Deletion-derived VP approach: [1]
Ivan Sag proposed two logical forms, one of which the coreferential pronoun is replaced by a bound variable. [1] This leads to the rule of semantic interpretation that takes pronouns and changes them into bound variables. [1] This rule is abbreviated as Pro→BV, where "Pro" stands for pronoun, and "BV" stands for bound variable.
Simple sentence example
9) [Betsyi loves heri dog]
The strict reading of sentence 9) is that "Betsy loves her own dog". Application of Pro→BV then derives the sentence in 9.i):
9.i) [Betsyi loves herj(or x's) dog]
Where herj is someone else or x's is anyone else's dog
Complex example
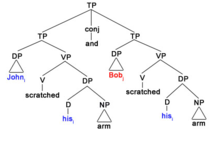
10) Betsyi loves heri dog and Sandyj does ∅ too
where ∅ = loves her dog
Strict reading
The strict reading of 10) is "Betsy loves Betsy's dog and Sandy loves Betsy's dog as well", which implies that ∅ is a VP that has been deleted. This is represented in the following sentence:
10.i) Betsyi λx (x loves heri dog) and Sandy λy (y loves heri dog)
The VPs that are being represented by λx and λy are syntactically identical. For this reason the one that is being c-commanded (λy) can be deleted.
This then forms:
10.ii) Betsyi loves heri dog and Sandyj does ∅ too
Sloppy reading
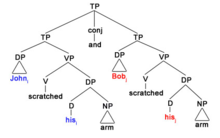
The sloppy reading of this sentence is "Betsy loves Betsy's dog and Sandy loves Sandy's dog". That is, both women love their own dog. This is represented in the following sentence:
10.iii) Betsyi λx (x loves heri dog) and Sandyj λy (y loves herj dog)
Since the embedded clauses are identical, the logic of this form is that the variable x must be bound to the same noun phrase in both cases. Therefore, "Betsy" is in the commanding position that determines the interpretation of the second clause.
The Pro → BV rule that converts pronouns into bound variables can be applied to all the pronouns.
This then allows for the sentence in 10.iii) to be:
10.iv) Betsyi λx (x loves x's dog) & Sandyj λy (y loves y's dog)
Another way the VP can be syntactically identical is, if λx(A) and λy(B) where every instance of x in A has a corresponding instance of y in B. So, like in the example above, for all instances of x there is a corresponding instance of y and therefore they are identical and the VP that is being c-commanded can be deleted.
Step-by-step derivation
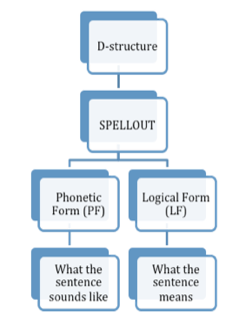
In Sag's approach, VP Ellipsis is analyzed as a deletion that takes place in between S-structure (Shallow Structure) and PF (Surface Structure). It is claimed that the deleted VP is recoverable at the level of LF due to alphabetic variance holding between two λ-expressions. [7] In this deletion approach, the sloppy identity is made possible, first, by the indexing of anaphors, and then by the application of a variable rewriting rule.
The following is a step by step derivation, taking into consideration both phonetic and logical forms, accounting for a sloppy reading of the sentence "John blamed himself, and Bill did too."
LF mapping
Deep structure to surface structure:
11) Johni [VP blamed himself], and Billj [VP blamed himself],too. [7]
In this sentence, the VP's [blamed himself] are present, but are not yet referencing any subject. In sentence 12), the Derived VP Rule is applied, rewriting these VP's using lambda notation.
Derived VP Rule
12) Johni [VPλx(x blame himself)], Billj [VPλy(y blame himself)], too. [7]
The Derived VP Rule has derived two VPs containing separate λ-operators with referential variables bound in each antecedent clause. The next rule, Indexing, co-indexes Anaphors and Pronouns to their subjects.
Indexing
13) Johni[VP λx(x blame himi)], Billj [VP λy( y blame himj)], too. [7]
As we see, the anaphors have been co-indexed to their respective NPs. Lastly, The Variable Rewriting Rule replaces pronouns and anaphors with variables in logical form.
Pro→BV
Logical form:
14) Johni[VP λx(x blame x)], Billj [VP λy (y blame y)], too. [7]
PF Mapping
Deep Structure to Surface Structure:
15) John [VP blamed himself], and Bill [VP blame himself], too. [7]
Here we see that both John and Bill precede the same VP, [blame himself]. It is important to note that any meaning, in this case what Subject the Anaphor "himself" references, is determined at LF, and thus left out of phonetic form.
VP-deletion
16) John [VP blamed himself], and Bill ____, too. [7]
VP Deletion occurs, which in effect deletes the VP [blame himself] from the second clause Bill [blame himself]. Again, it is important to keep in mind that this deletion occurs strictly at the phonetic level, and thus [blame himself] still exists in the LF component, despite it being deleted in PF.
Do-support
Phonetic form:
17) John [VP blamed himself], and Bill did____, too. [7]
Lastly, Do-Support is implemented, filling the empty space created by VP Deletion with did. This is the last step that occurs in PF, leaving the sentence to be phonetically realized as "John blamed himself, and Bill did too." Due to the rules enacted in the LF component of the derivation, although did has phonetically replaced the VP [blame himself], its meaning is the same as what was established at LF. Thus, "Bill did too" can be sloppily interpreted as "Bill blamed himself", as in "Bill blamed Bill".
Interpretative-derived VP approach
In his approach to the sloppy identity problem, Williams (1977) adopts the Derived VP Rule as well. [8] He also suggests that anaphors and pronouns are rewritten as variables at LF by a Variable Rewriting Rule. Afterwards, by using the VP Rule, these variables are then copied into the elided VP. Following this approach, both the sloppy and strict readings are possible. The following examples will go through the derivation of sentence 18.i) as a sloppy reading:
Sloppy reading
18.i) John visits his children on Sunday and Bill does [VP∅] too. [8]
As can be seen in this sentence, the VP contains no structure. In sentence 19.i), the Derived VP Rule, which re-writes the VP using lambda notation, is applied:
Derived VP Rule
19.i) John [VPλx (x visits his children)] and Bill does [VP∅] too. [8]
Next, the Variable Rewriting Rule transforms pronouns and anaphors into variables at LF:
Variable Rewriting Rule
20.i) John [VPλx (x visits x's children)] and Bill does [VP∅] too. [8]
The VP Rule then copies the VP structure into the elided VP:
VP Rule
21.i) John [VPλx (x visits x's children)] and Bill does [VPλx (x visits x's children)] too. [8]
The main difference between the sloppy and the strict reading lies in the Variable Rewriting Rule. The presence of this rule allows for a sloppy reading because variables are bound by the lambda operator within the same VP. By converting the pronoun his in 20.i) into a variable, and once the VP is copied into the elided VP in sentence 21.i), the variable in the elided VP is then able to be bound by Bill. Therefore, in order to derive the strict reading, this step is simply omitted.
Strict Reading
18.ii) John visits his children on Sunday and Bill does [VP∅] too.
The VP is rewritten using lambda notation:
Derived VP Rule
19.ii) John [VPλx (x visits his children)] and Bill does [VP∅] too.
The VP structure is copied into the elided VP:
VP Rule
21.ii) John [VPλx (x visits his children)] and Bill does [VPλx (x visits his children)] too.
Due to the fact the pronoun his is already co-indexed with John, and it was not rewritten as a variable before being copied into the elided VP, there is no way for it to be bound by Bill. Therefore, the strict reading is thus derived by omitting the Variable Rewriting Rule.