In computer science, mutual exclusion is a property of concurrency control, which is instituted for the purpose of preventing race conditions. It is the requirement that one thread of execution never enters a critical section while a concurrent thread of execution is already accessing said critical section, which refers to an interval of time during which a thread of execution accesses a shared resource or shared memory.

In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system. In many cases, a thread is a component of a process.

In computer science, a semaphore is a variable or abstract data type used to control access to a common resource by multiple threads and avoid critical section problems in a concurrent system such as a multitasking operating system. Semaphores are a type of synchronization primitive. A trivial semaphore is a plain variable that is changed depending on programmer-defined conditions.
In computer science, a lock or mutex is a synchronization primitive that prevents state from being modified or accessed by multiple threads of execution at once. Locks enforce mutual exclusion concurrency control policies, and with a variety of possible methods there exist multiple unique implementations for different applications.
In software engineering, a spinlock is a lock that causes a thread trying to acquire it to simply wait in a loop ("spin") while repeatedly checking whether the lock is available. Since the thread remains active but is not performing a useful task, the use of such a lock is a kind of busy waiting. Once acquired, spinlocks will usually be held until they are explicitly released, although in some implementations they may be automatically released if the thread being waited on blocks or "goes to sleep".
In computer science, read-copy-update (RCU) is a synchronization mechanism that avoids the use of lock primitives while multiple threads concurrently read and update elements that are linked through pointers and that belong to shared data structures.
Peterson's algorithm is a concurrent programming algorithm for mutual exclusion that allows two or more processes to share a single-use resource without conflict, using only shared memory for communication. It was formulated by Gary L. Peterson in 1981. While Peterson's original formulation worked with only two processes, the algorithm can be generalized for more than two.
In computer science, the test-and-set instruction is an instruction used to write (set) 1 to a memory location and return its old value as a single atomic operation. The caller can then "test" the result to see if the state was changed by the call. If multiple processes may access the same memory location, and if a process is currently performing a test-and-set, no other process may begin another test-and-set until the first process's test-and-set is finished. A central processing unit (CPU) may use a test-and-set instruction offered by another electronic component, such as dual-port RAM; a CPU itself may also offer a test-and-set instruction.
In computer science, an algorithm is called non-blocking if failure or suspension of any thread cannot cause failure or suspension of another thread; for some operations, these algorithms provide a useful alternative to traditional blocking implementations. A non-blocking algorithm is lock-free if there is guaranteed system-wide progress, and wait-free if there is also guaranteed per-thread progress. "Non-blocking" was used as a synonym for "lock-free" in the literature until the introduction of obstruction-freedom in 2003.
In computer science, compare-and-swap (CAS) is an atomic instruction used in multithreading to achieve synchronization. It compares the contents of a memory location with a given value and, only if they are the same, modifies the contents of that memory location to a new given value. This is done as a single atomic operation. The atomicity guarantees that the new value is calculated based on up-to-date information; if the value had been updated by another thread in the meantime, the write would fail. The result of the operation must indicate whether it performed the substitution; this can be done either with a simple boolean response, or by returning the value read from the memory location.
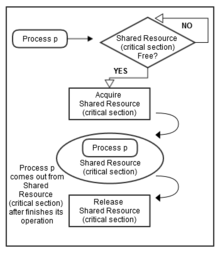
In concurrent programming, concurrent accesses to shared resources can lead to unexpected or erroneous behavior. Thus, the parts of the program where the shared resource is accessed need to be protected in ways that avoid the concurrent access. One way to do so is known as a critical section or critical region. This protected section cannot be entered by more than one process or thread at a time; others are suspended until the first leaves the critical section. Typically, the critical section accesses a shared resource, such as a data structure, peripheral device, or network connection, that would not operate correctly in the context of multiple concurrent accesses.
In computer science, serializing tokens are a concept in concurrency control arising from the ongoing development of DragonFly BSD. According to Matthew Dillon, they are most akin to SPLs, except a token works across multiple CPUs while SPLs only work within a single CPU's domain.
In computing, a memory barrier, also known as a membar, memory fence or fence instruction, is a type of barrier instruction that causes a central processing unit (CPU) or compiler to enforce an ordering constraint on memory operations issued before and after the barrier instruction. This typically means that operations issued prior to the barrier are guaranteed to be performed before operations issued after the barrier.
In concurrent programming, a monitor is a synchronization construct that prevents threads from concurrently accessing a shared object's state and allows them to wait for the state to change. They provide a mechanism for threads to temporarily give up exclusive access in order to wait for some condition to be met, before regaining exclusive access and resuming their task. A monitor consists of a mutex (lock) and at least one condition variable. A condition variable is explicitly 'signalled' when the object's state is modified, temporarily passing the mutex to another thread 'waiting' on the conditional variable.
In computer science, a ticket lock is a synchronization mechanism, or locking algorithm, that is a type of spinlock that uses "tickets" to control which thread of execution is allowed to enter a critical section.
In computer science, the fetch-and-add (FAA) CPU instruction atomically increments the contents of a memory location by a specified value.
Concurrent computing is a form of computing in which several computations are executed concurrently—during overlapping time periods—instead of sequentially—with one completing before the next starts.
In computer science, a readers–writer is a synchronization primitive that solves one of the readers–writers problems. An RW lock allows concurrent access for read-only operations, whereas write operations require exclusive access. This means that multiple threads can read the data in parallel but an exclusive lock is needed for writing or modifying data. When a writer is writing the data, all other writers and readers will be blocked until the writer is finished writing. A common use might be to control access to a data structure in memory that cannot be updated atomically and is invalid until the update is complete.
The Java programming language and the Java virtual machine (JVM) is designed to support concurrent programming. All execution takes place in the context of threads. Objects and resources can be accessed by many separate threads. Each thread has its own path of execution, but can potentially access any object in the program. The programmer must ensure read and write access to objects is properly coordinated between threads. Thread synchronization ensures that objects are modified by only one thread at a time and prevents threads from accessing partially updated objects during modification by another thread. The Java language has built-in constructs to support this coordination.
In computer science, a concurrent data structure is a particular way of storing and organizing data for access by multiple computing threads on a computer.