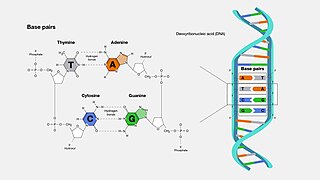
A base pair (bp) is a fundamental unit of double-stranded nucleic acids consisting of two nucleobases bound to each other by hydrogen bonds. They form the building blocks of the DNA double helix and contribute to the folded structure of both DNA and RNA. Dictated by specific hydrogen bonding patterns, "Watson–Crick" base pairs allow the DNA helix to maintain a regular helical structure that is subtly dependent on its nucleotide sequence. The complementary nature of this based-paired structure provides a redundant copy of the genetic information encoded within each strand of DNA. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA and RNA polymerase transcribes DNA into RNA. Many DNA-binding proteins can recognize specific base-pairing patterns that identify particular regulatory regions of genes.

Deoxyribonucleic acid is a polymer composed of two polynucleotide chains that coil around each other to form a double helix. The polymer carries genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses. DNA and ribonucleic acid (RNA) are nucleic acids. Alongside proteins, lipids and complex carbohydrates (polysaccharides), nucleic acids are one of the four major types of macromolecules that are essential for all known forms of life.

Nucleic acids are large biomolecules that are crucial in all cells and viruses. They are composed of nucleotides, which are the monomer components: a 5-carbon sugar, a phosphate group and a nitrogenous base. The two main classes of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). If the sugar is ribose, the polymer is RNA; if the sugar is deoxyribose, a variant of ribose, the polymer is DNA.
DNA topoisomerases are enzymes that catalyze changes in the topological state of DNA, interconverting relaxed and supercoiled forms, linked (catenated) and unlinked species, and knotted and unknotted DNA. Topological issues in DNA arise due to the intertwined nature of its double-helical structure, which, for example, can lead to overwinding of the DNA duplex during DNA replication and transcription. If left unchanged, this torsion would eventually stop the DNA or RNA polymerases involved in these processes from continuing along the DNA helix. A second topological challenge results from the linking or tangling of DNA during replication. Left unresolved, links between replicated DNA will impede cell division. The DNA topoisomerases prevent and correct these types of topological problems. They do this by binding to DNA and cutting the sugar-phosphate backbone of either one or both of the DNA strands. This transient break allows the DNA to be untangled or unwound, and, at the end of these processes, the DNA backbone is resealed. Since the overall chemical composition and connectivity of the DNA do not change, the DNA substrate and product are chemical isomers, differing only in their topology.

Chargaff's rules state that in the DNA of any species and any organism, the amount of guanine should be equal to the amount of cytosine and the amount of adenine should be equal to the amount of thymine. Further, a 1:1 stoichiometric ratio of purine and pyrimidine bases should exist. This pattern is found in both strands of the DNA. They were discovered by Austrian-born chemist Erwin Chargaff in the late 1940s.

A Hoogsteen base pair is a variation of base-pairing in nucleic acids such as the A•T pair. In this manner, two nucleobases, one on each strand, can be held together by hydrogen bonds in the major groove. A Hoogsteen base pair applies the N7 position of the purine base and C6 amino group, which bind the Watson–Crick (N3–C4) face of the pyrimidine base.

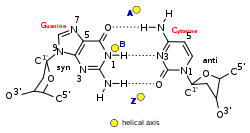
Triple-stranded DNA is a DNA structure in which three oligonucleotides wind around each other and form a triple helix. In triple-stranded DNA, the third strand binds to a B-form DNA double helix by forming Hoogsteen base pairs or reversed Hoogsteen hydrogen bonds.

"Molecular Structure of Nucleic Acids: A Structure for Deoxyribose Nucleic Acid" was the first article published to describe the discovery of the double helix structure of DNA, using X-ray diffraction and the mathematics of a helix transform. It was published by Francis Crick and James D. Watson in the scientific journal Nature on pages 737–738 of its 171st volume.
The history of molecular biology begins in the 1930s with the convergence of various, previously distinct biological and physical disciplines: biochemistry, genetics, microbiology, virology and physics. With the hope of understanding life at its most fundamental level, numerous physicists and chemists also took an interest in what would become molecular biology.

DNA supercoiling refers to the amount of twist in a particular DNA strand, which determines the amount of strain on it. A given strand may be "positively supercoiled" or "negatively supercoiled". The amount of a strand's supercoiling affects a number of biological processes, such as compacting DNA and regulating access to the genetic code. Certain enzymes, such as topoisomerases, change the amount of DNA supercoiling to facilitate functions such as DNA replication and transcription. The amount of supercoiling in a given strand is described by a mathematical formula that compares it to a reference state known as "relaxed B-form" DNA.
Nucleic acid thermodynamics is the study of how temperature affects the nucleic acid structure of double-stranded DNA (dsDNA). The melting temperature (Tm) is defined as the temperature at which half of the DNA strands are in the random coil or single-stranded (ssDNA) state. Tm depends on the length of the DNA molecule and its specific nucleotide sequence. DNA, when in a state where its two strands are dissociated, is referred to as having been denatured by the high temperature.

