More efficient algorithms
There are algorithms that are more efficient than the O(n3) dynamic programming algorithm, though they are more complex.
Hu & Shing
An algorithm published by Hu and Shing achieves O(n log n) computational complexity. [3] [4] [5] They showed how the matrix chain multiplication problem can be transformed (or reduced) into the problem of triangulation of a regular polygon. The polygon is oriented such that there is a horizontal bottom side, called the base, which represents the final result. The other n sides of the polygon, in the clockwise direction, represent the matrices. The vertices on each end of a side are the dimensions of the matrix represented by that side. With n matrices in the multiplication chain there are n−1 binary operations and Cn−1 ways of placing parentheses, where Cn−1 is the (n−1)-th Catalan number. The algorithm exploits that there are also Cn−1 possible triangulations of a polygon with n+1 sides.
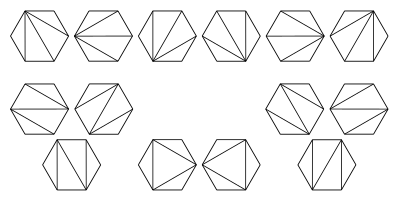
This image illustrates possible triangulations of a regular hexagon. These correspond to the different ways that parentheses can be placed to order the multiplications for a product of 5 matrices.
For the example below, there are four sides: A, B, C and the final result ABC. A is a 10×30 matrix, B is a 30×5 matrix, C is a 5×60 matrix, and the final result is a 10×60 matrix. The regular polygon for this example is a 4-gon, i.e. a square:

The matrix product AB is a 10x5 matrix and BC is a 30x60 matrix. The two possible triangulations in this example are:
 Polygon representation of (AB)C
Polygon representation of (AB)C Polygon representation of A(BC)
Polygon representation of A(BC)


The cost of a single triangle in terms of the number of multiplications needed is the product of its vertices. The total cost of a particular triangulation of the polygon is the sum of the costs of all its triangles:
- (AB)C: (10×30×5) + (10×5×60) = 1500 + 3000 = 4500 multiplications
- A(BC): (30×5×60) + (10×30×60) = 9000 + 18000 = 27000 multiplications
Hu & Shing developed an algorithm that finds an optimum solution for the minimum cost partition problem in O(n log n) time. Their proof of correctness of the algorithm relies on "Lemma 1" proved in a 1981 technical report and omitted from the published paper. [6] [4] The technical report's proof of the lemma is incorrect, but Shing has presented a corrected proof. [1]
Other O(n log n) algorithms
Wang, Zhu and Tian have published a simplified O(n log m) algorithm, where n is the number of matrices in the chain and m is the number of local minimums in the dimension sequence of the given matrix chain. [7]
Nimbark, Gohel, and Doshi have published a greedy O(n log n) algorithm, [8] but their proof of optimality is incorrect and their algorithm fails to produce the most efficient parentheses assignment for some matrix chains. [1]
Chin-Hu-Shing approximate solution
An algorithm created independently by Chin [9] and Hu & Shing [10] runs in O(n) and produces a parenthesization which is at most 15.47% worse than the optimal choice. In most cases the algorithm yields the optimal solution or a solution which is only 1-2 percent worse than the optimal one. [5]
The algorithm starts by translating the problem to the polygon partitioning problem. To each vertex V of the polygon is associated a weight w. Suppose we have three consecutive vertices , and that is the vertex with minimum weight . We look at the quadrilateral with vertices (in clockwise order). We can triangulate it in two ways:




- and , with cost
- and with cost .






Therefore, if

or equivalently

we remove the vertex from the polygon and add the side to the triangulation. We repeat this process until no satisfies the condition above. For all the remaining vertices , we add the side to the triangulation. This gives us a nearly optimal triangulation.








