In probability theory and statistics, Bayes' theorem, named after Thomas Bayes, describes the probability of an event, based on prior knowledge of conditions that might be related to the event. For example, if the risk of developing health problems is known to increase with age, Bayes' theorem allows the risk to an individual of a known age to be assessed more accurately by conditioning it relative to their age, rather than simply assuming that the individual is typical of the population as a whole.
Bayesian inference is a method of statistical inference in which Bayes' theorem is used to update the probability for a hypothesis as more evidence or information becomes available. Bayesian inference is an important technique in statistics, and especially in mathematical statistics. Bayesian updating is particularly important in the dynamic analysis of a sequence of data. Bayesian inference has found application in a wide range of activities, including science, engineering, philosophy, medicine, sport, and law. In the philosophy of decision theory, Bayesian inference is closely related to subjective probability, often called "Bayesian probability".
The method of least squares is a standard approach in regression analysis to approximate the solution of overdetermined systems by minimizing the sum of the squares of the residuals made in the results of each individual equation.
In statistics, naive Bayes classifiers are a family of simple "probabilistic classifiers" based on applying Bayes' theorem with strong (naive) independence assumptions between the features. They are among the simplest Bayesian network models, but coupled with kernel density estimation, they can achieve high accuracy levels.
A hidden Markov model (HMM) is a statistical Markov model in which the system being modeled is assumed to be a Markov process — call it — with unobservable ("hidden") states. As part of the definition, HMM requires that there be an observable process whose outcomes are "influenced" by the outcomes of in a known way. Since cannot be observed directly, the goal is to learn about by observing HMM has an additional requirement that the outcome of at time must be "influenced" exclusively by the outcome of at and that the outcomes of and at must be conditionally independent of at given at time
In statistics, a statistic is sufficient with respect to a statistical model and its associated unknown parameter if "no other statistic that can be calculated from the same sample provides any additional information as to the value of the parameter". In particular, a statistic is sufficient for a family of probability distributions if the sample from which it is calculated gives no additional information than the statistic, as to which of those probability distributions is the sampling distribution.
A Bayesian network is a probabilistic graphical model that represents a set of variables and their conditional dependencies via a directed acyclic graph (DAG). Bayesian networks are ideal for taking an event that occurred and predicting the likelihood that any one of several possible known causes was the contributing factor. For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases.
Pearson's chi-squared test is a statistical test applied to sets of categorical data to evaluate how likely it is that any observed difference between the sets arose by chance. It is the most widely used of many chi-squared tests – statistical procedures whose results are evaluated by reference to the chi-squared distribution. Its properties were first investigated by Karl Pearson in 1900. In contexts where it is important to improve a distinction between the test statistic and its distribution, names similar to Pearson χ-squared test or statistic are used.
The posterior probability is a type of conditional probability that results from updating the prior probability with information summarized by the likelihood via an application of Bayes' rule. From an epistemological perspective, the posterior probability contains everything there is to know about an uncertain proposition, given prior knowledge and a mathematical model describing the observations available at a particular time. After the arrival of new information, the current posterior probability may serve as the prior in another round of Bayesian updating.
In statistics, Gibbs sampling or a Gibbs sampler is a Markov chain Monte Carlo (MCMC) algorithm for obtaining a sequence of observations which are approximated from a specified multivariate probability distribution, when direct sampling is difficult. This sequence can be used to approximate the joint distribution ; to approximate the marginal distribution of one of the variables, or some subset of the variables ; or to compute an integral. Typically, some of the variables correspond to observations whose values are known, and hence do not need to be sampled.
The sunrise problem can be expressed as follows: "What is the probability that the sun will rise tomorrow?" The sunrise problem illustrates the difficulty of using probability theory when evaluating the plausibility of statements or beliefs.
In probability theory and statistics, the Laplace distribution is a continuous probability distribution named after Pierre-Simon Laplace. It is also sometimes called the double exponential distribution, because it can be thought of as two exponential distributions spliced together along the abscissa, although the term is also sometimes used to refer to the Gumbel distribution. The difference between two independent identically distributed exponential random variables is governed by a Laplace distribution, as is a Brownian motion evaluated at an exponentially distributed random time. Increments of Laplace motion or a variance gamma process evaluated over the time scale also have a Laplace distribution.
In probability and statistics, the Dirichlet distribution (after Peter Gustav Lejeune Dirichlet), often denoted , is a family of continuous multivariate probability distributions parameterized by a vector of positive reals. It is a multivariate generalization of the beta distribution, hence its alternative name of multivariate beta distribution (MBD). Dirichlet distributions are commonly used as prior distributions in Bayesian statistics, and in fact, the Dirichlet distribution is the conjugate prior of the categorical distribution and multinomial distribution.
In estimation theory and decision theory, a Bayes estimator or a Bayes action is an estimator or decision rule that minimizes the posterior expected value of a loss function. Equivalently, it maximizes the posterior expectation of a utility function. An alternative way of formulating an estimator within Bayesian statistics is maximum a posteriori estimation.
In probability theory and statistics, the Dirichlet-multinomial distribution is a family of discrete multivariate probability distributions on a finite support of non-negative integers. It is also called the Dirichlet compound multinomial distribution (DCM) or multivariate Pólya distribution. It is a compound probability distribution, where a probability vector p is drawn from a Dirichlet distribution with parameter vector , and an observation drawn from a multinomial distribution with probability vector p and number of trials n. The Dirichlet parameter vector captures the prior belief about the situation and can be seen as a pseudocount: observations of each outcome that occur before the actual data is collected. The compounding corresponds to a Pólya urn scheme. It is frequently encountered in Bayesian statistics, machine learning, empirical Bayes methods and classical statistics as an overdispersed multinomial distribution.
In probability theory and statistics, a categorical distribution is a discrete probability distribution that describes the possible results of a random variable that can take on one of K possible categories, with the probability of each category separately specified. There is no innate underlying ordering of these outcomes, but numerical labels are often attached for convenience in describing the distribution,. The K-dimensional categorical distribution is the most general distribution over a K-way event; any other discrete distribution over a size-K sample space is a special case. The parameters specifying the probabilities of each possible outcome are constrained only by the fact that each must be in the range 0 to 1, and all must sum to 1.
In statistics, additive smoothing, also called Laplace smoothing or Lidstone smoothing, is a technique used to smooth categorical data. Given a set of observation counts from a -dimensional multinomial distribution with trials, a "smoothed" version of the counts gives the estimator:
In probability theory and statistics, the negative multinomial distribution is a generalization of the negative binomial distribution (NB(x0, p)) to more than two outcomes.
In probability theory and statistics, the Poisson binomial distribution is the discrete probability distribution of a sum of independent Bernoulli trials that are not necessarily identically distributed. The concept is named after Siméon Denis Poisson.
References
↑ Laplace, Pierre-Simon (1814). Essai philosophique sur les probabilités. Paris: Courcier.
1 2 Part II Section 18.6 of Jaynes, E. T. & Bretthorst, G. L. (2003). Probability Theory: The Logic of Science. Cambridge University Press. ISBN978-0-521-59271-0
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.