
In the theory of computation, a branch of theoretical computer science, a pushdown automaton (PDA) is a type of automaton that employs a stack.
In theoretical computer science and formal language theory, a regular language is a formal language that can be defined by a regular expression, in the strict sense in theoretical computer science.
The star height problem in formal language theory is the question whether all regular languages can be expressed using regular expressions of limited star height, i.e. with a limited nesting depth of Kleene stars. Specifically, is a nesting depth of one always sufficient? If not, is there an algorithm to determine how many are required? The problem was raised by Eggan (1963).
Automata theory is the study of abstract machines and automata, as well as the computational problems that can be solved using them. It is a theory in theoretical computer science. The word automata comes from the Greek word αὐτόματος, which means "self-acting, self-willed, self-moving". An automaton is an abstract self-propelled computing device which follows a predetermined sequence of operations automatically. An automaton with a finite number of states is called a Finite Automaton (FA) or Finite-State Machine (FSM). The figure on the right illustrates a finite-state machine, which is a well-known type of automaton. This automaton consists of states and transitions. As the automaton sees a symbol of input, it makes a transition to another state, according to its transition function, which takes the previous state and current input symbol as its arguments.
In mathematics, a Kleene algebra is an idempotent semiring endowed with a closure operator. It generalizes the operations known from regular expressions.
In abstract algebra, the free monoid on a set is the monoid whose elements are all the finite sequences of zero or more elements from that set, with string concatenation as the monoid operation and with the unique sequence of zero elements, often called the empty string and denoted by ε or λ, as the identity element. The free monoid on a set A is usually denoted A∗. The free semigroup on A is the subsemigroup of A∗ containing all elements except the empty string. It is usually denoted A+.

In the theory of computation, a branch of theoretical computer science, a deterministic finite automaton (DFA)—also known as deterministic finite acceptor (DFA), deterministic finite-state machine (DFSM), or deterministic finite-state automaton (DFSA)—is a finite-state machine that accepts or rejects a given string of symbols, by running through a state sequence uniquely determined by the string. Deterministic refers to the uniqueness of the computation run. In search of the simplest models to capture finite-state machines, Warren McCulloch and Walter Pitts were among the first researchers to introduce a concept similar to finite automata in 1943.
In automata theory, a finite-state machine is called a deterministic finite automaton (DFA), if
The generalized star-height problem in formal language theory is the open question whether all regular languages can be expressed using generalized regular expressions with a limited nesting depth of Kleene stars. Here, generalized regular expressions are defined like regular expressions, but they have a built-in complement operator. For a regular language, its generalized star height is defined as the minimum nesting depth of Kleene stars needed in order to describe the language by means of a generalized regular expression, hence the name of the problem.
A finite-state transducer (FST) is a finite-state machine with two memory tapes, following the terminology for Turing machines: an input tape and an output tape. This contrasts with an ordinary finite-state automaton, which has a single tape. An FST is a type of finite-state automaton (FSA) that maps between two sets of symbols. An FST is more general than an FSA. An FSA defines a formal language by defining a set of accepted strings, while an FST defines relations between sets of strings.
In formal language theory, an alphabet is a non-empty set of symbols/glyphs, typically thought of as representing letters, characters, or digits but among other possibilities the "symbols" could also be a set of phonemes. Alphabets in this technical sense of a set are used in a diverse range of fields including logic, mathematics, computer science, and linguistics. An alphabet may have any cardinality ("size") and depending on its purpose maybe be finite, countable, or even uncountable.
In quantum computing, quantum finite automata (QFA) or quantum state machines are a quantum analog of probabilistic automata or a Markov decision process. They provide a mathematical abstraction of real-world quantum computers. Several types of automata may be defined, including measure-once and measure-many automata. Quantum finite automata can also be understood as the quantization of subshifts of finite type, or as a quantization of Markov chains. QFAs are, in turn, special cases of geometric finite automata or topological finite automata.
In mathematics and theoretical computer science, a semiautomaton is a deterministic finite automaton having inputs but no output. It consists of a set Q of states, a set Σ called the input alphabet, and a function T: Q × Σ → Q called the transition function.
In computer science, more specifically in automata and formal language theory, nested words are a concept proposed by Alur and Madhusudan as a joint generalization of words, as traditionally used for modelling linearly ordered structures, and of ordered unranked trees, as traditionally used for modelling hierarchical structures. Finite-state acceptors for nested words, so-called nested word automata, then give a more expressive generalization of finite automata on words. The linear encodings of languages accepted by finite nested word automata gives the class of visibly pushdown languages. The latter language class lies properly between the regular languages and the deterministic context-free languages. Since their introduction in 2004, these concepts have triggered much research in that area.
In graph theory, the cycle rank of a directed graph is a digraph connectivity measure proposed first by Eggan and Büchi. Intuitively, this concept measures how close a digraph is to a directed acyclic graph (DAG), in the sense that a DAG has cycle rank zero, while a complete digraph of order n with a self-loop at each vertex has cycle rank n. The cycle rank of a directed graph is closely related to the tree-depth of an undirected graph and to the star height of a regular language. It has also found use in sparse matrix computations and logic (Rossman 2008).
In computer science, more precisely in automata theory, a rational set of a monoid is an element of the minimal class of subsets of this monoid that contains all finite subsets and is closed under union, product and Kleene star. Rational sets are useful in automata theory, formal languages and algebra.
In mathematics, a local language is a formal language for which membership of a word in the language can be determined by looking at the first and last symbol and each two-symbol substring of the word. Equivalently, it is a language recognised by a local automaton, a particular kind of deterministic finite automaton.
In theoretical computer science, in particular in formal language theory, Kleene's algorithm transforms a given nondeterministic finite automaton (NFA) into a regular expression. Together with other conversion algorithms, it establishes the equivalence of several description formats for regular languages. Alternative presentations of the same method include the "elimination method" attributed to Brzozowski and McCluskey, the algorithm of McNaughton and Yamada, and the use of Arden's lemma.
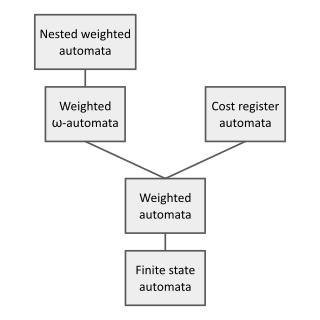
In theoretical computer science and formal language theory, a weighted automaton or weighted finite-state machine is a generalization of a finite-state machine in which the edges have weights, for example real numbers or integers. Finite-state machines are only capable of answering decision problems; they take as input a string and produce a Boolean output, i.e. either "accept" or "reject". In contrast, weighted automata produce a quantitative output, for example a count of how many answers are possible on a given input string, or a probability of how likely the input string is according to a probability distribution. They are one of the simplest studied models of quantitative automata.
In automata theory, an unambiguous finite automaton (UFA) is a nondeterministic finite automaton (NFA) such that each word has at most one accepting path. Each deterministic finite automaton (DFA) is an UFA, but not vice versa. DFA, UFA, and NFA recognize exactly the same class of formal languages. On the one hand, an NFA can be exponentially smaller than an equivalent DFA. On the other hand, some problems are easily solved on DFAs and not on UFAs. For example, given an automaton A, an automaton A′ which accepts the complement of A can be computed in linear time when A is a DFA, it is not known whether it can be done in polynomial time for UFA. Hence UFAs are a mix of the worlds of DFA and of NFA; in some cases, they lead to smaller automata than DFA and quicker algorithms than NFA.













