In a chemical reaction, chemical equilibrium is the state in which both the reactants and products are present in concentrations which have no further tendency to change with time, so that there is no observable change in the properties of the system. This state results when the forward reaction proceeds at the same rate as the reverse reaction. The reaction rates of the forward and backward reactions are generally not zero, but they are equal. Thus, there are no net changes in the concentrations of the reactants and products. Such a state is known as dynamic equilibrium.

In statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is
In particle physics, the Dirac equation is a relativistic wave equation derived by British physicist Paul Dirac in 1928. In its free form, or including electromagnetic interactions, it describes all spin-1⁄2 massive particles, called "Dirac particles", such as electrons and quarks for which parity is a symmetry. It is consistent with both the principles of quantum mechanics and the theory of special relativity, and was the first theory to account fully for special relativity in the context of quantum mechanics. It was validated by accounting for the fine structure of the hydrogen spectrum in a completely rigorous way.

The Navier–Stokes equations are partial differential equations which describe the motion of viscous fluid substances, named after French engineer and physicist Claude-Louis Navier and Anglo-Irish physicist and mathematician George Gabriel Stokes. They were developed over several decades of progressively building the theories, from 1822 (Navier) to 1842-1850 (Stokes).

In physics, the dynamo theory proposes a mechanism by which a celestial body such as Earth or a star generates a magnetic field. The dynamo theory describes the process through which a rotating, convecting, and electrically conducting fluid can maintain a magnetic field over astronomical time scales. A dynamo is thought to be the source of the Earth's magnetic field and the magnetic fields of Mercury and the Jovian planets.
In physics, the Polyakov action is an action of the two-dimensional conformal field theory describing the worldsheet of a string in string theory. It was introduced by Stanley Deser and Bruno Zumino and independently by L. Brink, P. Di Vecchia and P. S. Howe in 1976, and has become associated with Alexander Polyakov after he made use of it in quantizing the string in 1981. The action reads:
Variational Bayesian methods are a family of techniques for approximating intractable integrals arising in Bayesian inference and machine learning. They are typically used in complex statistical models consisting of observed variables as well as unknown parameters and latent variables, with various sorts of relationships among the three types of random variables, as might be described by a graphical model. As typical in Bayesian inference, the parameters and latent variables are grouped together as "unobserved variables". Variational Bayesian methods are primarily used for two purposes:
- To provide an analytical approximation to the posterior probability of the unobserved variables, in order to do statistical inference over these variables.
- To derive a lower bound for the marginal likelihood of the observed data. This is typically used for performing model selection, the general idea being that a higher marginal likelihood for a given model indicates a better fit of the data by that model and hence a greater probability that the model in question was the one that generated the data.
In thermodynamics, an activity coefficient is a factor used to account for deviation of a mixture of chemical substances from ideal behaviour. In an ideal mixture, the microscopic interactions between each pair of chemical species are the same and, as a result, properties of the mixtures can be expressed directly in terms of simple concentrations or partial pressures of the substances present e.g. Raoult's law. Deviations from ideality are accommodated by modifying the concentration by an activity coefficient. Analogously, expressions involving gases can be adjusted for non-ideality by scaling partial pressures by a fugacity coefficient.
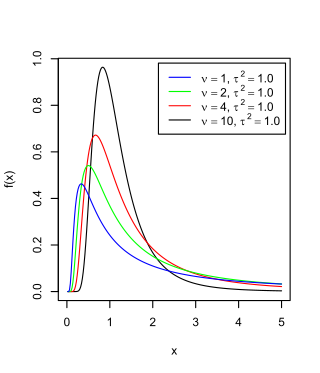
The scaled inverse chi-squared distribution is the distribution for x = 1/s2, where s2 is a sample mean of the squares of ν independent normal random variables that have mean 0 and inverse variance 1/σ2 = τ2. The distribution is therefore parametrised by the two quantities ν and τ2, referred to as the number of chi-squared degrees of freedom and the scaling parameter, respectively.