A-DNA is one of the possible double helical structures which DNA can adopt. A-DNA is thought to be one of three biologically active double helical structures along with B-DNA and Z-DNA. It is a right-handed double helix fairly similar to the more common B-DNA form, but with a shorter, more compact helical structure whose base pairs are not perpendicular to the helix-axis as in B-DNA. It was discovered by Rosalind Franklin, who also named the A and B forms. She showed that DNA is driven into the A form when under dehydrating conditions. Such conditions are commonly used to form crystals, and many DNA crystal structures are in the A form. The same helical conformation occurs in double-stranded RNAs, and in DNA-RNA hybrid double helices.

Molecular models of DNA structures are representations of the molecular geometry and topology of deoxyribonucleic acid (DNA) molecules using one of several means, with the aim of simplifying and presenting the essential, physical and chemical, properties of DNA molecular structures either in vivo or in vitro. These representations include closely packed spheres made of plastic, metal wires for skeletal models, graphic computations and animations by computers, artistic rendering. Computer molecular models also allow animations and molecular dynamics simulations that are very important for understanding how DNA functions in vivo.
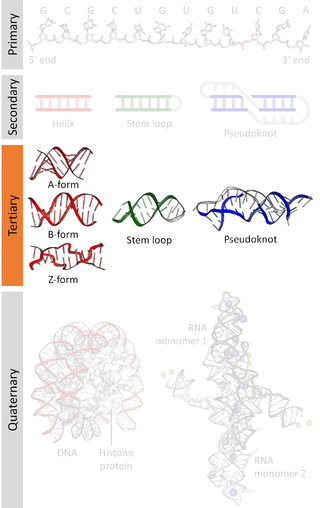
Nucleic acid tertiary structure is the three-dimensional shape of a nucleic acid polymer. RNA and DNA molecules are capable of diverse functions ranging from molecular recognition to catalysis. Such functions require a precise three-dimensional structure. While such structures are diverse and seemingly complex, they are composed of recurring, easily recognizable tertiary structural motifs that serve as molecular building blocks. Some of the most common motifs for RNA and DNA tertiary structure are described below, but this information is based on a limited number of solved structures. Many more tertiary structural motifs will be revealed as new RNA and DNA molecules are structurally characterized.

Nucleic acid structure refers to the structure of nucleic acids such as DNA and RNA. Chemically speaking, DNA and RNA are very similar. Nucleic acid structure is often divided into four different levels: primary, secondary, tertiary, and quaternary.

Nucleic acid secondary structure is the basepairing interactions within a single nucleic acid polymer or between two polymers. It can be represented as a list of bases which are paired in a nucleic acid molecule. The secondary structures of biological DNAs and RNAs tend to be different: biological DNA mostly exists as fully base paired double helices, while biological RNA is single stranded and often forms complex and intricate base-pairing interactions due to its increased ability to form hydrogen bonds stemming from the extra hydroxyl group in the ribose sugar.

In the fields of geometry and biochemistry, a triple helix is a set of three congruent geometrical helices with the same axis, differing by a translation along the axis. This means that each of the helices keeps the same distance from the central axis. As with a single helix, a triple helix may be characterized by its pitch, diameter, and handedness. Examples of triple helices include triplex DNA, triplex RNA, the collagen helix, and collagen-like proteins.
Nucleic acid NMR is the use of nuclear magnetic resonance spectroscopy to obtain information about the structure and dynamics of nucleic acid molecules, such as DNA or RNA. It is useful for molecules of up to 100 nucleotides, and as of 2003, nearly half of all known RNA structures had been determined by NMR spectroscopy.

In addition to the variety of verified DNA structures, there have been a range of proposed DNA models that have either been disproven, or lack evidence.
Non-canonical base pairs are planar hydrogen bonded pairs of nucleobases, having hydrogen bonding patterns which differ from the patterns observed in Watson-Crick base pairs, as in the classic double helical DNA. The structures of polynucleotide strands of both DNA and RNA molecules can be understood in terms of sugar-phosphate backbones consisting of phosphodiester-linked D 2’ deoxyribofuranose sugar moieties, with purine or pyrimidine nucleobases covalently linked to them. Here, the N9 atoms of the purines, guanine and adenine, and the N1 atoms of the pyrimidines, cytosine and thymine, respectively, form glycosidic linkages with the C1’ atom of the sugars. These nucleobases can be schematically represented as triangles with one of their vertices linked to the sugar, and the three sides accounting for three edges through which they can form hydrogen bonds with other moieties, including with other nucleobases. The side opposite to the sugar linked vertex is traditionally called the Watson-Crick edge, since they are involved in forming the Watson-Crick base pairs which constitute building blocks of double helical DNA. The two sides adjacent to the sugar-linked vertex are referred to, respectively, as the Sugar and Hoogsteen edges.