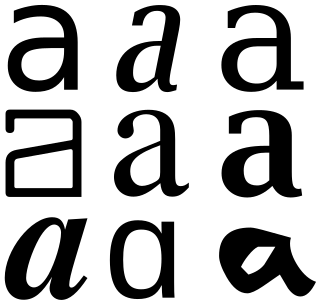
In linguistics, a grapheme is the smallest functional unit of a writing system. The word grapheme is derived from Ancient Greek γράφω (gráphō) 'write' and the suffix -eme by analogy with phoneme and other names of emic units. The study of graphemes is called graphemics. The concept of graphemes is abstract and similar to the notion in computing of a character. By comparison, a specific shape that represents any particular grapheme in a given typeface is called a glyph.
The Coptic script is the script used for writing the Coptic language, the latest stage of Egyptian. The repertoire of glyphs is based on the uncial Greek alphabet, augmented by letters borrowed from the Egyptian Demotic. It was the first alphabetic script used for the Egyptian language. There are several Coptic alphabets, as the script varies greatly among the various dialects and eras of the Coptic language.

Phi is the twenty-first letter of the Greek alphabet.
Ø is a letter used in the Danish, Norwegian, Faroese, and Southern Sámi languages. It is mostly used as to represent the mid front rounded vowels, such as and, except for Southern Sámi where it is used as an diphthong.
An internationalized domain name (IDN) is an Internet domain name that contains at least one label displayed in software applications, in whole or in part, in non-Latin script or alphabet or in the Latin alphabet-based characters with diacritics or ligatures. These writing systems are encoded by computers in multibyte Unicode. Internationalized domain names are stored in the Domain Name System (DNS) as ASCII strings using Punycode transcription.

The palochka or palotchka is a letter in the Cyrillic script. The letter is usually caseless. It was introduced in the late 1930s as the Hindu-Arabic digit '1', and on Cyrillic keyboards, it is usually typeset as the Roman numeral 'I'. Unicode currently supports both caseless/capital palochka at U+04C0 and a rarer lower-case palochka at U+04CF.

Letter case is the distinction between the letters that are in larger uppercase or capitals and smaller lowercase in the written representation of certain languages. The writing systems that distinguish between the upper- and lowercase have two parallel sets of letters: each in the majuscule set has a counterpart in the minuscule set. Some counterpart letters have the same shape, and differ only in size, but for others the shapes are different. The two case variants are alternative representations of the same letter: they have the same name and pronunciation and are typically treated identically when sorting in alphabetical order.
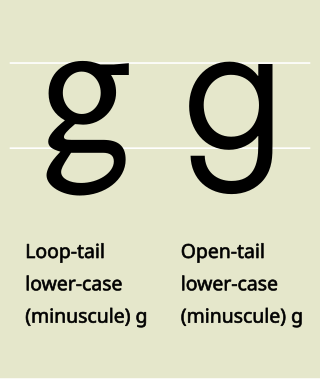
In graphemics and typography, the term allograph is used of a glyph that is a design variant of a letter or other grapheme, such as a letter, a number, an ideograph, a punctuation mark or other typographic symbol. In graphemics, an obvious example in English is the distinction between uppercase and lowercase letters. Allographs can vary greatly, without affecting the underlying identity of the grapheme. Even if the word "cat" is rendered as "cAt", it remains recognizable as the sequence of the three graphemes ⟨c⟩, ⟨a⟩, ⟨t⟩.
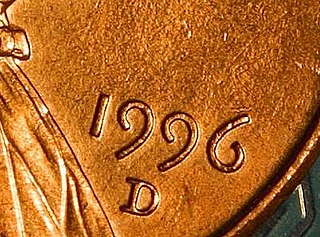
Text figures are numerals designed with varying heights in a fashion that resembles a typical line of running text, hence the name. They are contrasted with lining figures, which are the same height as upper-case letters. Georgia is an example of a popular typeface that employs text figures by default.
Nameprep is the process of case-folding a string to lowercase and removal of some generally invisible code points before it is suitable to represent a domain name, or other such canonical name. It is used by the Internationalizing Domain Names in Applications (IDNA) standard, using the Unicode standard for NFKC normalization.

The dotted or slashed zero 0̷ is a representation of the Arabic digit "0" (zero) with a slash through it. The slashed zero glyph is often used to distinguish the digit "zero" ("0") from the Latin script letter "O" anywhere that the distinction needs emphasis, particularly in encoding systems, scientific and engineering applications, computer programming, and telecommunications. It thus helps to differentiate characters that would otherwise be homoglyphs. It was commonly used during the punch card era, when programs were typically written out by hand, to avoid ambiguity when the character was later typed on a card punch.
The internationalized domain name (IDN) homograph attack is a way a malicious party may deceive computer users about what remote system they are communicating with, by exploiting the fact that many different characters look alike
Unicode has a certain amount of duplication of characters. These are pairs of single Unicode code points that are canonically equivalent. The reason for this are compatibility issues with legacy systems.
L, or l, is the twelfth letter in the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is el, plural els.
Unicode equivalence is the specification by the Unicode character encoding standard that some sequences of code points represent essentially the same character. This feature was introduced in the standard to allow compatibility with preexisting standard character sets, which often included similar or identical characters.

The Unicode Consortium and the ISO/IEC JTC 1/SC 2/WG 2 jointly collaborate on the list of the characters in the Universal Coded Character Set. The Universal Coded Character Set, most commonly called the Universal Character Set, is an international standard to map characters, discrete symbols used in natural language, mathematics, music, and other domains, to unique machine-readable data values. By creating this mapping, the UCS enables computer software vendors to interoperate, and transmit—interchange—UCS-encoded text strings from one to another. Because it is a universal map, it can be used to represent multiple languages at the same time. This avoids the confusion of using multiple legacy character encodings, which can result in the same sequence of codes having multiple interpretations depending on the character encoding in use, resulting in mojibake if the wrong one is chosen.
A numeral is a character that denotes a number. The decimal number digits 0–9 are used widely in various writing systems throughout the world, however the graphemes representing the decimal digits differ widely. Therefore Unicode includes 22 different sets of graphemes for the decimal digits, and also various decimal points, thousands separators, negative signs, etc. Unicode also includes several non-decimal numerals such as Aegean numerals, Roman numerals, counting rod numerals, Mayan numerals, Cuneiform numerals and ancient Greek numerals. There is also a large number of typographical variations of the Western Arabic numerals provided for specialized mathematical use and for compatibility with earlier character sets, such as ² or ②, and composite characters such as ½.

A subscript or superscript is a character that is set slightly below or above the normal line of type, respectively. It is usually smaller than the rest of the text. Subscripts appear at or below the baseline, while superscripts are above. Subscripts and superscripts are perhaps most often used in formulas, mathematical expressions, and specifications of chemical compounds and isotopes, but have many other uses as well.
The Unicode Standard assigns various properties to each Unicode character and code point.
A typographic approximation is a replacement of an element of the writing system with another glyph or glyphs. The replacement may be a nearly homographic character, a digraph, or a character string. An approximation is different from a typographical error in that an approximation is intentional and aims to preserve the visual appearance of the original. The concept of approximation also applies to the World Wide Web and other forms of textual information available via digital media, though usually at the level of characters, not glyphs.