The Pearson distribution is a family of continuous probability distributions. It was first published by Karl Pearson in 1895 and subsequently extended by him in 1901 and 1916 in a series of articles on biostatistics.
Plasma parameters define various characteristics of a plasma, an electrically conductive collection of charged particles that responds collectively to electromagnetic forces. Plasma typically takes the form of neutral gas-like clouds or charged ion beams, but may also include dust and grains. The behaviour of such particle systems can be studied statistically.
In statistics, stochastic volatility models are those in which the variance of a stochastic process is itself randomly distributed. They are used in the field of mathematical finance to evaluate derivative securities, such as options. The name derives from the models' treatment of the underlying security's volatility as a random process, governed by state variables such as the price level of the underlying security, the tendency of volatility to revert to some long-run mean value, and the variance of the volatility process itself, among others.
Collision frequency describes the rate of collisions between two atomic or molecular species in a given volume, per unit time. In an ideal gas, assuming that the species behave like hard spheres, the collision frequency between entities of species A and species B is:

In statistical thermodynamics, the UNIFAC method is a semi-empirical system for the prediction of non-electrolyte activity in non-ideal mixtures. UNIFAC uses the functional groups present on the molecules that make up the liquid mixture to calculate activity coefficients. By using interactions for each of the functional groups present on the molecules, as well as some binary interaction coefficients, the activity of each of the solutions can be calculated. This information can be used to obtain information on liquid equilibria, which is useful in many thermodynamic calculations, such as chemical reactor design, and distillation calculations.

The viscosity of a fluid is a measure of its resistance to deformation at a given rate. For liquids, it corresponds to the informal concept of "thickness": for example, syrup has a higher viscosity than water.
Chapman–Enskog theory provides a framework in which equations of hydrodynamics for a gas can be derived from the Boltzmann equation. The technique justifies the otherwise phenomenological constitutive relations appearing in hydrodynamical descriptions such as the Navier–Stokes equations. In doing so, expressions for various transport coefficients such as thermal conductivity and viscosity are obtained in terms of molecular parameters. Thus, Chapman–Enskog theory constitutes an important step in the passage from a microscopic, particle-based description to a continuum hydrodynamical one.
In statistics and probability theory, the nonparametric skew is a statistic occasionally used with random variables that take real values. It is a measure of the skewness of a random variable's distribution—that is, the distribution's tendency to "lean" to one side or the other of the mean. Its calculation does not require any knowledge of the form of the underlying distribution—hence the name nonparametric. It has some desirable properties: it is zero for any symmetric distribution; it is unaffected by a scale shift; and it reveals either left- or right-skewness equally well. In some statistical samples it has been shown to be less powerful than the usual measures of skewness in detecting departures of the population from normality.
In statistics, the variance function is a smooth function which depicts the variance of a random quantity as a function of its mean. The variance function is a measure of heteroscedasticity and plays a large role in many settings of statistical modelling. It is a main ingredient in the generalized linear model framework and a tool used in non-parametric regression, semiparametric regression and functional data analysis. In parametric modeling, variance functions take on a parametric form and explicitly describe the relationship between the variance and the mean of a random quantity. In a non-parametric setting, the variance function is assumed to be a smooth function.
The shear viscosity of a fluid is a material property that describes the friction between internal neighboring fluid surfaces flowing with different fluid velocities. This friction is the effect of (linear) momentum exchange caused by molecules with sufficient energy to move between these fluid sheets due to fluctuations in their motion. The viscosity is not a material constant, but a material property that depends on temperature, pressure, fluid mixture composition, local velocity variations. This functional relationship is described by a mathematical viscosity model called a constitutive equation which is usually far more complex than the defining equation of shear viscosity. One such complicating feature is the relation between the viscosity model for a pure fluid and the model for a fluid mixture which is called mixing rules. When scientists and engineers use new arguments or theories to develop a new viscosity model, instead of improving the reigning model, it may lead to the first model in a new class of models. This article will display one or two representative models for different classes of viscosity models, and these classes are:
In probability theory, a log-t distribution or log-Student t distribution is a probability distribution of a random variable whose logarithm is distributed in accordance with a Student's t-distribution. If X is a random variable with a Student's t-distribution, then Y = exp(X) has a log-t distribution; likewise, if Y has a log-t distribution, then X = log(Y) has a Student's t-distribution.










































